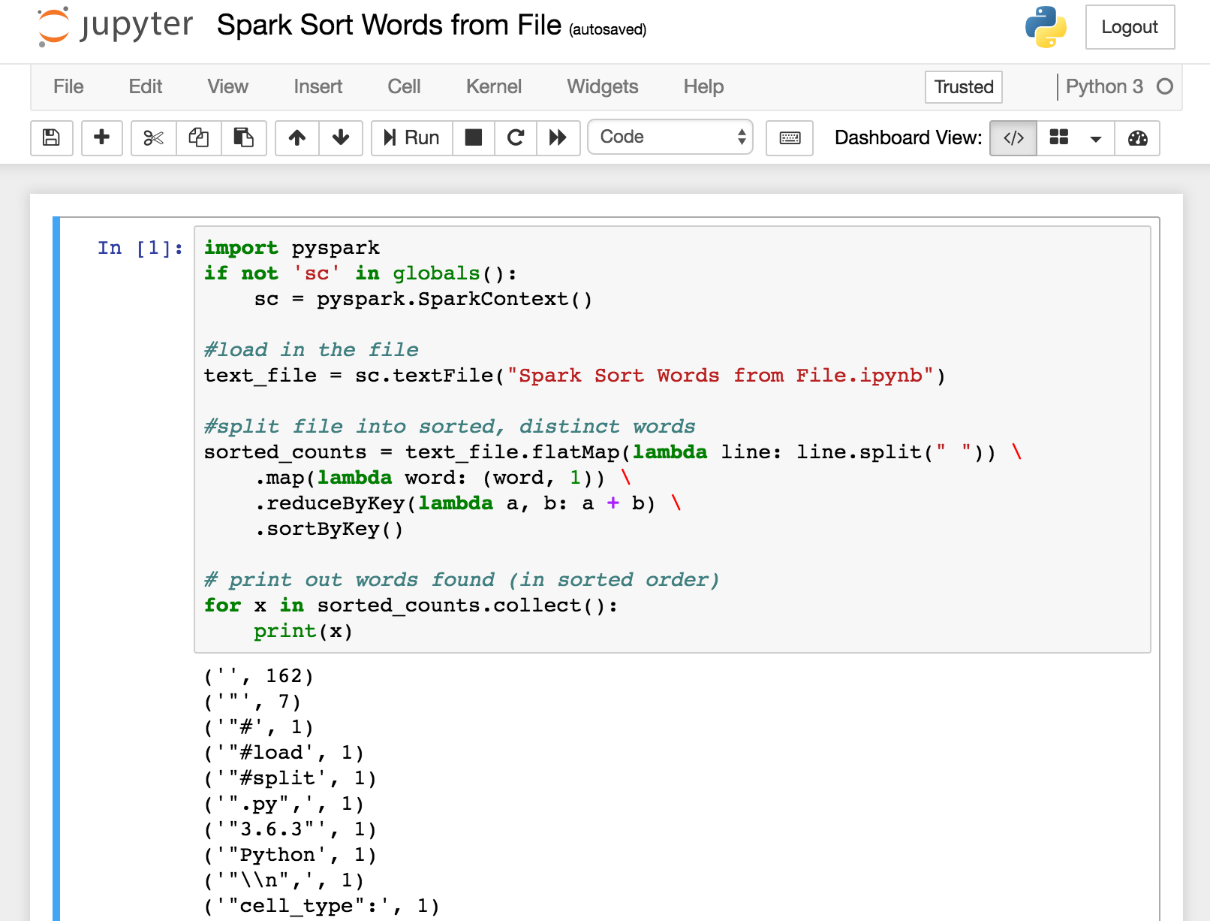
Sorted word count
Using the same script with a minor modification, we can make one more call and sort the results. The script now looks as follows:
import pyspark
if not 'sc' in globals():
sc = pyspark.SparkContext()
#load in the file
text_file = sc.textFile("Spark Sort Words from File.ipynb")
#split file into sorted, distinct words
sorted_counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b) \
.sortByKey()
# print out words found (in sorted order)
for x in sorted_counts.collect():
print(x)Here, we have added another function call to RDD creation, sortByKey(). So, after we have mapped/reduced, and arrived at a list of words and occurrences, we can then easily sort the results.
The resultning output looks like this: