






















































Parsing the content of a string using regular expressions
In the previous recipe, we looked at how to use std::regex_match() to verify that the content of a string matches a particular format. The library provides another algorithm called std::regex_search() that matches a regular expression against any part of a string, and not only the entire string, as regex_match() does. This function, however, does not allow us to search through all the occurrences of a regular expression in an input string. For this purpose, we need to use one of the iterator classes available in the library.
In this recipe, you will learn how to parse the content of a string using regular expressions. For this purpose, we will consider the problem of parsing a text file containing name-value pairs. Each such pair is defined on a different line and has the format name = value, but lines starting with a # represent comments and must be ignored. The following is an example:
#remove # to uncomment a line
timeout=120
server = 127.0.0.1
#retrycount=3
Before looking at the implementation details, let's consider some prerequisites.
Getting ready
For general information about regular expression support in C++11, refer to the Verifying the format of a string using regular expressions recipe, earlier in this chapter. Basic knowledge of regular expressions is required to proceed with this recipe.
In the following examples, text is a variable that's defined as follows:
auto text {
R"(
#remove # to uncomment a line
timeout=120
server = 127.0.0.1
#retrycount=3
)"s};
The sole purpose of this is to simplify our snippets, although in a real-world example, you will probably be reading the text from a file or other source.
How to do it...
In order to search for occurrences of a regular expression through a string, you should do the following:
- Include the headers
<regex>and<string>and the namespacestd::string_literalsfor C++14 standard user-defined literals for strings:#include <regex> #include <string> using namespace std::string_literals; - Use raw string literals to specify a regular expression in order to avoid escaping backslashes (which can occur frequently). The following regular expression validates the file format proposed earlier:
auto pattern {R"(^(?!#)(\w+)\s*=\s*([\w\d]+[\w\d._,\-:]*)$)"s}; - Create an
std::regex/std::wregexobject (depending on the character set that is used) to encapsulate the regular expression:auto rx = std::regex{pattern}; - To search for the first occurrence of a regular expression in a given text, use the general-purpose algorithm
std::regex_search()(example 1):auto match = std::smatch{}; if (std::regex_search(text, match, rx)) { std::cout << match[1] << '=' << match[2] << '\n'; } - To find all the occurrences of a regular expression in a given text, use the iterator
std::regex_iterator(example 2):auto end = std::sregex_iterator{}; for (auto it=std::sregex_iterator{ std::begin(text), std::end(text), rx }; it != end; ++it) { std::cout << '\'' << (*it)[1] << "'='" << (*it)[2] << '\'' << '\n'; } - To iterate through all the subexpressions of a match, use the iterator
std::regex_token_iterator(example 3):auto end = std::sregex_token_iterator{}; for (auto it = std::sregex_token_iterator{ std::begin(text), std::end(text), rx }; it != end; ++it) { std::cout << *it << '\n'; }
How it works...
A simple regular expression that can parse the input file shown earlier may look like this:
^(?!#)(\w+)\s*=\s*([\w\d]+[\w\d._,\-:]*)$
This regular expression is supposed to ignore all lines that start with a #; for those that do not start with #, match a name followed by the equals sign and then a value that can be composed of alphanumeric characters and several other characters (underscore, dot, comma, and so on). The exact meaning of this regular expression is explained as follows:
|
Part |
Description |
|
|
Start of line. |
|
|
A negative lookahead that makes sure that it is not possible to match the |
|
|
A capturing group representing an identifier of at least a one-word character. |
|
|
Any whitespaces. |
|
|
Equals sign. |
|
|
Any whitespaces. |
|
|
A capturing group representing a value that starts with an alphanumeric character, but can also contain a dot, comma, backslash, hyphen, colon, or an underscore. |
|
|
End of line. |
We can use std::regex_search() to search for a match anywhere in the input text. This algorithm has several overloads, but in general, they work in the same way. You must specify the range of characters to work through, an output std::match_results object that will contain the result of the match, and an std::basic_regex object representing the regular expression and matching flags (which define the way the search is done). The function returns true if a match was found or false otherwise.
In the first example from the previous section (see the fourth list item), match is an instance of std::smatch that is a typedef of std::match_results with string::const_iterator as the template type. If a match was found, this object will contain the matching information in a sequence of values for all matched subexpressions. The submatch at index 0 is always the entire match. The submatch at index 1 is the first subexpression that was matched, the submatch at index 2 is the second subexpression that was matched, and so on. Since we have two capturing groups (which are subexpressions) in our regular expression, the std::match_results will have three submatches in the event of success. The identifier representing the name is at index 1, and the value after the equals sign is at index 2. Therefore, this code only prints the following:

Figure 2.4: Output of first example
The std::regex_search() algorithm is not able to iterate through all the possible matches in a piece of text. To do that, we need to use an iterator. std::regex_iterator is intended for this purpose. It allows not only iterating through all the matches, but also accessing all the submatches of a match.
The iterator actually calls std::regex_search() upon construction and on each increment, and it remembers the resulting std::match_results from the call. The default constructor creates an iterator that represents the end of the sequence and can be used to test when the loop through the matches should stop.
In the second example from the previous section (see the fifth list item), we first create an end-of-sequence iterator, and then we start iterating through all the possible matches. When constructed, it will call std::regex_match(), and if a match is found, we can access its results through the current iterator. This will continue until no match is found (the end of the sequence). This code will print the following output:

Figure 2.5: Output of second example
An alternative to std::regex_iterator is std::regex_token_iterator. This works similar to the way std::regex_iterator works and, in fact, it contains such an iterator internally, except that it enables us to access a particular subexpression from a match. This is shown in the third example in the How to do it... section (see the sixth list item). We start by creating an end-of-sequence iterator and then loop through the matches until the end-of-sequence is reached. In the constructor we used, we did not specify the index of the subexpression to access through the iterator; therefore, the default value of 0 is used. This means this program will print all the matches:

Figure 2.6: Output of third example
If we wanted to access only the first subexpression (this means the names in our case), all we had to do was specify the index of the subexpression in the constructor of the token iterator, as shown here:
auto end = std::sregex_token_iterator{};
for (auto it = std::sregex_token_iterator{ std::begin(text),
std::end(text), rx, 1 };
it != end; ++it)
{
std::cout << *it << '\n';
}
This time, the output that we get contains only the names. This is shown in the following image:

Figure 2.7: Output containing only the names
An interesting thing about the token iterator is that it can return the unmatched parts of the string if the index of the subexpressions is -1, in which case it returns an std::match_results object that corresponds to the sequence of characters between the last match and the end of the sequence:
auto end = std::sregex_token_iterator{};
for (auto it = std::sregex_token_iterator{ std::begin(text),
std::end(text), rx, -1 };
it != end; ++it)
{
std::cout << *it << '\n';
}
This program will output the following:
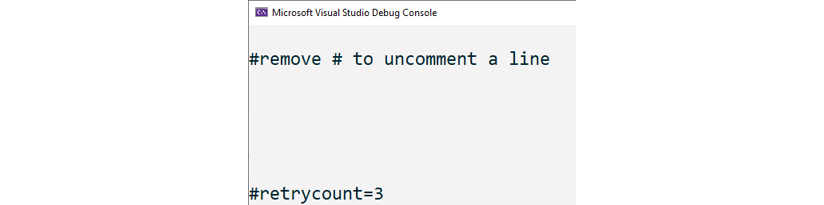
Figure 2.8: Output including empty lines
Please note that the empty lines in the output correspond to empty tokens.
See also
- Verifying the format of a string using regular expressions to familiarize yourself with the C++ library support for working with regular expressions
- Replacing the content of a string using regular expressions to learn how to perform multiple matches of a pattern in a text













