






















































Experiments
The full implementation of the deep Q-learning algorithm can be downloaded from GitHub (link xxx). To train our AI player for Breakout, run the following command under the src folder:
python train.py -g Breakout -d gpuThere are two arguments in train.py. One is -g or --game, indicating the name of the game one wants to test. The other one is -d or --device, which specifies the device (CPU or GPU) one wants to use to train the Q-network.
For Atari games, even with a high-end GPU, it will take 4-7 days to make our AI player achieve human-level performance. In order to test the algorithm quickly, a special game called demo is implemented as a lightweight benchmark. Run the demo via the following:
python train.py -g demo -d cpu
The demo game is based on the GridWorld game on the website at https://cs.stanford.edu/people/karpathy/convnetjs/demo/rldemo.html:
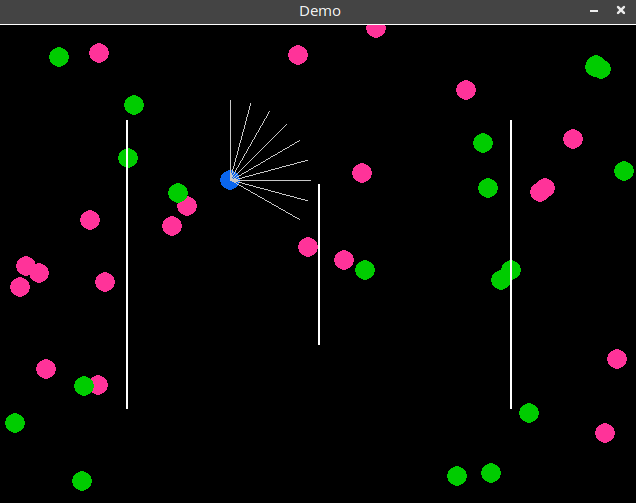
In this game, a robot in a 2D grid world has nine eyes pointing in different angles, and each eye senses three values along its direction...


