






















































Loss and cost functions
At the beginning of this chapter, we discussed the concept of generic target function so as to optimize in order to solve a machine learning problem. More formally, in a supervised scenario, where we have finite datasets X and Y:
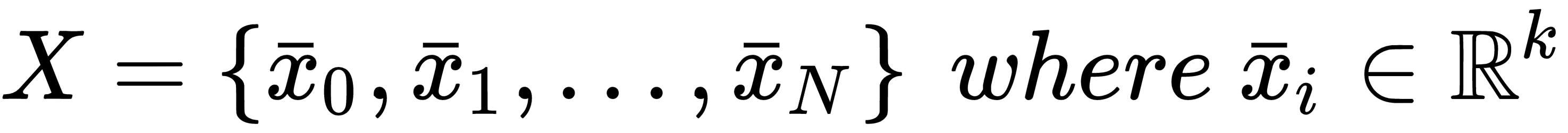
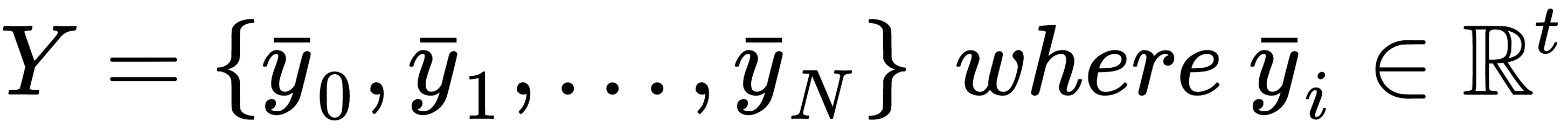
We can define the generic loss function for a single sample as:
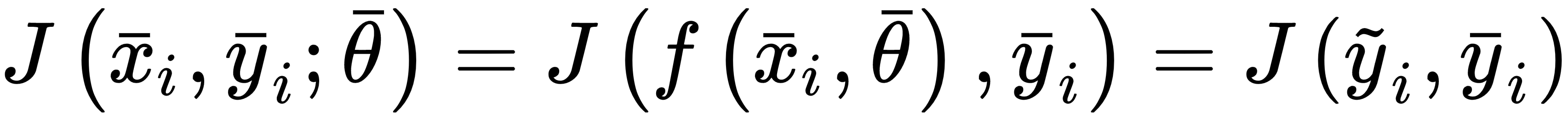
J is a function of the whole parameter set, and must be proportional to the error between the true label and the predicted. Another important property is convexity. In many real cases, this is an almost impossible condition; however, it's always useful to look for convex loss functions, because they can be easily optimized through the gradient descent method. It's useful to consider a loss function as an intermediate between our training process and a pure mathematical optimization. The missing link is the complete data. As already discussed, X is drawn from pdata, so it should represent the true distribution. Therefore, when minimizing the loss function, we're considering a potential subset of points, and never the whole real dataset. In many cases, this isn't a limitation, because, if the bias is null and the variance is small enough, the resulting model will show a good generalization ability (high training and validation accuracy); however, considering the data generating process, it's useful to introduce another measure called expected risk:
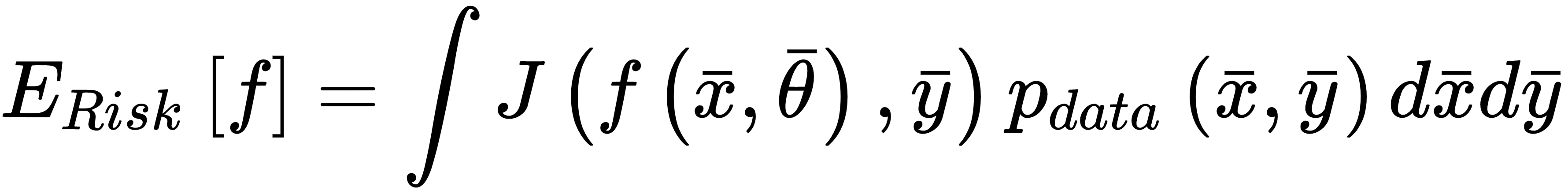
This value can be interpreted as an average of the loss function over all possible samples drawn from pdata. Minimizing the expected risk implies the maximization of the global accuracy. When working with a finite number of training samples, instead, it's common to define a cost function (often called a loss function as well, and not to be confused with the log-likelihood):
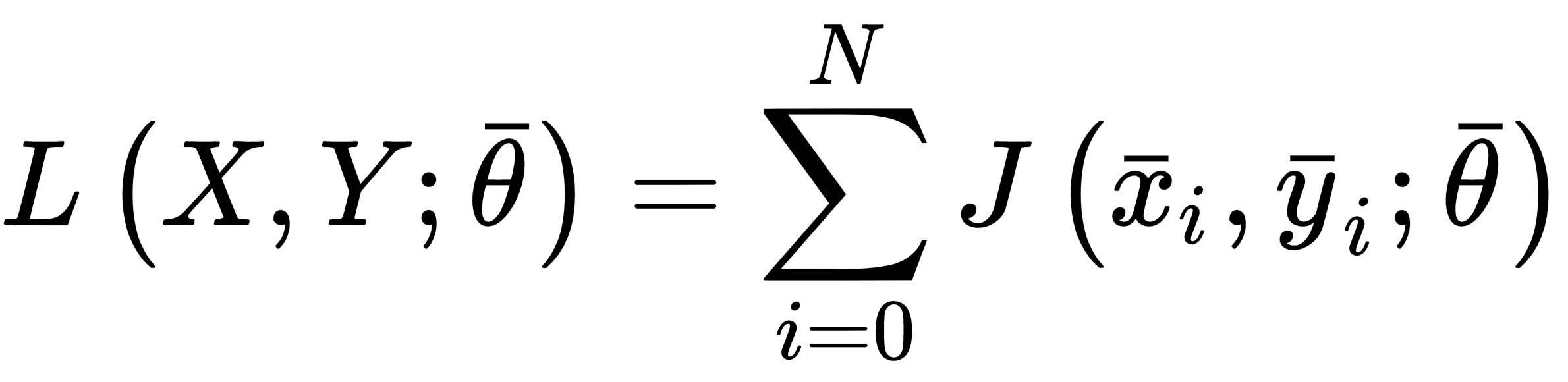
This is the actual function that we're going to minimize and, divided by the number of samples (a factor that doesn't have any impact), it's also called empirical risk, because it's an approximation (based on real data) of the expected risk. In other words, we want to find a set of parameters so that:
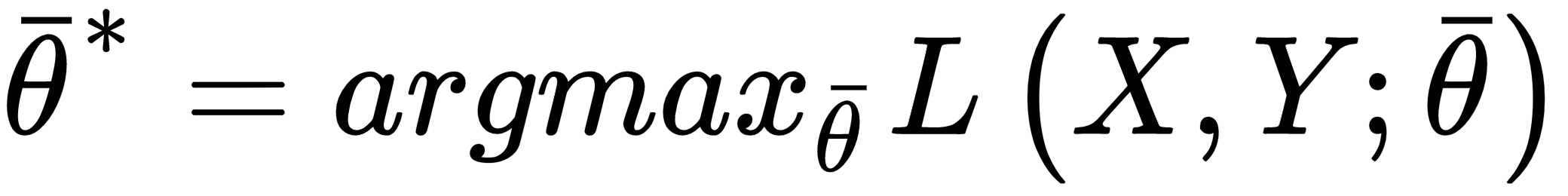
When the cost function has more than two parameters, it's very difficult and perhaps even impossible to understand its internal structure; however, we can analyze some potential conditions using a bidimensional diagram:
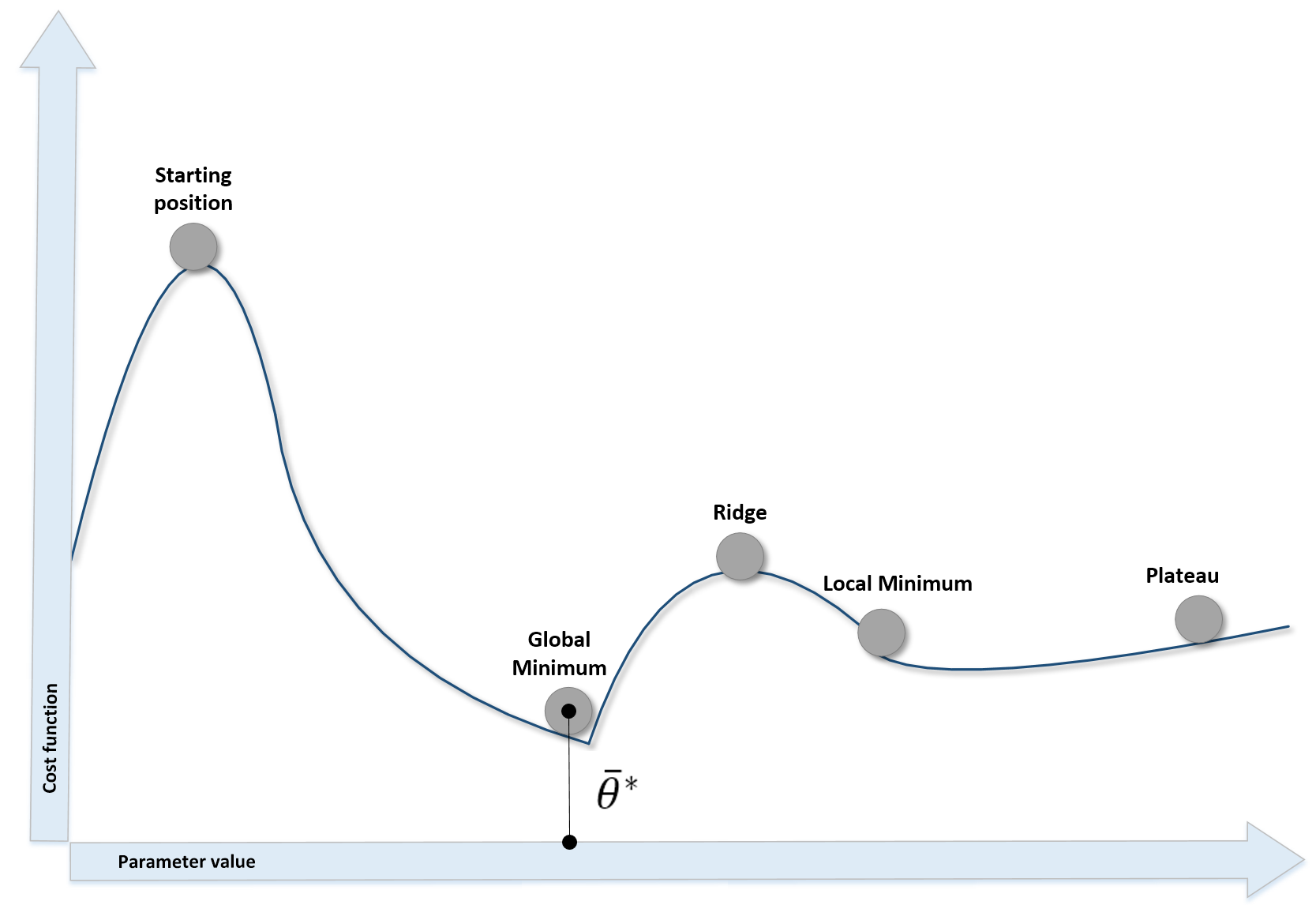
Different kinds of points in a bidimensional scenario
The different situations we can observe are:
- The starting point, where the cost function is usually very high due to the error.
- Local minima, where the gradient is null (and the second derivative is positive). They are candidates for the optimal parameter set, but unfortunately, if the concavity isn't too deep, an inertial movement or some noise can easily move the point away.
- Ridges (or local maxima), where the gradient is null, and the second derivative is negative. They are unstable points, because a minimum perturbation allows escaping, reaching lower-cost areas.
- Plateaus, or the region where the surface is almost flat and the gradient is close to zero. The only way to escape a plateau is to keep a residual kinetic energy—we're going to discuss this concept when talking about neural optimization algorithms.
- Global minimum, the point we want to reach to optimize the cost function.
Even if local minima are likely when the number of parameters is small, they become very unlikely when the model has a large number of parameters. In fact, an n-dimensional point θ* is a local minimum for a convex function (and here, we're assuming L to be convex) only if:
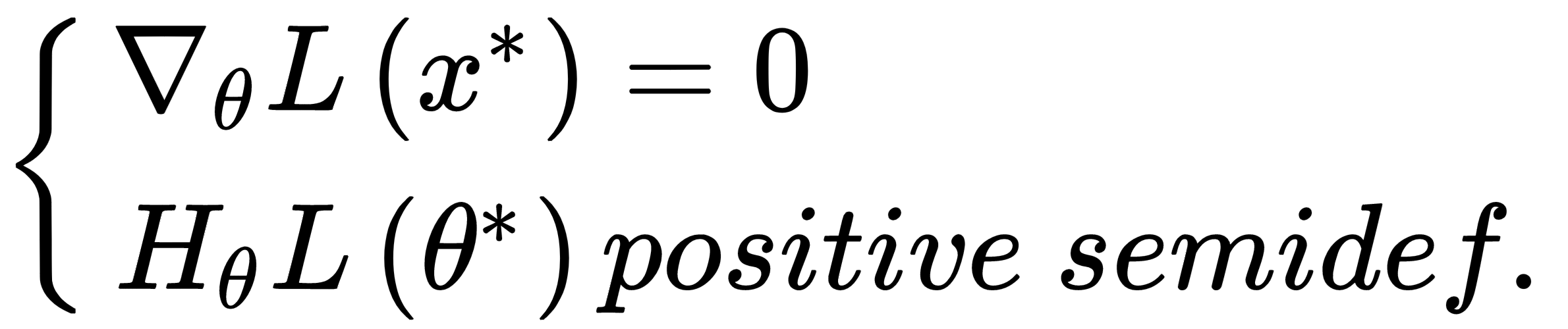
The second condition imposes a positive semi-definite Hessian matrix (equivalently, all principal minors Hn made with the first n rows and n columns must be non-negative), therefore all its eigenvalues λ0, λ1, ..., λN must be non-negative. This probability decreases with the number of parameters (H is a n×n square matrix and has n eigenvalues), and becomes close to zero in deep learning models where the number of weights can be in the order of 10,000,000 (or even more). The reader interested in a complete mathematical proof can read High Dimensional Spaces, Deep Learning and Adversarial Examples, Dube S., arXiv:1801.00634 [cs.CV]. As a consequence, a more common condition to consider is instead the presence of saddle points, where the eigenvalues have different signs and the orthogonal directional derivatives are null, even if the points are neither local maxima nor minima. Consider, for example, the following plot:
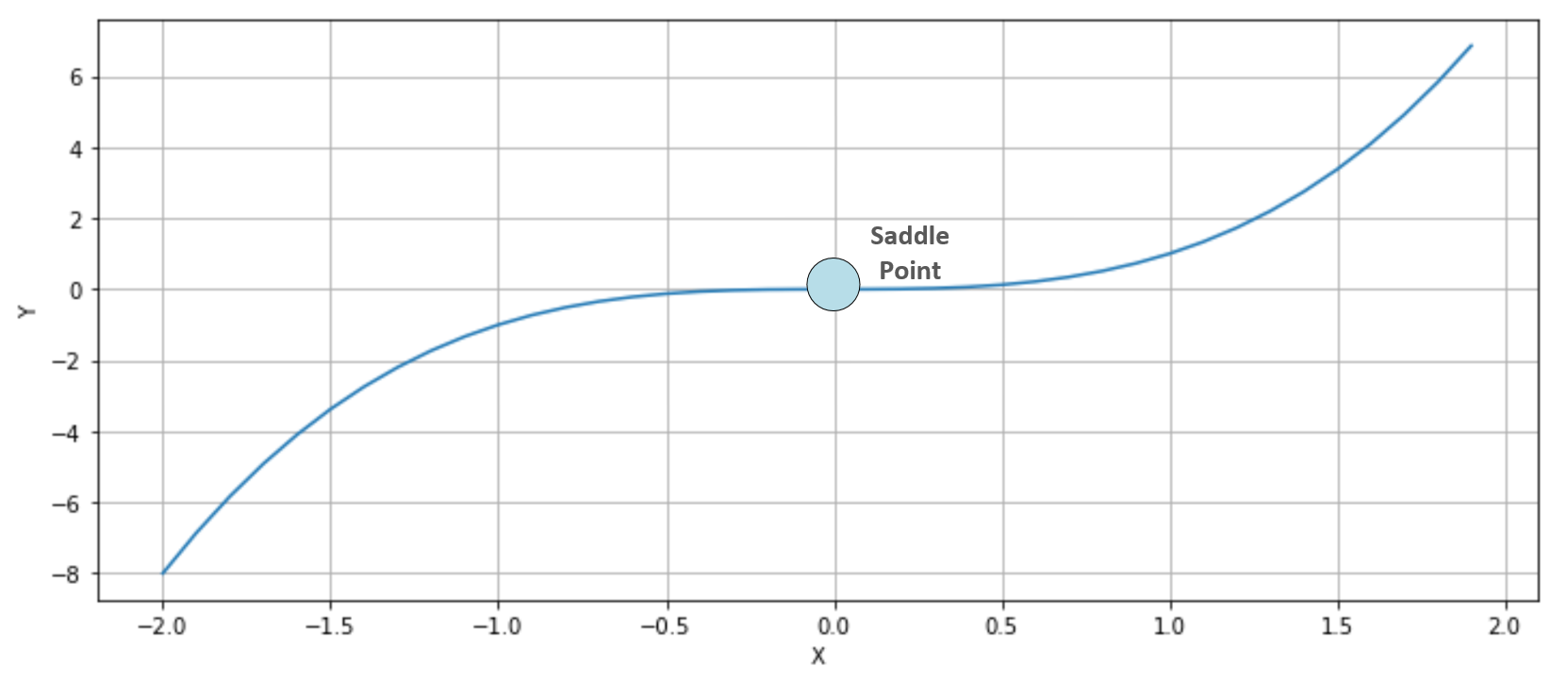
Saddle point in a bidimensional scenario
The function is y=x3 whose first and second derivatives are y'=3x2 and y''=6x. Therefore, y'(0)=y''(0)=0. In this case (single-valued function), this point is also called a point of inflection, because at x=0, the function shows a change in the concavity. In three dimensions, it's easier to understand why a saddle point has been called in this way. Consider, for example, the following plot:
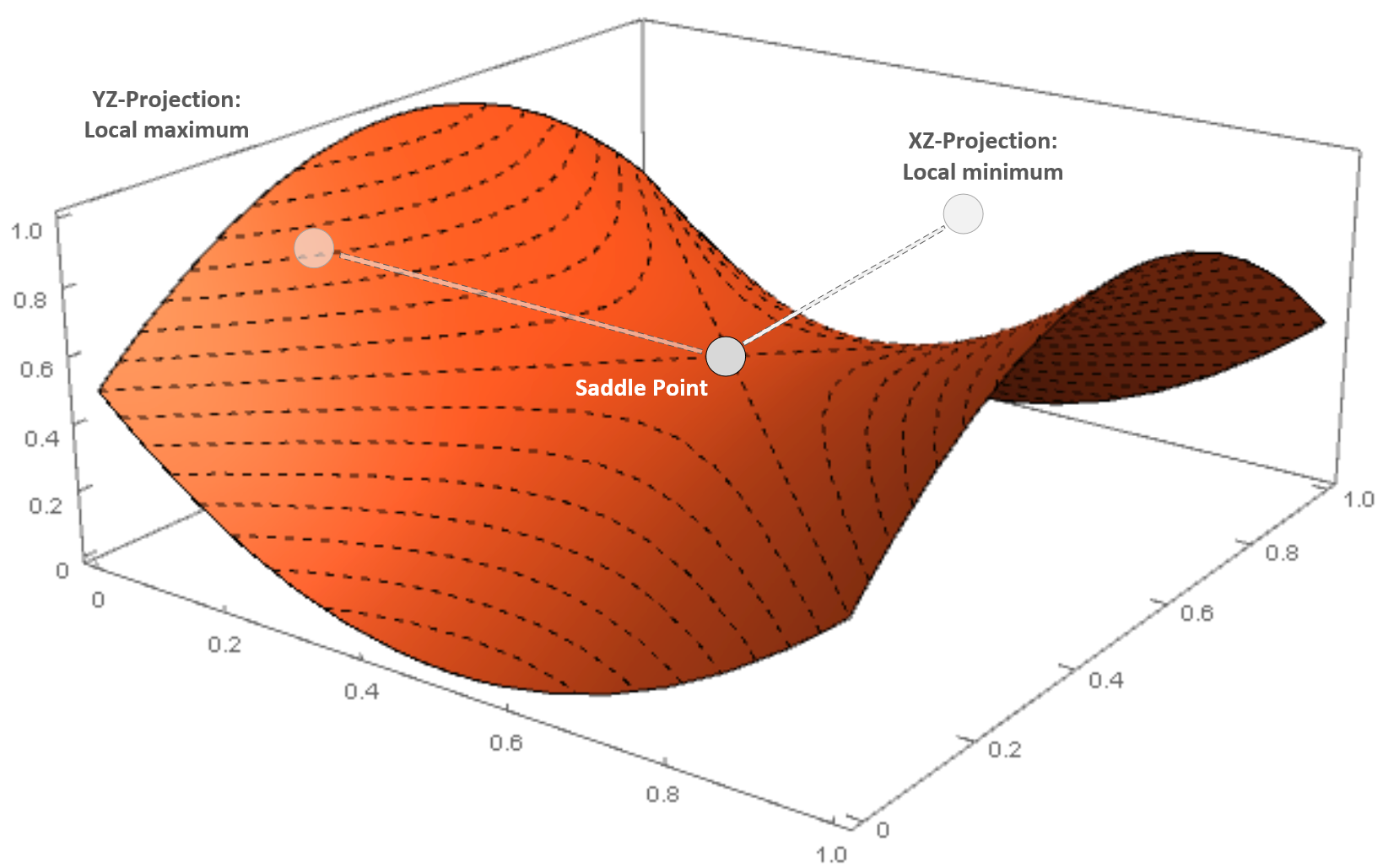
Saddle point in a three-dimensional scenario
The surface is very similar to a horse saddle, and if we project the point on an orthogonal plane, XZ is a minimum, while on another plane (YZ) it is a maximum. Saddle points are quite dangerous, because many simpler optimization algorithms can slow down and even stop, losing the ability to find the right direction.
Examples of cost functions
In this section, we expose some common cost functions that are employed in both classification and regression tasks. Some of them will be extensively adopted in our examples in the next chapters, particularly when discussing training processes in shallow and deep neural networks.
Mean squared error
Mean squared error is one of the most common regression cost functions. Its generic expression is:
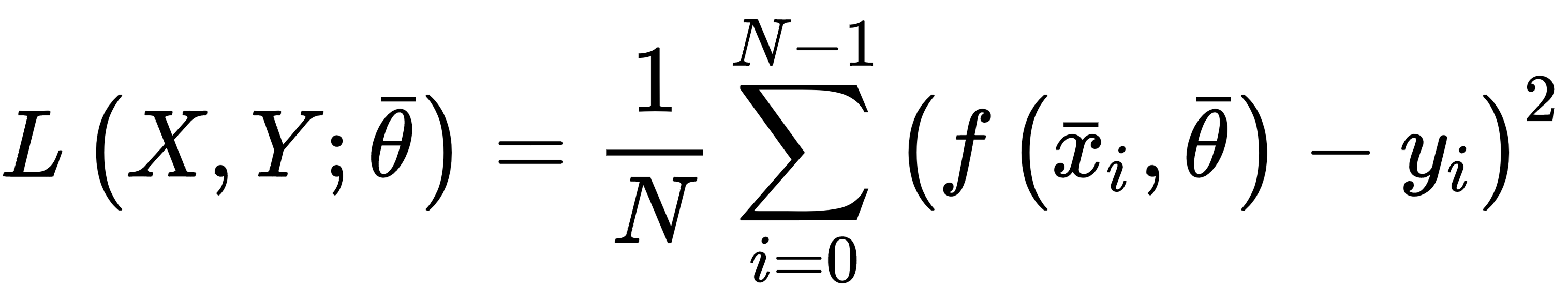
This function is differentiable at every point of its domain and it's convex, so it can be optimized using the stochastic gradient descent (SGD) algorithm; however, there's a drawback when employed in regressions where there are outliers. As its value is always quadratic when the distance between the prediction and the actual value (corresponding to an outlier) is large, the relative error is high, and this can lead to an unacceptable correction.
Huber cost function
As explained, mean squared error isn't robust to outliers, because it's always quadratic independently of the distance between actual value and prediction. To overcome this problem, it's possible to employ the Hubercost function, which is based on threshold tH, so that for distances less than tH, its behavior is quadratic, while for a distance greater than tH, it becomes linear, reducing the entity of the error and, therefore, the relative importance of the outliers.
The analytical expression is:
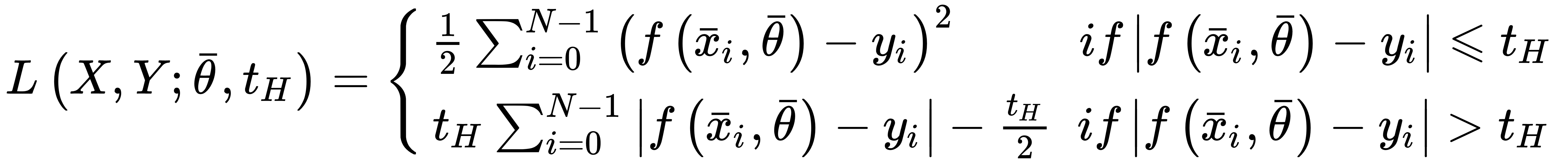
Hinge cost function
This cost function is adopted by SVM, where the goal is to maximize the distance between the separation boundaries (where the support vector lies). It's analytic expression is:
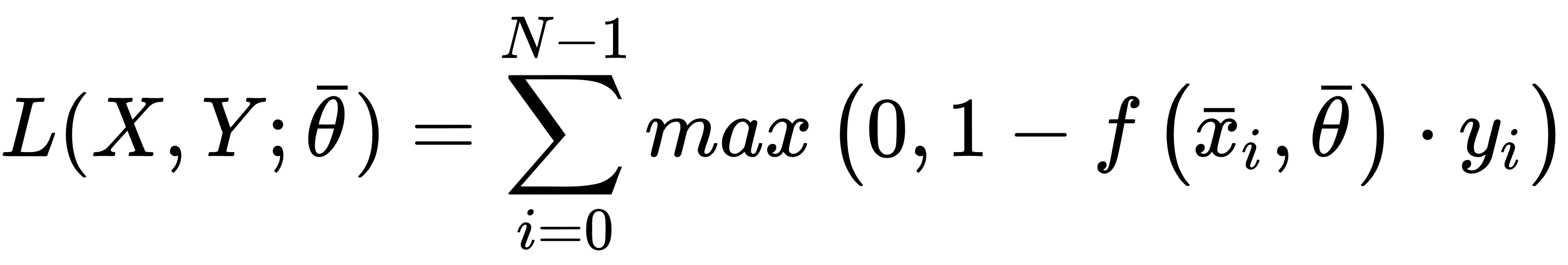
Contrary to the other examples, this cost function is not optimized using classic stochastic gradient descent methods, because it's not differentiable at all points where:
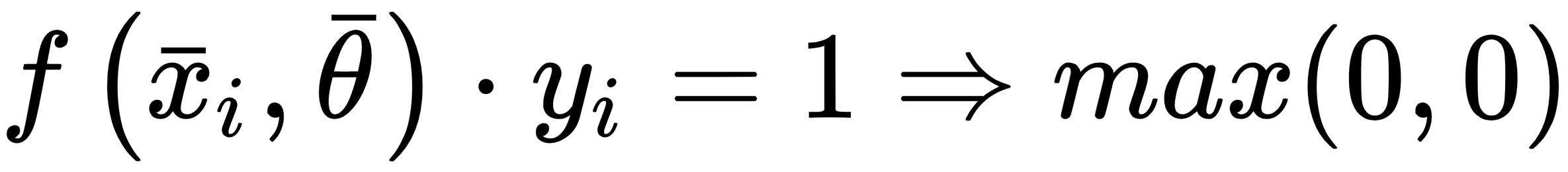
For this reason, SVM algorithms are optimized using quadratic programming techniques.
Categorical cross-entropy
Categorical cross-entropy is the most diffused classification cost function, adopted by logistic regression and the majority of neural architectures. The generic analytical expression is:
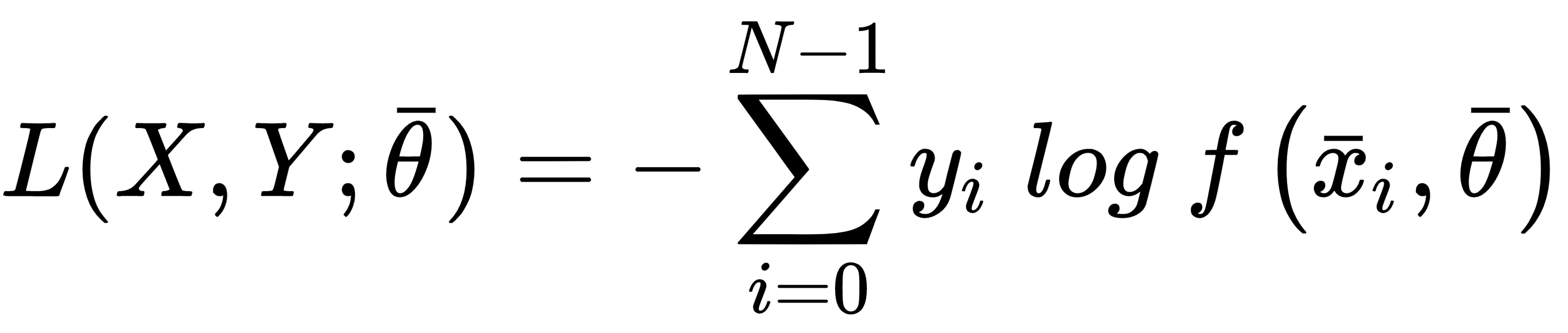
This cost function is convex and can be easily optimized using stochastic gradient descent techniques; moreover, it has another important interpretation. If we are training a classifier, our goal is to create a model whose distribution is as similar as possible to pdata. This condition can be achieved by minimizing the Kullback-Leibler divergence between the two distributions:
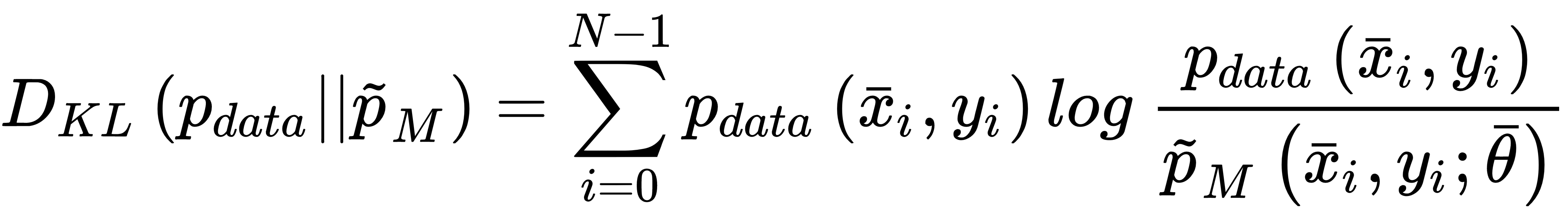
In the previous expression, pM is the distribution generated by the model. Now, if we rewrite the divergence, we get:
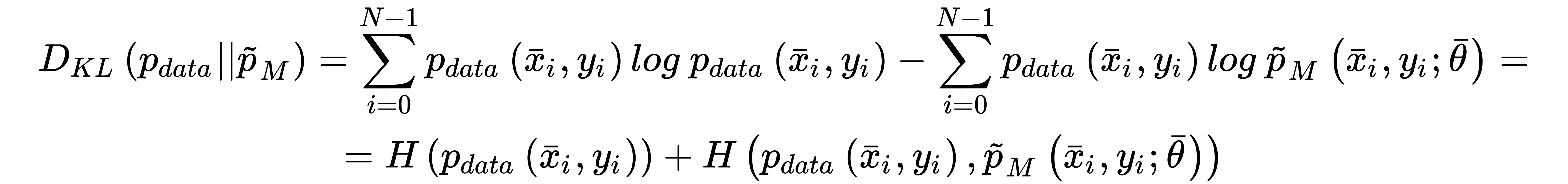
The first term is the entropy of the data-generating distribution, and it doesn't depend on the model parameters, while the second one is the cross-entropy. Therefore, if we minimize the cross-entropy, we also minimize the Kullback-Leibler divergence, forcing the model to reproduce a distribution that is very similar to pdata. This is a very elegant explanation as to why the cross-entropy cost function is an excellent choice for classification problems.
Regularization
When a model is ill-conditioned or prone to overfitting, regularization offers some valid tools to mitigate the problems. From a mathematical viewpoint, a regularizer is a penalty added to the cost function, so to impose an extra-condition on the evolution of the parameters:
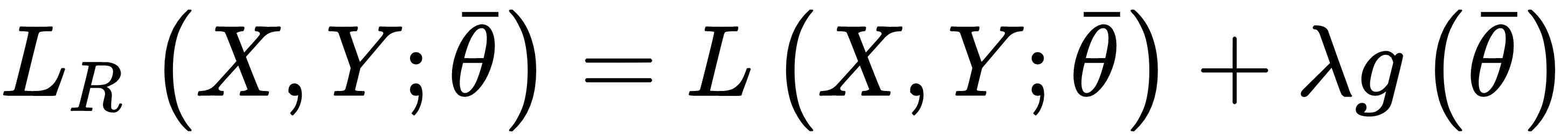
The parameter λ controls the strength of the regularization, which is expressed through the function g(θ). A fundamental condition on g(θ) is that it must be differentiable so that the new composite cost function can still be optimized using SGD algorithms. In general, any regular function can be employed; however, we normally need a function that can contrast the indefinite growth of the parameters.
To understand the principle, let's consider the following diagram:
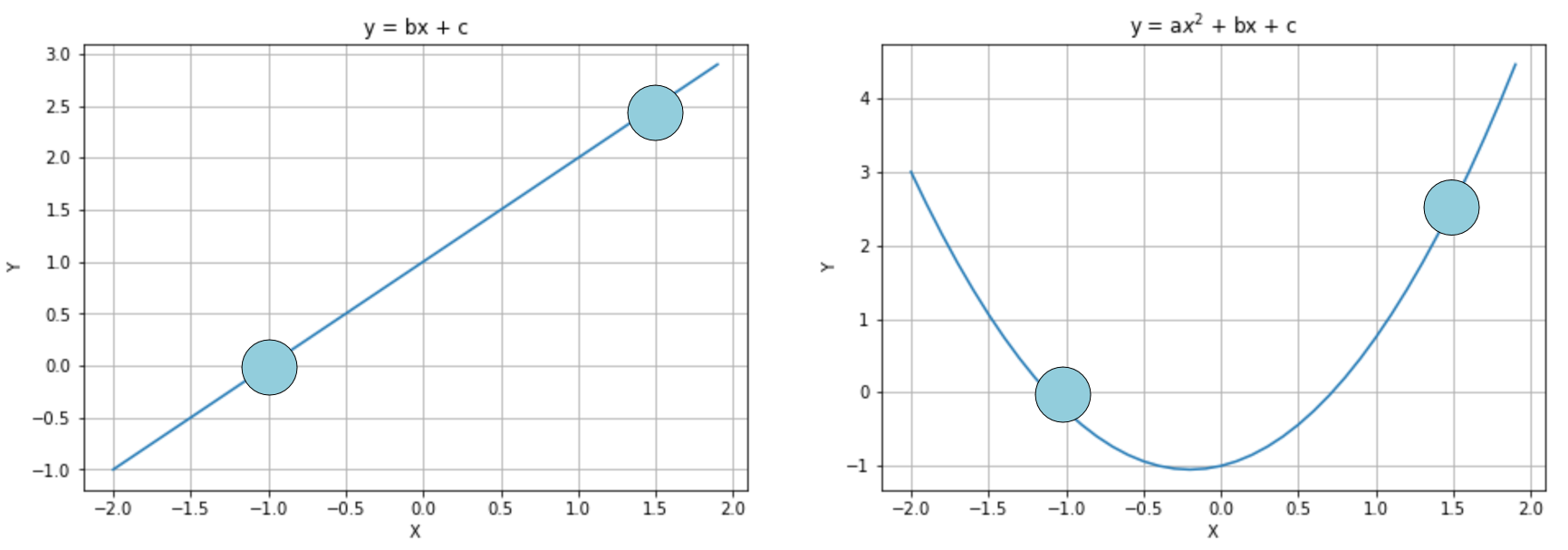
Interpolation with a linear curve (left) and a parabolic one (right)
In the first diagram, the model is linear and has two parameters, while in the second one, it is quadratic and has three parameters. We already know that the second option is more prone to overfitting, but if we apply a regularization term, it's possible to avoid the growth of a (first quadratic parameter), transforming the model into a linearized version. Of course, there's a difference between choosing a lower-capacity model and applying a regularization constraint. In fact, in the first case, we are renouncing the possibility offered by the extra capacity, running the risk of increasing the bias, while with regularization we keep the same model but optimize it so to reduce the variance. Let's now explore the most common regularization techniques.
Ridge
Ridge regularization (also known as Tikhonov regularization) is based on the squared L2-norm of the parameter vector:
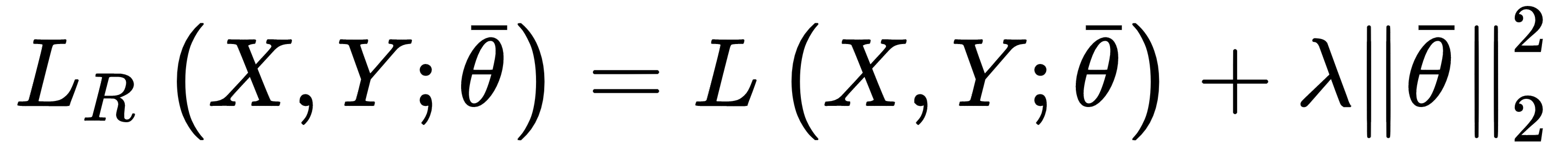
This penalty avoids an infinite growth of the parameters (for this reason, it's also known as weight shrinkage), and it's particularly useful when the model is ill-conditioned, or there is multicollinearity, due to the fact that the samples are completely independent (a relatively common condition).
In the following diagram, we see a schematic representation of the Ridge regularization in a bidimensional scenario:
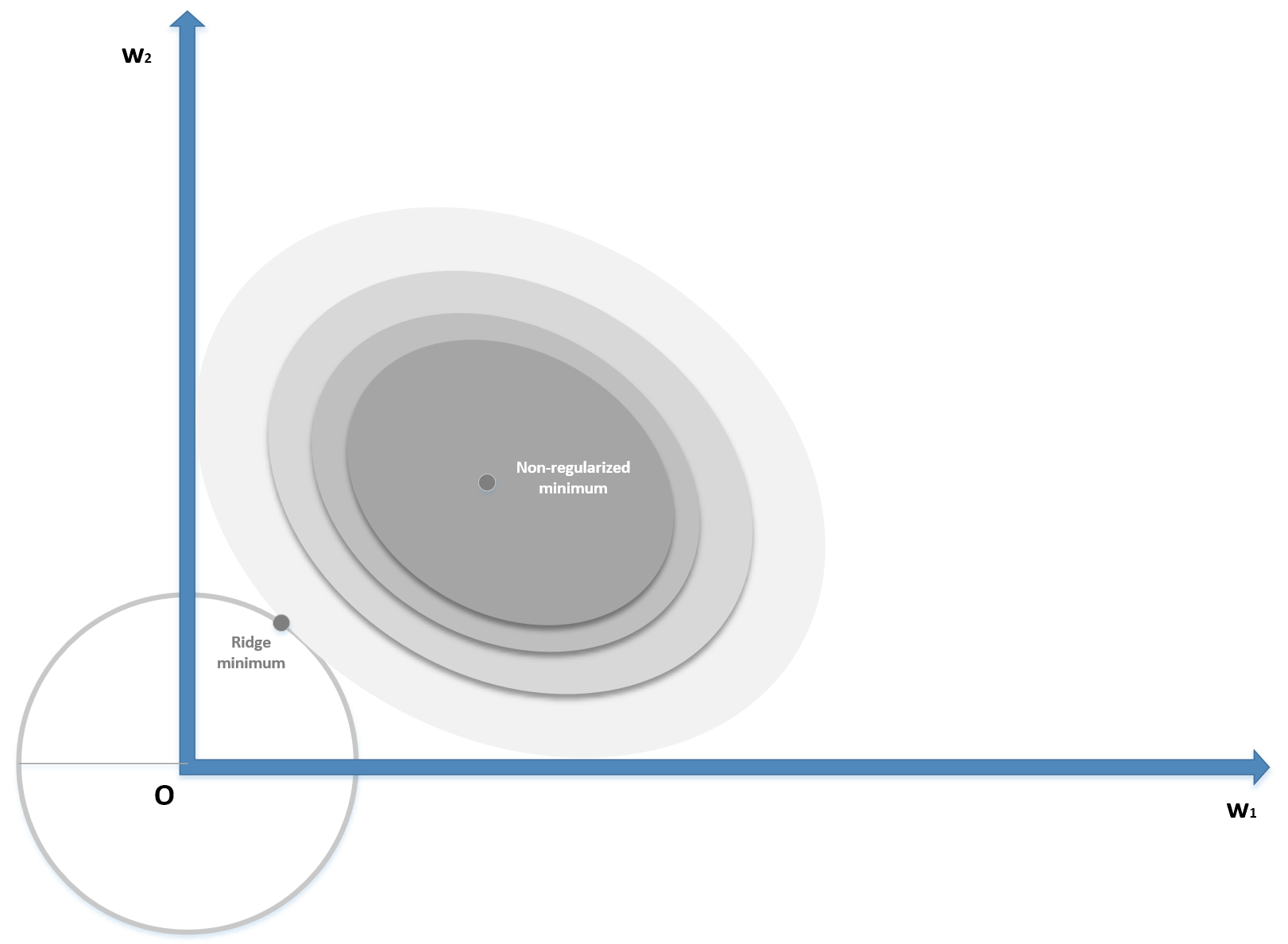
Ridge (L2) regularization
The zero-centered circle represents the Ridge boundary, while the shaded surface is the original cost function. Without regularization, the minimum (w1, w2) has a magnitude (for example, the distance from the origin) which is about double the one obtained by applying a Ridge constraint, confirming the expected shrinkage. When applied to regressions solved with the Ordinary Least Squares (OLS) algorithm, it's possible to prove that there always exists a Ridge coefficient, so that the weights are shrunk with respect the OLS ones. The same result, with some restrictions, can be extended to other cost functions.
Lasso
Lasso regularization is based on the L1-norm of the parameter vector:
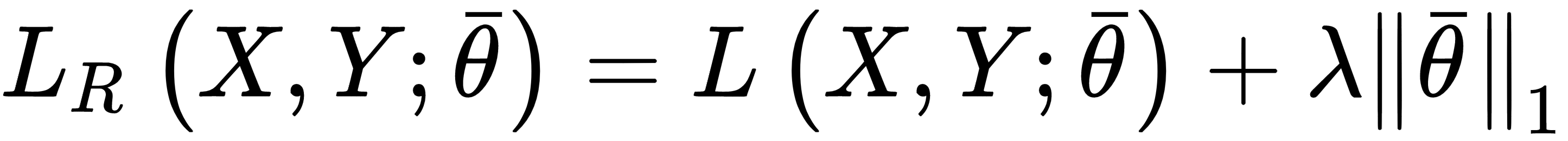
Contrary to Ridge, which shrinks all the weights, Lasso can shift the smallest one to zero, creating a sparse parameter vector. The mathematical proof is beyond the scope of this book; however, it's possible to understand it intuitively by considering the following diagram (bidimensional):
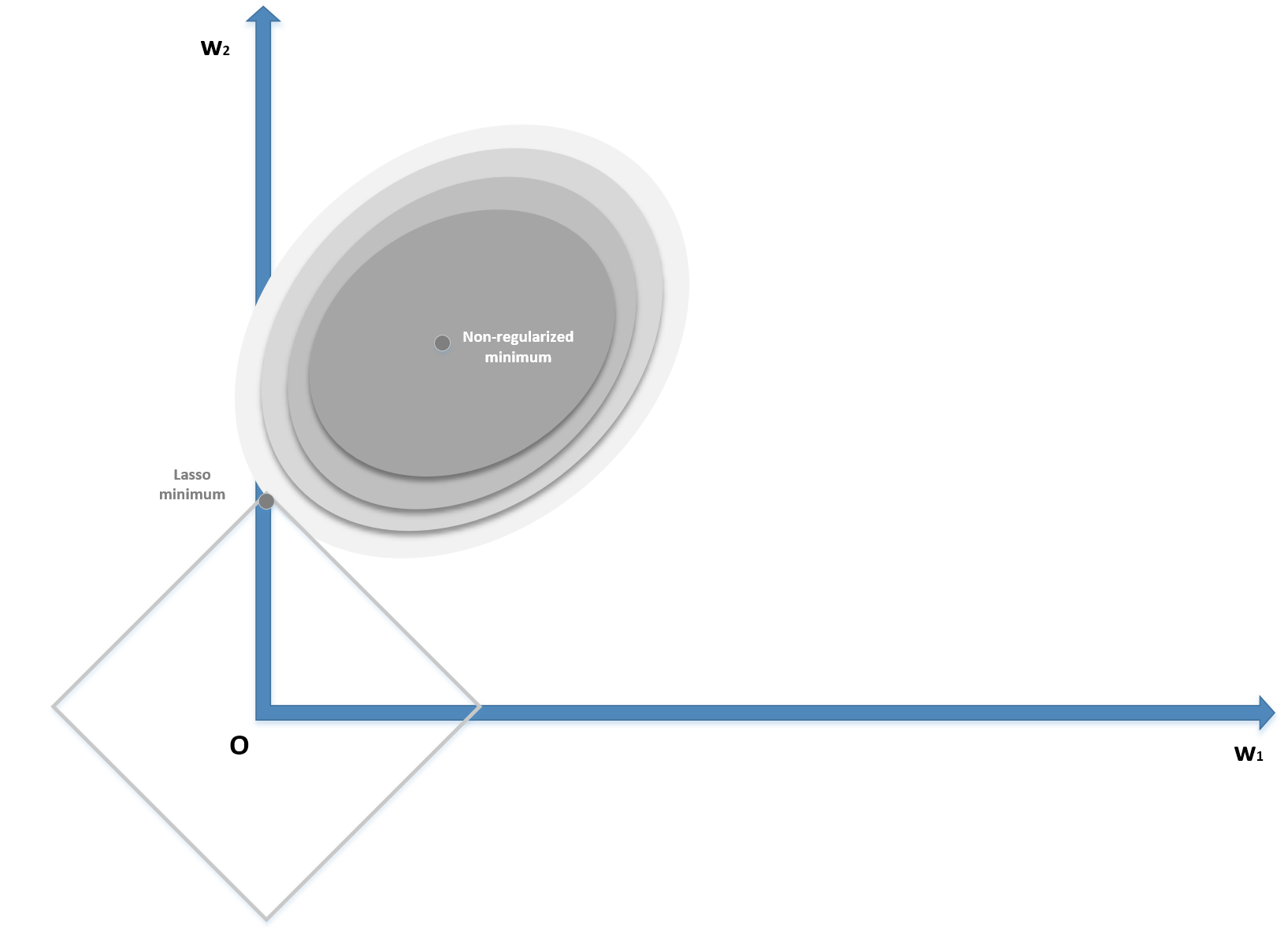
Lasso (L1) regularization
The zero-centered square represents the Lasso boundaries. If we consider a generic line, the probability of being tangential to the square is higher at the corners, where at least one (exactly one in a bidimensional scenario) parameter is null. In general, if we have a vectorial convex function f(x) (we provide a definition of convexity in Chapter 5, EM Algorithm and Applications), we can define:
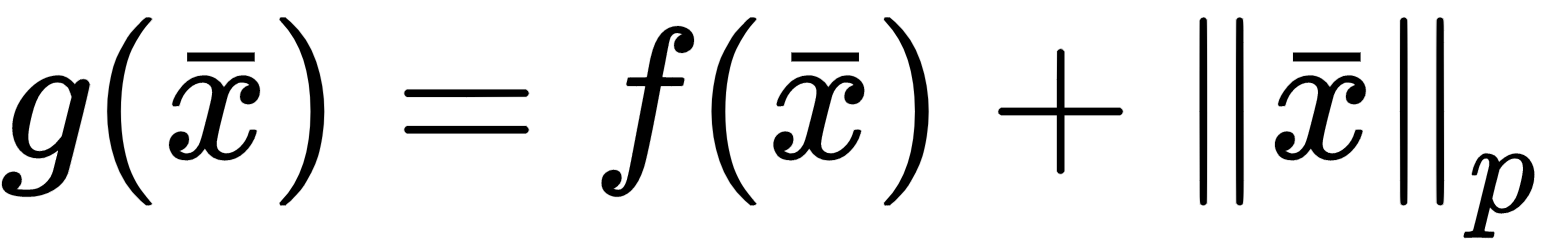
As any Lp-norm is convex, as well as the sum of convex functions, g(x) is also convex. The regularization term is always non-negative, therefore the minimum corresponds to the norm of the null vector. When minimizing g(x), we need to also consider the contribution of the gradient of the norm in the ball centered in the origin where, however, the partial derivatives don't exist. Increasing the value of p, the norm becomes smoothed around the origin, and the partial derivatives approach zero for |xi| → 0.
On the other side, with p=1 (excluding the L0-norm and all the norms with p ∈ ]0, 1[ that allow an even stronger sparsity, but are non-convex), the partial derivatives are always +1 or -1, according to the sign of xi (xi ≠ 0). Therefore, it's easier for the L1-norm to push the smallest components to zero, because the contribution to the minimization (for example, with a gradient descent) is independent of xi, while an L2-norm decreases its speed when approaching the origin. This is a non-rigorous explanation of the sparsity achieved using the L1-norm. In fact, we also need to consider the term f(x), which bounds the value of the global minimum; however, it may help the reader to develop an intuitive understanding of the concept. It's possible to find further and mathematically rigorous details in Optimization for Machine Learning, (edited by) Sra S., Nowozin S., Wright S. J., The MIT Press.
Lasso regularization is particularly useful whenever a sparse representation of a dataset is needed. For example, we could be interested in finding the feature vectors corresponding to a group of images. As we expect to have many features but only a subset present in each image, applying the Lasso regularization allows forcing all the smallest coefficients to become null, suppressing the presence of the secondary features. Another potential application is latent semantic analysis, where our goal is to describe the documents belonging to a corpus in terms of a limited number of topics. All these methods can be summarized in a technique called sparse coding, where the objective is to reduce the dimensionality of a dataset (also in non-linear scenarios) by extracting the most representative atoms, using different approaches to achieve sparsity.
ElasticNet
In many real cases, it's useful to apply both Ridge and Lasso regularization in order to force weight shrinkage and a global sparsity. It is possible by employing the ElasticNet regularization, defined as:
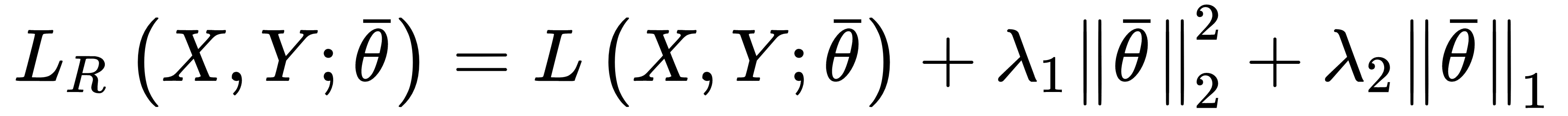
The strength of each regularization is controlled by the parameters λ1 and λ2. ElasticNet can yield excellent results whenever it's necessary to mitigate overfitting effects while encouraging sparsity. We are going to apply all the regularization techniques when discussing some deep learning architectures.
Early stopping
Even though it's a pure regularization technique, early stopping is often considered as a last resort when all other approaches to prevent overfitting and maximize validation accuracy fail. In many cases (above all, in deep learning scenarios), it's possible to observe a typical behavior of the training process considering both training and the validation cost functions:
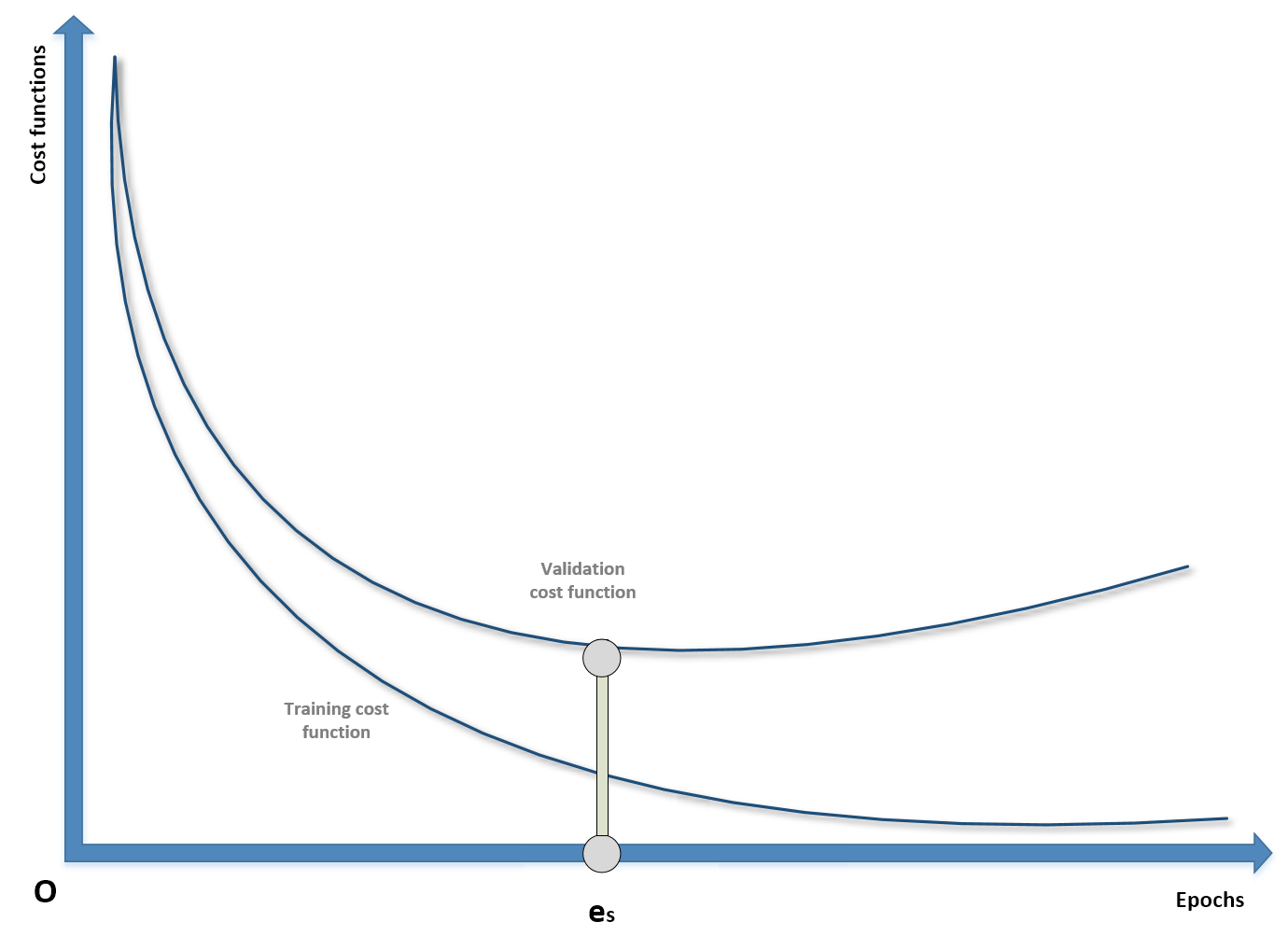
Example of early stopping before the beginning of ascending phase of U-curve
During the first epochs, both costs decrease, but it can happen that after a threshold epoch es, the validation cost starts increasing. If we continue with the training process, this results in overfitting the training set and increasing the variance. For this reason, when there are no other options, it's possible to prematurely stop the training process. In order to do so, it's necessary to store the last parameter vector before the beginning of a new iteration and, in the case of no improvements or the accuracy worsening, to stop the process and recover the last parameters. As explained, this procedure must never be considered as the best choice, because a better model or an improved dataset could yield higher performances. With early stopping, there's no way to verify alternatives, therefore it must be adopted only at the last stage of the process and never at the beginning. Many deep learning frameworks such as Keras include helpers to implement an early stopping callback; however, it's important to check whether the last parameter vector is the one stored before the last epoch or the one corresponding to es. In this case, it could be useful to repeat the training process, stopping it at the epoch previous to es (where the minimum validation cost has been achieved).


