






















































Discovering core concepts and terminology
Before diving into the specifics of how to create our cluster and start working with Databricks, there are a certain number of concepts with which we must familiarize ourselves first. Together, these define the fundamental tools that Databricks provides to the user and are available both in the web application UI as well as the REST API:
- Workspaces: An Azure Databricks workspace is an environment where the user can access all of their assets: jobs, notebooks, clusters, libraries, data, and models. Everything is organized into folders and this allows the user to save notebooks and libraries and share them with other users to collaborate. The workspace is used to store notebooks and libraries, but not to connect or store data.
- Data: Data can be imported into the mounted Azure Databricks distributed filesystem from a variety of sources. This can be uploaded as tables directly into the workspace, from Azure Blob Storage or AWS S3.
- Notebooks: Databricks notebooks are very similar to Jupyter notebooks in Python. They are web interface applications that are designed to run code thanks to runnable cells that operate on files and tables, and that also provide visualizations and contain narrative text. The end result is a document with code, visualizations, and clear text documentation that can be easily shared. Notebooks are one of the two ways that we can run code in Azure Databricks. The other way is through jobs. Notebooks have a set of cells that allow the user to execute commands and can hold code in languages such as Scala, Python, R, SQL, or Markdown. To be able to execute commands, they have to be connected to a cluster, but this connection is not necessarily permanent. This allows an easy way to share these notebooks via the web or in a local machine. Notebooks can be scheduled and triggered as jobs to create a data pipeline, run ML models, or update dashboards:
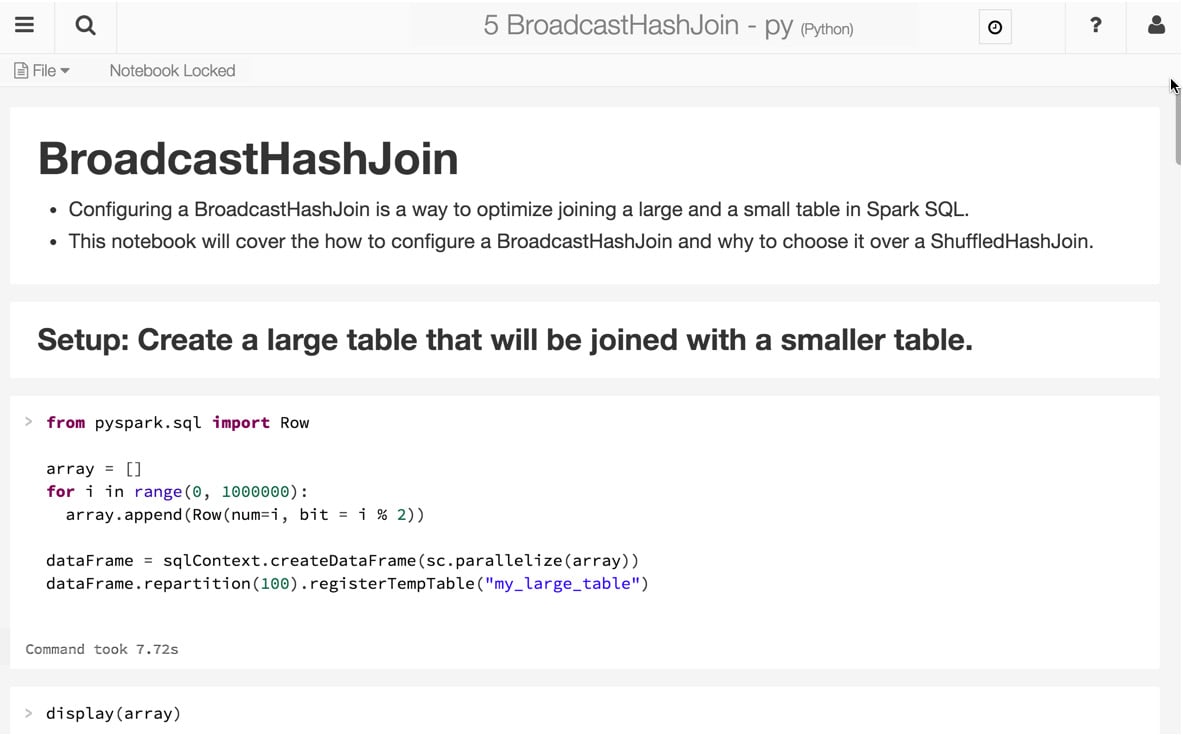
Figure 1.2 – Azure Databricks notebook. Source: https://databricks.com/wp-content/uploads/2015/10/notebook-example.png
- Clusters: A cluster is a set of connected servers that work together collaboratively as if they are a single (much more powerful) computer. In this environment, you can perform tasks and execute code from notebooks working with data stored in a certain storage facility or uploaded as a table. These clusters have the means to manage and control who can access each one of them. Clusters are used to improve performance and availability compared to a single server, while typically being more cost-effective than a single server of comparable speed or availability. It is in the clusters where we run our data science jobs, ETL pipelines, analytics, and more.
There is a distinction between all-purpose clusters and job clusters. All-purpose clusters are where we work collaboratively and interactively using notebooks, but job clusters are where we execute automatic and more concrete jobs. The way of creating these clusters differs depending on whether it is an all-purpose cluster or a job cluster. The former can be created using the UI, CLI, or REST API, while the latter is created using the job scheduler to run a specific job and is terminated when this is done.
- Jobs: Jobs are the tasks that we run when executing a notebook, JAR, or Python file in a certain cluster. The execution can be created and scheduled manually or by the REST API.
- Apps: Third-party apps such as Table can be used inside Azure Databricks. These integrations are called apps.
- Apache SparkContext/environments: Apache SparkContext is the main application in Apache Spark running internal services and connecting to the Spark execution environment. While, historically, Apache Spark has had two core contexts available to the user (SparkContext and SQLContext), in the 2.X versions, there is just one – the SparkSession.
- Dashboards: Dashboards are a way to display the output of the cells of a notebook without the code that is required to generate them. They can be created from notebooks:
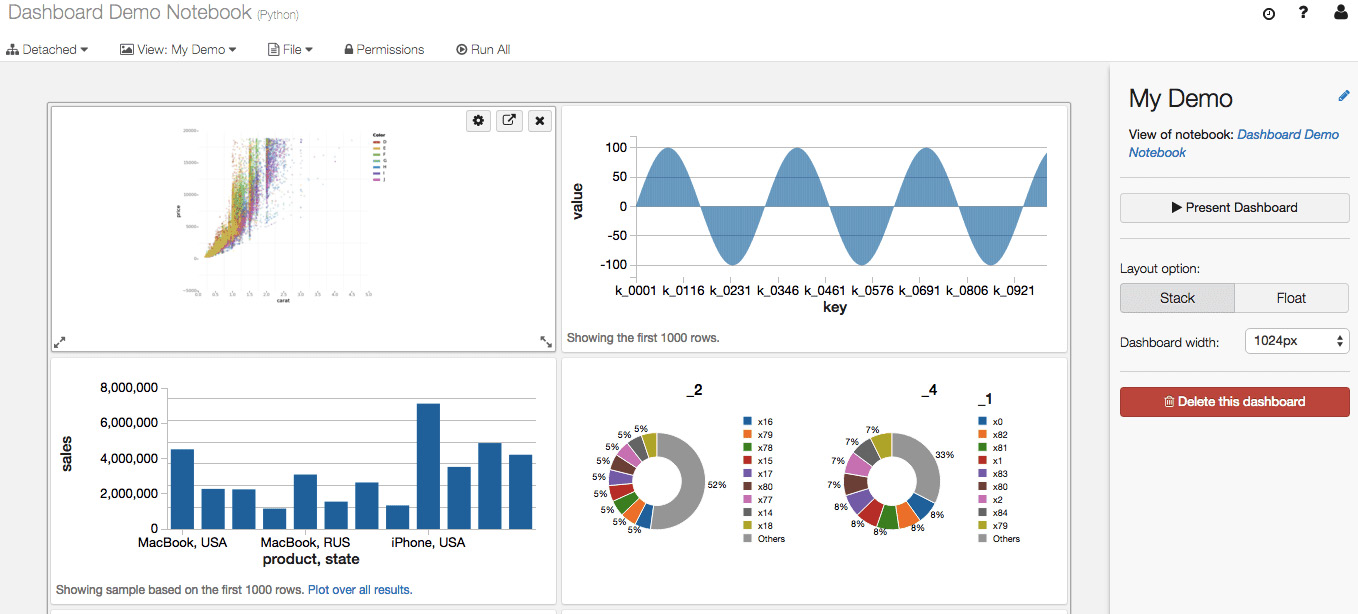
Figure 1.3 – Azure Databricks notebook. Source: https://databricks.com/wp-content/uploads/2016/02/Databricks-dashboards-screenshot.png
- Libraries: Libraries are modules that add functionality, written in Scala or Python, that can be pulled from a repository or installed via package management systems utilities such as PyPI or Maven.
- Tables: Tables are structured data that you can use for analysis or for building models that can be stored on Amazon S3 or Azure Blob Storage, or in the cluster that you're currently using cached in memory. These tables can be either global or local, the first being available across all clusters. A local table cannot be accessed from other clusters.
- Experiments: Every time we run MLflow, it belongs to a certain experiment. Experiments are the central way of organizing and controlling all the MLflow runs. In each experiment, the user can search, compare, and visualize results, as well as downloading artifacts or metadata for further analysis.
- Models: While working with ML or deep learning, the models that we train and use to infer are registered in the Azure Databricks MLflow Model Registry. MLflow is an open source platform designed to manage ML life cycles, which includes the tracking of experiments and runs, and MLflow Model Registry is a centralized model store that allows users to fully control the life cycle of MLflow models. It has features that enable us to manage versions, transition between different stages, have a chronological model heritage, and control model version annotations and descriptions.
- Azure Databricks workspace filesystem: Azure Databricks is deployed with a distributed filesystem. This system is mounted in the workspace and allows the user to mount storage objects and interact with them using filesystem paths. It allows us to persist files so the data is not lost when the cluster is terminated.
This section focused on the core pieces of Azure Databricks. In the next section, you will learn how to interact with Azure Databricks through the workspace, which is the place where we interact with our assets.





















