






















































Creating DataFrames
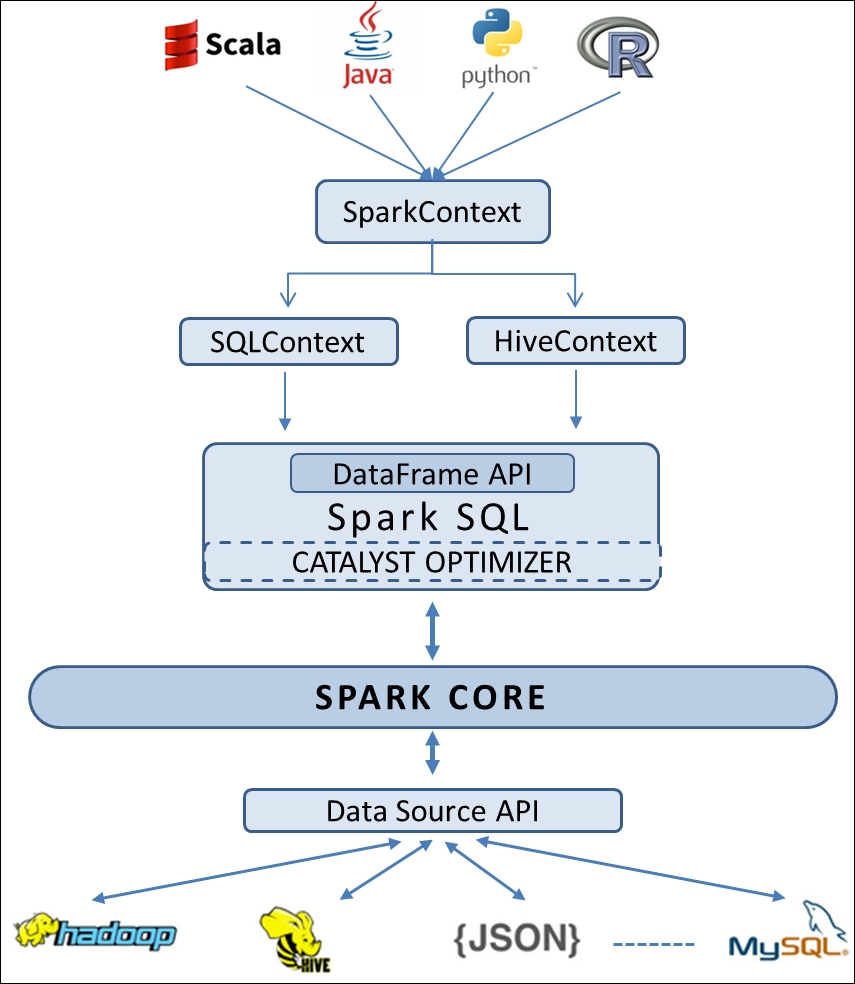
Spark DataFrame creation is similar to RDD creation. To get access to the DataFrame API, you need SQLContext or HiveContext as an entry point. In this section, we are going to demonstrate how to create DataFrames from various data sources, starting from basic code examples with in-memory collections:
Creating DataFrames from RDDs
The following code creates an RDD from a list of colors followed by a collection of tuples containing the color name and its length. It creates a DataFrame using the toDF method to convert the RDD into a DataFrame. The toDF method takes a list of column labels as an optional argument:
Python:
//Create a list of colours
>>> colors = ['white','green','yellow','red','brown','pink']
//Distribute a local collection to form an RDD
//Apply map function on that RDD to get another RDD containing colour, length tuples
>>> color_df = sc.parallelize(colors)
.map(lambda x:(x,len(x))).toDF(["color","length"])
>>>...

