






















































We are thankful for the iris dataset, but as you might recall, it has only 150 observations. To make the most out of the set, we will employ cross-validation. Additionally, in the last section, we wanted to compare the performance of two different classifiers, support vector classifier and logistic regression. Cross-validation will help us with this comparison issue as well.
Introducing cross-validation
Getting ready
Suppose we wanted to choose between the support vector classifier and the logistic regression classifier. We cannot measure their performance on the unavailable test set.
What if, instead, we:
- Forgot about the test set for now?
- Split the training set into two parts, one to train on and one to test the training?
Split the training set into two parts using the train_test_split function used in previous sections:
from sklearn.model_selection import train_test_split
X_train_2, X_test_2, y_train_2, y_test_2 = train_test_split(X_train, y_train, test_size=0.25, random_state=1)
X_train_2 consists of 75% of the X_train data, while X_test_2 is the remaining 25%. y_train_2 is 75% of the target data, and matches the observations of X_train_2. y_test_2 is 25% of the target data present in y_train.
As you might have expected, you have to use these new splits to choose between the two models: SVC and logistic regression. Do so by writing a predictive program.
How to do it...
- Start with all the imports and load the iris dataset:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
#load the classifying models
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
iris = datasets.load_iris()
X = iris.data[:, :2] #load the first two features of the iris data
y = iris.target #load the target of the iris data
#split the whole set one time
#Note random state is 7 now
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=7)
#split the training set into parts
X_train_2, X_test_2, y_train_2, y_test_2 = train_test_split(X_train, y_train, test_size=0.25, random_state=7)
- Create an instance of an SVC classifier and fit it:
svc_clf = SVC(kernel = 'linear',random_state = 7)
svc_clf.fit(X_train_2, y_train_2)
- Do the same for logistic regression (both lines for logistic regression are compressed into one):
lr_clf = LogisticRegression(random_state = 7).fit(X_train_2, y_train_2)
- Now predict and examine the SVC and logistic regression's performance on X_test_2:
svc_pred = svc_clf.predict(X_test_2)
lr_pred = lr_clf.predict(X_test_2)
print "Accuracy of SVC:",accuracy_score(y_test_2,svc_pred)
print "Accuracy of LR:",accuracy_score(y_test_2,lr_pred)
Accuracy of SVC: 0.857142857143
Accuracy of LR: 0.714285714286
- The SVC performs better, but we have not yet seen the original test data. Choose SVC over logistic regression and try it on the original test set:
print "Accuracy of SVC on original Test Set: ",accuracy_score(y_test, svc_clf.predict(X_test))
Accuracy of SVC on original Test Set: 0.684210526316
How it works...
In comparing the SVC and logistic regression classifier, you might wonder (and be a little suspicious) about a lot of scores being very different. The final test on SVC scored lower than logistic regression. To help with this situation, we can do cross-validation in scikit-learn.
Cross-validation involves splitting the training set into parts, as we did before. To match the preceding example, we split the training set into four parts, or folds. We are going to design a cross-validation iteration by taking turns with one of the four folds for testing and the other three for training. It is the same split as done before four times over with the same set, thereby rotating, in a sense, the test set:
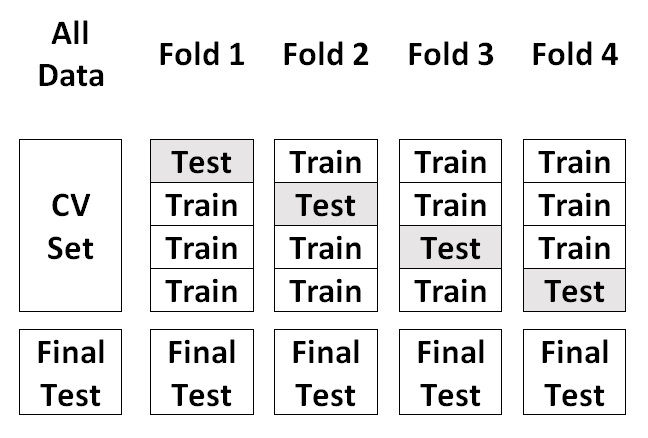
With scikit-learn, this is relatively easy to accomplish:
- We start with an import:
from sklearn.model_selection import cross_val_score
- Then we produce an accuracy score on four folds:
svc_scores = cross_val_score(svc_clf, X_train, y_train, cv=4)
svc_scores
array([ 0.82758621, 0.85714286, 0.92857143, 0.77777778])
- We can find the mean for average performance and standard deviation for a measure of spread of all scores relative to the mean:
print "Average SVC scores: ", svc_scores.mean()
print "Standard Deviation of SVC scores: ", svc_scores.std()
Average SVC scores: 0.847769567597
Standard Deviation of SVC scores: 0.0545962864696
- Similarly, with the logistic regression instance, we compute four scores:
lr_scores = cross_val_score(lr_clf, X_train, y_train, cv=4)
print "Average SVC scores: ", lr_scores.mean()
print "Standard Deviation of SVC scores: ", lr_scores.std()
Average SVC scores: 0.748893906221
Standard Deviation of SVC scores: 0.0485633168699
Now we have many scores, which confirms our selection of SVC over logistic regression. Thanks to cross-validation, we used the training multiple times and had four small test sets within it to score our model.
Note that our model is a bigger model that consists of:
- Training an SVM through cross-validation
- Training a logistic regression through cross-validation
- Choosing between SVM and logistic regression
The choice at the end is part of the model.
There's more...
Despite our hard work and the elegance of the scikit-learn syntax, the score on the test set at the very end remains suspicious. The reason for this is that the test and train split are not necessarily balanced; the train and test sets do not necessarily have similar proportions of all the classes.
This is easily remedied by using a stratified test-train split:
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y)
By selecting the target set as the stratified argument, the target classes are balanced. This brings the SVC scores closer together.
svc_scores = cross_val_score(svc_clf, X_train, y_train, cv=4)
print "Average SVC scores: " , svc_scores.mean()
print "Standard Deviation of SVC scores: ", svc_scores.std()
print "Score on Final Test Set:", accuracy_score(y_test, svc_clf.predict(X_test))
Average SVC scores: 0.831547619048
Standard Deviation of SVC scores: 0.0792488953372
Score on Final Test Set: 0.789473684211
Additionally, note that in the preceding example, the cross-validation procedure produces stratified folds by default:
from sklearn.model_selection import cross_val_score
svc_scores = cross_val_score(svc_clf, X_train, y_train, cv = 4)
The preceding code is equivalent to:
from sklearn.model_selection import cross_val_score, StratifiedKFold
skf = StratifiedKFold(n_splits = 4)
svc_scores = cross_val_score(svc_clf, X_train, y_train, cv = skf)






















