






















































Overview of memory management
Modern computers are designed to store and retrieve data during application runtimes. Every modern device or computer is designed to allow one or more applications to run while reading and writing supporting data. Data can be stored either long-term or short-term. For long-term storage, we use storage media such as hard disks. This is what we call non-volatile storage. If the device loses power, the data remains and can be reused later, but this type of storage is not optimized for high-speed situations.
Outside of data needed for extended periods, applications must also store data between processes. Data is constantly being written, read, and removed as an application performs various operations. This data type is best stored in volatile storage or memory caches and arrays. In this situation, the data is lost when the device loses power, but data is read and written at a very high speed while in use.
One practical example where it’s better to use volatile memory instead of non-volatile memory for performance reasons is cache memory in computer systems. Cache memory is a small, fast type of volatile memory that stores frequently accessed data and instructions to speed up processing. It’s typically faster than accessing data from non-volatile memory, such as hard disk drives (HDDs) or solid-state drives (SSDs). When a processor needs to access data, it first checks the cache memory. If the data is in the cache (cache hit), the processor can retrieve it quickly, resulting in faster overall performance. However, if the data is not in the cache (cache miss), the processor needs to access it from slower, non-volatile memory, causing a delay in processing.
In this scenario, using volatile memory (cache memory) instead of non-volatile memory (HDDs or SSDs) improves performance because volatile memory offers much faster access times. This is especially critical in systems where latency is a concern, such as high-performance computing, gaming, and real-time processing applications. Overall, leveraging volatile memory helps reduce the time it takes to access frequently used data, enhancing system performance and responsiveness.
Memory is a general name given to an array of rapidly available information shared by the CPU and connected devices. Programs and information use up this memory while the processor carries out operations. The processor moves instructions and information in and out of the processor very quickly. This is why caches (at the CPU level) and Random Access Memory (RAM) are the storage locations immediately used during processes. CPUs have three cache levels: L1, L2, and L3. L1 is the fastest, but it has low storage capacity, and with each higher level, there is more space at the expense of speed. They are closest to the CPU for temporary storage and high-speed access. Figure 1.1 depicts the layout of the different cache levels.
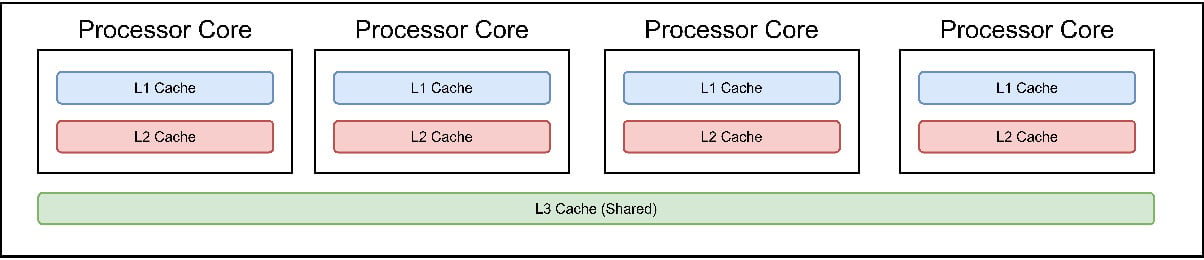
Figure 1.1 – The different cache levels in a CPU and per CPU core
Each processor core contains space for L1 and L2 caches, which allow each core to complete small tasks as quickly as possible. For less frequent tasks that might be shared across cores, the L3 cache is used and is shared between the cores of the CPU.
Memory management, in principle, is a broad-brush expression that refers to techniques used to optimize a CPU’s efficient usage of memory during its processes. Consider that every device has specifications that outline the CPU speed and, more relevantly, storage and memory size. The amount of memory available will directly impact the types of applications that can be supported by the device and how efficiently the applications will perform on such a device. Memory management techniques exist to assist us, as developers, in ensuring that our application makes the best use of available resources and that the device will run as smoothly as possible while using the set amount of memory to handle multiple operations and processes.
Memory management considers several factors, such as the following:
- The capacity of the memory device: The less memory that is generally available, the more efficient memory allocation is needed. In any case, efficiency is the most critical management factor, and failing here will lead to sluggish device performance.
- Recovering memory space as needed: Releasing memory after processes run is essential. Some processes are long-running and require memory for extended periods, but shorter-running ones use memory temporarily. Data will linger if memory is not reclaimed, creating unusable memory blocks for future processes.
- Extending memory space through virtual memory: Devices generally have volatile (memory) and non-volatile (hard disk) storage. When volatile memory is at risk of maxing out, the hard disk facilitates additional memory blocks. This additional memory block is called a swap or page file. When the physical memory becomes full, the OS can transfer less frequently used data from RAM to the swap file to free up space for more actively used data.
Devices with CPUs generally have an OS that coordinates resource distribution during processes. This resource distribution is relative to the available hardware, and the performance of the applications is relative to how efficiently memory is managed for them.
A typical has three major areas where memory management is paramount to the performance of said device. These three areas are hardware, application, and the OS. Let’s review some of the nuances that govern memory management at these levels.
Levels of memory management
There are three levels where memory management is implemented, and they are as follows:
- Hardware: RAM and central processing unit (CPU) caches are the hardware components that are primarily involved in memory management activities. RAM is physical memory. This component is independent of the CPU, and while it is used for temporary storage, it boasts much more capacity than the caches and is considerably slower. It generally stores larger and less temporary data, like data needed by long-running applications.
- The memory management unit (MMU), a specialized hardware component that tracks logical or virtual memory and physical address mappings, manages the usage of both RAM and CPU caches. Its primary functions include allocation, deallocation, and memory space protection for various processes running concurrently on the system. Figure 1.2 shows a high-level representation of the MMU and how it maps to the CPU and memory in the system.
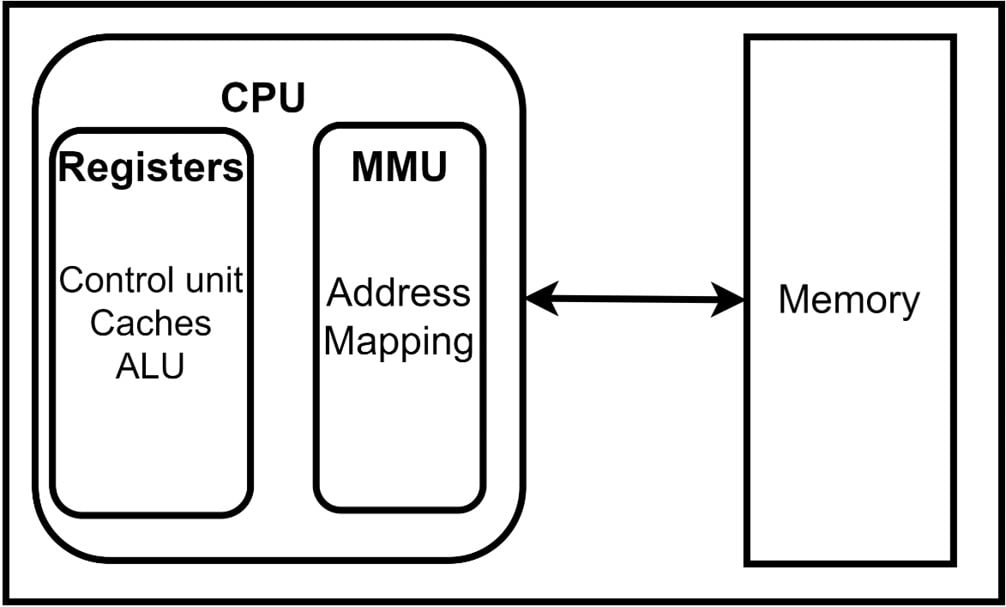
Figure 1.2 – The CPU and MMU and how they connect to memory spaces in RAM
- OS: Systems with CPUs tend to have a system that orchestrates processes and operations at a root level. This is called an operating system (OS). An OS ensures that processes are started and stopped successfully and orchestrates how memory is distributed across the different memory stores for many processes. It also tracks the memory blocks to ensure it knows which resources are being used and by what process to reclaim memory as needed for the following process. OSs also employ several memory allocation methods to ensure the system runs optimally. If physical memory runs out, the OS will use virtual memory, a pre-allocated space on the device’s storage medium. Storage space is considerably slower than RAM, but it helps the OS to ensure that the system resources are used as much as possible to prevent system crashes.
- Application: Different applications have their memory requirements. Developers can write memory allocation logic to ensure that the application controls memory allocation and not the other systems, such as the MMU or the OS. Two methods are generally used by applications to manage their memory allocation are:
- Allocation: Memory is allocated to program components upon request and is locked exclusively for use by that component until it is no longer needed. A developer can manually and explicitly program allocation logic or automatically allow the memory manager to handle allocation using the allocator component. The memory manager option is usually included in a programming language/runtime. If it isn’t, then manual allocation is required.
- Recycling: This is handled through a process called garbage collection. We will look at this concept in more detail later, but in a nutshell, this process will reclaim previously allocated and no-longer-in-use memory blocks. This is essential to ensure that memory is either in use or waiting to be used, but not lost in between. Some languages and runtimes automate this process; otherwise, a developer must provide logic manually.
Application memory managers have several hurdles to contend with. It must be considered that memory management requires the CPU, which will cause competition for the system resources between this and other processes. Also, each time memory allocation or reclamation happens, there is a pause in the application as focus is given to that operation. The faster this can happen, the less obvious it is to the end user, so it must be handled as efficiently as possible. Finally, the more memory is allocated and used, the more fragmented the memory becomes. Memory spreads across non-contiguous blocks, leading to higher allocation times and slower read speeds during runtime.
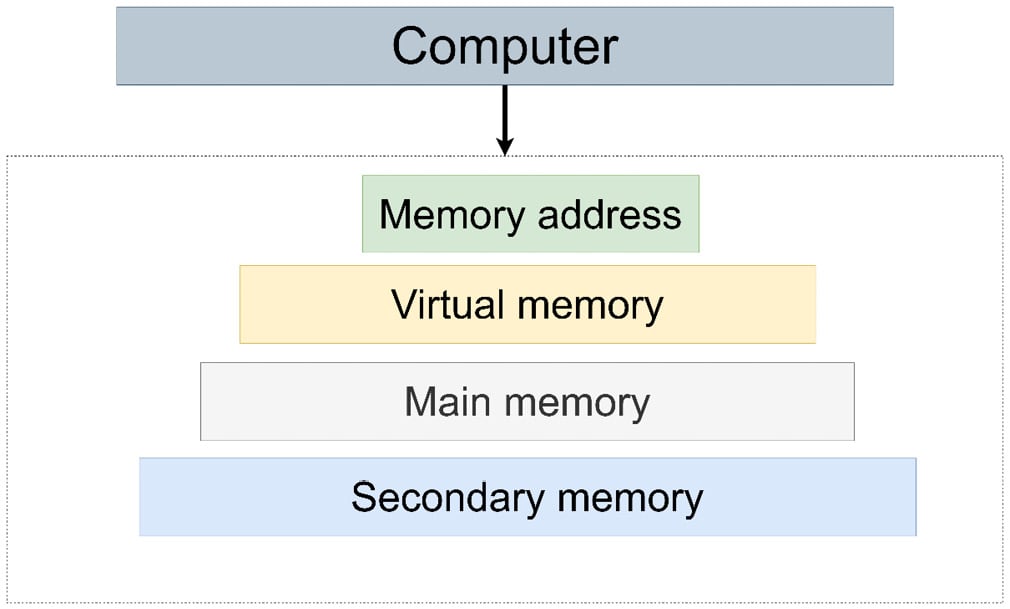
Figure 1.3 – A high-level representation of a computer’s memory hierarchy
Each component in a computer’s hardware and OS has a critical role to play in how memory is managed for applications. If we are to ensure that our devices perform at their peak, we need to understand how resource allocation occurs and some of the potential dangers that poor resource management and allocation can lead to. We will review these topics next.



