






















































Beyond requests – background and scheduled tasks
Although the primary goal of web applications is to handle HTTP requests, that’s not the only job most Rails applications do. A lot of things happen in the background.
The need for background jobs
One of the vital characteristics of web applications is throughput. This can be defined as the number of requests that can be served in a period of time – usually, a second or a minute (requests per second (RPS) or requests per minute (RPM), respectively).
Ruby web applications usually have a limited number of web workers to serve requests, and each worker is only capable of processing one request at a time. A worker is backed by a Ruby thread or a system process. Due to the Global Virtual Machine Lock (GVL), adding more threads doesn’t help us to increase the throughput. Usually, the number of threads is as low as three to five.
Choosing the right number of threads
Since Ruby 3.2, it’s been possible to measure the exact time a Ruby thread spends waiting for I/O using, for example, the GVLTools library (https://github.com/Shopify/gvltools). Knowing the exact time, you can choose the number of threads that fits your application the best.
Scaling with processes requires a proportional amount of RAM. We need to look for other solutions.
Beyond processes and threads – fibers
Ruby has the solution to this concurrency problem – fibers (https://rubyapi.org/3.2/o/fiber). We can describe it as a lighter alternative to a thread, which can be used for cooperative concurrency – a concurrency model in which the context switch is controlled by the user, not the VM. Since Ruby 3, fibers can automatically yield execution on I/O operations (networking, filesystem access, and so on), which makes them fit the web application use case well. Unfortunately, Rails itself is not fiber-ready yet, so we cannot fully use web servers that leverage this technology, such as Falcon (https://github.com/socketry/falcon).
For many years, Rails applications relied on the following idea – to minimize a request time (and, thus, increase throughput), we should offload as much work as possible to background execution. Libraries, such as Sidekiq and Delayed Job, brought this idea to life and popularized it, and later, with the release of Rails 4, Active Job made this approach official.
What a gem – sidekiq
Sidekiq (https://github.com/mperham/sidekiq) is one of the most popular Ruby gems and the number one background processing engine. It relies on the idea that background tasks are usually I/O heavy, and thus, we can efficiently scale processing by using Ruby threads. Sidekiq uses Redis as a queueing backend for jobs, which reduces the infrastructure overhead and positively impacts performance.
What is a background job? It is a task that’s executed outside of the request-response loop.
A typical example of such a task would be sending an email. To send an email, we must perform a network request (SMTP or HTTP), but we don’t need to wait for it to be completed to send a response back to the user. How can we break out of the synchronous request-handling operation in Ruby? We could use threads, which might look like this:
class PasswordResetController < ApplicationController def create user = User.find_by!(email: params[:email]) Thread.new do UserMailer.with(user:).reset_password.deliver_now end end end
This simple solution has a lot of rough edges – we do not control the number of threads, we do not handle potential exceptions, and we have no strategy on what to do if there are failures. Therefore, background job abstraction (Active Job, in particular) arose – to provide a general solution to common problems with asynchronous tasks.
Next, let’s talk about the fundamental concepts of background processing in Rails.
Jobs as units of work
The background job layer is built on top of job and queue abstractions.
Job is a task definition that includes the actual business logic and describes the processing-related properties, such as retrying logic and execution priority. The latter justifies the need for a separate abstraction, Job; pure Ruby objects are not enough.
Queues are natural for background jobs in web applications, since we usually want our offloaded tasks to be executed on a first in, first out basis. Background processing engines can use any data structure and/or storage mechanism to keep and execute tasks; we only need them to comply with the queue interface.
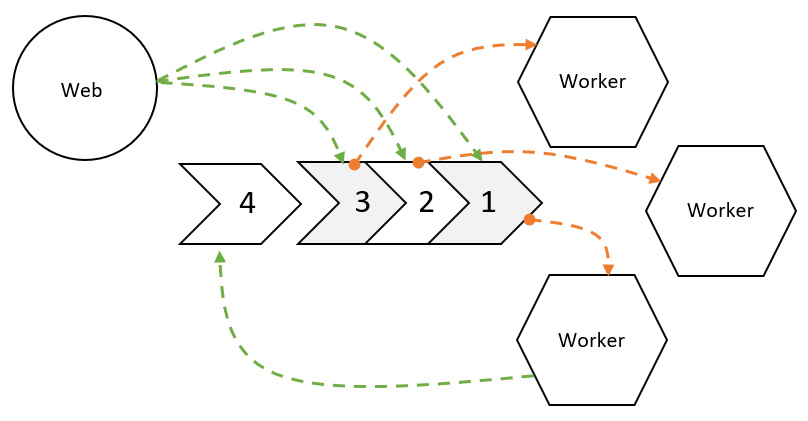
Figure 1.3 – A high-level overview of the background tasks queue architecture
Background jobs are meant to be independent and can be executed concurrently (although we can enqueue jobs within jobs forming background workflows). Thus, similar to web requests, background jobs are also units of work.
Each unit of work in a Rails application can be associated with an execution context. Execution context is an environment (state) associated with a particular execution frame, which has a clearly defined beginning and end. For web requests, an environment is defined by an HTTP request and its properties (for example, user session). Background jobs do not have such natural environments but can define one. Thus, another utilitarian responsibility of a background job is to define an execution context for the corresponding business operation.
Thus, the background jobs layer can be seen as the internal inbound layer. Unlike external inbound layers (for example, controllers), we do not deal with user input here, and hence, no authentication, authorization, or validation is required. Otherwise, from a software design point of view, jobs can be treated the same way as controllers.
Most background jobs are initiated within web requests or other jobs. However, there is another potential trigger – time.
Scheduled jobs
Scheduled jobs are a special class of background jobs that are triggered by a clock, not as a result of a user action or another job execution. Besides that, there is no difference between scheduled jobs and regular background jobs.
However, since Rails doesn’t provide a solution to define a jobs schedule out of the box, it’s easy to escape from the abstraction and come up with a unique (that is, more difficult to maintain) solution.
For example, many gems, such as whenever (https://github.com/javan/whenever) or rufus-scheduler (https://github.com/jmettraux/rufus-scheduler), allow you to run arbitrary Ruby code or system commands on schedule, not only enqueuing background jobs.
Such custom jobs lack all the benefits of being executed by a background jobs engine – failure handling, logging, instrumentation, and so on. They also introduce additional conceptual complexity. Scheduled jobs belong to the same abstraction layer as regular background jobs and, thus, should be a part of the layer, not its own abstraction (or a lack of it).
We have covered the basics of Rails inbound layers, those responsible for triggering units of work essential for all web applications. Irrespective of the kind of request that initiates the work, in most situations such work in a web application would be associated with data reading and writing.


