






















































Inventory parsing and data sources
In Ansible, nothing happens without an inventory. Even ad hoc actions performed on localhost require an inventory, even if that inventory consists just of the localhost. The inventory is the most basic building block of Ansible architecture. When executing ansible or ansible-playbook, an inventory must be referenced. Inventories are either files or directories that exist on the same system that runs ansible or ansible-playbook. The location of the inventory can be referenced at runtime with the –inventory-file (-i) argument, or by defining the path in an Ansible config file.
Inventories can be static or dynamic, or even a combination of both, and Ansible is not limited to a single inventory. The standard practice is to split inventories across logical boundaries, such as staging and production, allowing an engineer to run a set of plays against their staging environment for validation, and then follow with the same exact plays run against the production inventory set.
Variable data, such as specific details on how to connect to a particular host in your inventory, can be included along with an inventory in a variety of ways as well, and we'll explore the options available to you.
The static inventory
The static inventory is the most basic of all the inventory options. Typically, a static inventory will consist of a single file in the ini format. Here is an example of a static inventory file describing a single host, mastery.example.name:
mastery.example.name
That is all there is to it. Simply list the names of the systems in your inventory. Of course, this does not take full advantage of all that an inventory has to offer. If every name were listed like this, all plays would have to reference specific host names, or the special all group. This can be quite tedious when developing a playbook that operates across different sets of your infrastructure. At the very least, hosts should be arranged into groups. A design pattern that works well is to arrange your systems into groups based on expected functionality. At first, this may seem difficult if you have an environment where single systems can play many different roles, but that is perfectly fine. Systems in an inventory can exist in more than one group, and groups can even consist of other groups! Additionally, when listing groups and hosts, it's possible to list hosts without a group. These would have to be listed first, before any other group is defined.
Let's build on our previous example and expand our inventory with a few more hosts and some groupings:
[web] mastery.example.name [dns] backend.example.name [database] backend.example.name [frontend:children] web [backend:children] dns database
What we have created here is a set of three groups with one system in each, and then two more groups, which logically group all three together. Yes, that's right; you can have groups of groups. The syntax used here is [groupname:children], which indicates to Ansible's inventory parser that this group by the name of groupname is nothing more than a grouping of other groups. The children in this case are the names of the other groups. This inventory now allows writing plays against specific hosts, low-level role-specific groups, or high-level logical groupings, or any combination.
By utilizing generic group names, such as dns and database, Ansible plays can reference these generic groups rather than the explicit hosts within. An engineer can create one inventory file that fills in these groups with hosts from a preproduction staging environment and another inventory file with the production versions of these groupings. The playbook content does not need to change when executing on either staging or production environment because it refers to the generic group names that exist in both inventories. Simply refer to the right inventory to execute it in the desired environment.
Inventory variable data
Inventories provide more than just system names and groupings. Data about the systems can be passed along as well. This can include:
- Host-specific data to use in templates
- Group-specific data to use in task arguments or conditionals
- Behavioral parameters to tune how Ansible interacts with a system
Variables are a powerful construct within Ansible and can be used in a variety of ways, not just the ways described here. Nearly every single thing done in Ansible can include a variable reference. While Ansible can discover data about a system during the setup phase, not all data can be discovered. Defining data with the inventory is how to expand the dataset. Note that variable data can come from many different sources, and one source may override another source. Variable precedence order is covered later in this chapter.
Let's improve upon our existing example inventory and add to it some variable data. We will add some host-specific data as well as group specific data:
[web] mastery.example.name ansible_ssh_host=192.168.10.25 [dns] backend.example.name [database] backend.example.name [frontend:children] web [backend:children] dns database [web:vars] http_port=88 proxy_timeout=5 [backend:vars] ansible_ssh_port=314 [all:vars] ansible_ssh_user=otto
In this example, we defined ansible_ssh_host for mastery.example.name to be the IP address of 192.168.10.25. An ansible_ssh_host is a behavioral inventory parameter, which is intended to alter the way Ansible behaves when operating with this host. In this case, the parameter instructs Ansible to connect to the system using the provided IP address rather than performing a DNS lookup on the name mastery.example.name. There are a number of other behavioral inventory parameters, which are listed at the end of this section along with their intended use.
Our new inventory data also provides group level variables for the web and backend groups. The web group defines http_port, which may be used in an nginx configuration file, and proxy_timeout, which might be used to determine HAProxy behavior. The backend group makes use of another behavioral inventory parameter to instruct Ansible to connect to the hosts in this group using port 314 for SSH, rather than the default of 22.
Finally, a construct is introduced that provides variable data across all the hosts in the inventory by utilizing a built-in all group. Variables defined within this group will apply to every host in the inventory. In this particular example, we instruct Ansible to log in as the otto user when connecting to the systems. This is also a behavioral change, as the Ansible default behavior is to log in as a user with the same name as the user executing ansible or ansible-playbook on the control host.
Here is a table of behavior inventory parameters and the behavior they intend to modify:
Inventory parameters | Behaviour |
|---|---|
| This is the name of the host to connect to, if different from the alias you wish to give to it. |
| This is the SSH port number, if not |
| This is the default SSH username to use. |
| This is the SSH password to use (this is insecure, we strongly recommend using |
| This is the sudo password to use (this is insecure, we strongly recommend using |
| This is the sudo command path. |
| This is the connection type of the host. Candidates are local, smart, ssh, or paramiko. The default is paramiko before Ansible 1.2, and smart afterwards, which detects whether the usage of ssh will be feasible based on whether the ssh feature ControlPersist is supported |
| This is the private key file used by SSH. This is useful if you use multiple keys and you don't want to use SSH agent |
| This is the shell type of the target system. By default, commands are formatted using the |
| This is the target host Python path. This is useful for systems with more than one Python, systems that are not located at |
| This works for anything such as Ruby or Perl and works just like |
Dynamic inventories
A static inventory is great and enough for many situations. But there are times when a statically written set of hosts is just too unwieldy to manage. Consider situations where inventory data already exists in a different system, such as LDAP, a cloud computing provider, or an in-house CMDB (inventory, asset tracking, and data warehousing) system. It would be a waste of time and energy to duplicate that data, and in the modern world of on-demand infrastructure, that data would quickly grow stale or disastrously incorrect.
Another example of when a dynamic inventory source might be desired is when your site grows beyond a single set of playbooks. Multiple playbook repositories can fall into the trap of holding multiple copies of the same inventory data, or complicated processes have to be created to reference a single copy of the data. An external inventory can easily be leveraged to access the common inventory data stored outside of the playbook repository to simplify the setup. Thankfully, Ansible is not limited to static inventory files.
A dynamic inventory source (or plugin) is an executable script that Ansible will call at runtime to discover real-time inventory data. This script may reach out into external data sources and return data, or it can just parse local data that already exists but may not be in the Ansible inventory ini format. While it is possible and easy to develop your own dynamic inventory source, which we will cover in a later chapter, Ansible provides a number of example inventory plugins, including but not limited to:
- OpenStack Nova
- Rackspace Public Cloud
- DigitalOcean
- Linode
- Amazon EC2
- Google Compute Engine
- Microsoft Azure
- Docker
- Vagrant
Many of these plugins require some level of configuration, such as user credentials for EC2 or authentication endpoint for OpenStack Nova. Since it is not possible to configure additional arguments for Ansible to pass along to the inventory script, the configuration for the script must either be managed via an ini config file read from a known location, or environment variables read from the shell environment used to execute ansible or ansible-playbook.
When ansible or ansible-playbook is directed at an executable file for an inventory source, Ansible will execute that script with a single argument, --list. This is so that Ansible can get a listing of the entire inventory in order to build up its internal objects to represent the data. Once that data is built up, Ansible will then execute the script with a different argument for every host in the data to discover variable data. The argument used in this execution is --host <hostname>, which will return any variable data specific to that host.
In Chapter 8, Extending Ansible, we will develop our own custom inventory plugin to demonstrate how they operate.
Run-time inventory additions
Just like static inventory files, it is important to remember that Ansible will parse this data once, and only once, per ansible or ansible-playbook execution. This is a fairly common stumbling point for users of cloud dynamic sources, where frequently a playbook will create a new cloud resource and then attempt to use it as if it were part of the inventory. This will fail, as the resource was not part of the inventory when the playbook launched. All is not lost though! A special module is provided that allows a playbook to temporarily add inventory to the in-memory inventory object, the add_host module.
The add_host module takes two options, name and groups. The name should be obvious, it defines the hostname that Ansible will use when connecting to this particular system. The groups option is a comma-separated list of groups to add this new system to. Any other option passed to this module will become the host variable data for this host. For example, if we want to add a new system, name it newmastery.example.name, add it to the web group, and instruct Ansible to connect to it by way of IP address 192.168.10.30, we will create a task like this:
- name: add new node into runtime inventory
add_host:
name: newmastery.example.name
groups: web
ansible_ssh_host: 192.168.10.30This new host will be available to use, by way of the name provided, or by way of the web group, for the rest of the ansible-playbook execution. However, once the execution has completed, this host will not be available unless it has been added to the inventory source itself. Of course, if this were a new cloud resource created, the next ansible or ansible-playbook execution that sourced inventory from that cloud would pick up the new member.
Inventory limiting
As mentioned earlier, every execution of ansible or ansible-playbook will parse the entire inventory it has been directed at. This is even true when a limit has been applied. A limit is applied at run time by making use of the --limit runtime argument to ansible or ansible-playbook. This argument accepts a pattern, which is basically a mask to apply to the inventory. The entire inventory is parsed, and at each play the supplied limit mask further limits the host pattern listed for the play.
Let's take our previous inventory example and demonstrate the behavior of Ansible with and without a limit. If you recall, we have the special group all that we can use to reference all the hosts within an inventory. Let's assume that our inventory is written out in the current working directory in a file named mastery-hosts, and we will construct a playbook to demonstrate the host on which Ansible is operating. Let's write this playbook out as mastery.yaml:
---
- name: limit example play
hosts: all
gather_facts: false
tasks:
- name: tell us which host we are on
debug:
var: inventory_hostnameThe debug module is used to print out text, or values of variables. We'll use this module a lot in this book to simulate actual work being done on a host.
Now, let's execute this simple playbook without supplying a limit. For simplicity's sake, we will instruct Ansible to utilize a local connection method, which will execute locally rather than attempting to SSH to these nonexistent hosts. Let's take a look at the following screenshot:

As we can see, both hosts backend.example.name and mastery.example.name were operated on. Let's see what happens if we supply a limit, specifically to limit our run to only frontend systems:
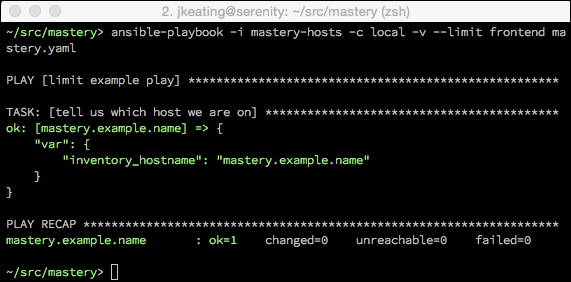
We can see that only mastery.example.name was operated on this time. While there are no visual clues that the entire inventory was parsed, if we dive into the Ansible code and examine the inventory object, we will indeed find all the hosts within, and see how the limit is applied every time the object is queried for items.
It is important to remember that regardless of the host's pattern used in a play, or the limit supplied at runtime, Ansible will still parse the entire inventory set during each run. In fact, we can prove this by attempting to access host variable data for a system that would otherwise be masked by our limit. Let's expand our playbook slightly and attempt to access the ansible_ssh_port variable from backend.example.name:
---
- name: limit example play
hosts: all
gather_facts: false
tasks:
- name: tell us which host we are on
debug:
var: inventory_hostname
- name: grab variable data from backend
debug:
var: hostvars['backend.example.name']['ansible_ssh_port']We will still apply our limit, which will restrict our operations to just mastery.example.name:

We have successfully accessed the host variable data (by way of group variables) for a system that was otherwise limited out. This is a key skill to understand, as it allows for more advanced scenarios, such as directing a task at a host that is otherwise limited out. Delegation can be used to manipulate a load balancer to put a system into maintenance mode while being upgraded without having to include the load balancer system in your limit mask.
