Assume that we have a dataset,  , so that we can express the linear relation between y and x with mathematical formula in the following way:
, so that we can express the linear relation between y and x with mathematical formula in the following way:
Here, p is the dimension of the independent variable, and T denotes the transpose, so that 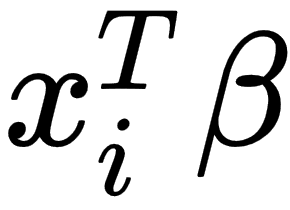 is the inner product between vectors
is the inner product between vectors 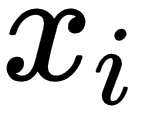 and β. Also, we can rewrite the previous expression in matrix notation, as follows:
and β. Also, we can rewrite the previous expression in matrix notation, as follows:
The preceding matrix notation can be explained as follows:
- y: This is a vector of observed target values.
- x: This is a matrix of row-vectors,
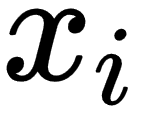 , which are known as explanatory or independent values.
, which are known as explanatory or independent values.
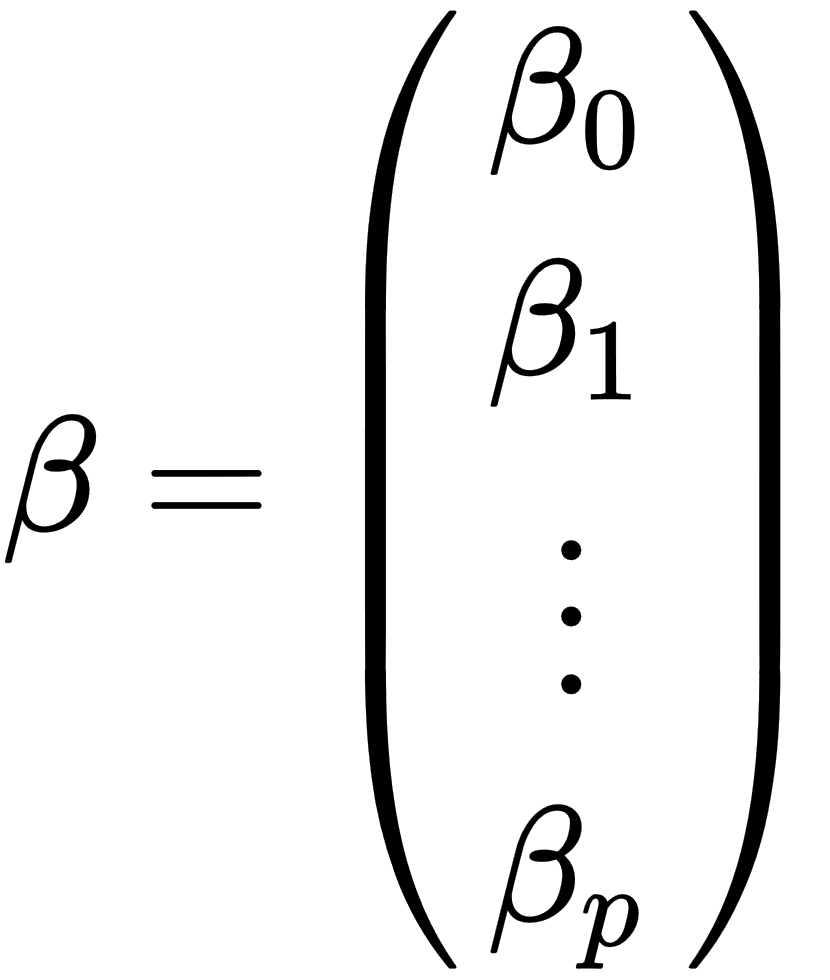
- ß: This is a (p+1) dimensional parameters vector.
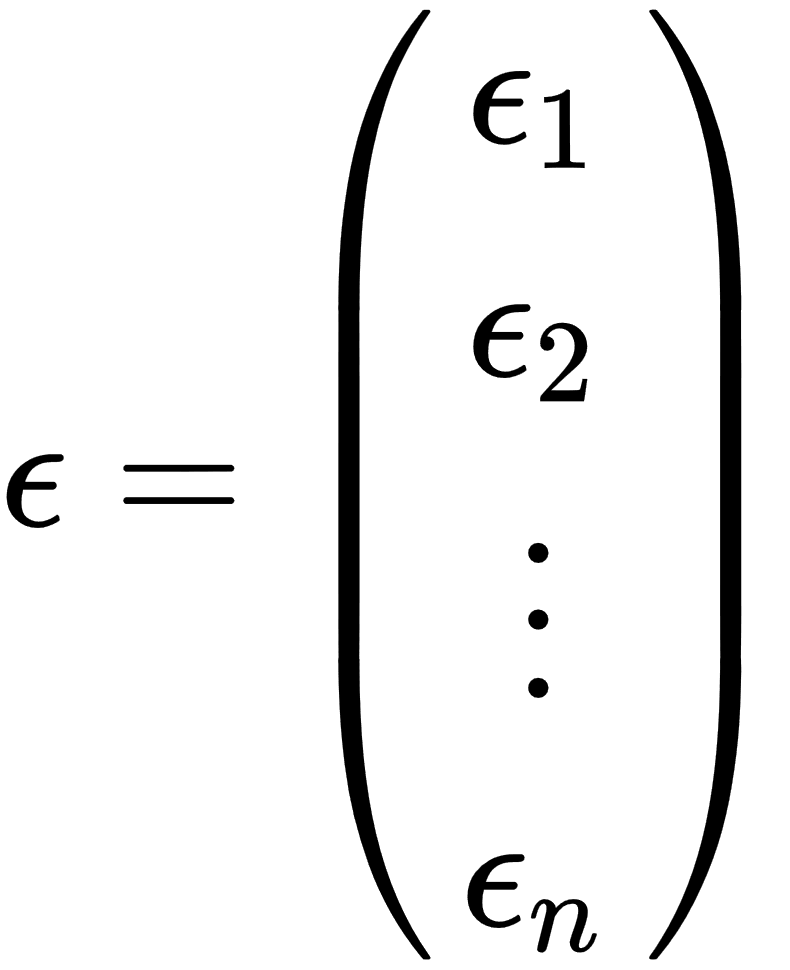
- ε: This is called an error term or noise. This variable captures all other factors that influence the y dependent variable other than the regressors.
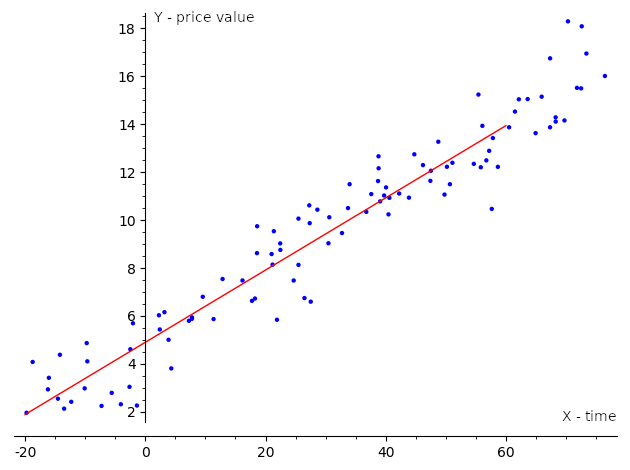
When we are considering simple linear regression, p is equal to 1, and the equation will look like this:
The goal of the linear regression task is to find parameter vectors that satisfy the previous equation. Usually, there is no exact solution to such a system of linear equations, so the task is to estimate parameters that satisfy these equations with some assumptions. One of the most popular estimation approaches is one based on the principle of least squares: minimizing the sum of the squares of the differences between the observed dependent variable in the given dataset and those predicted by the linear function. This is called the ordinary least squares (OLS) estimator. So, the task can be formulated with the following formula:
In the preceding formula, the objective function S is given by the following matrix notation:
This minimization problem has a unique solution, in the case that the p columns of the x matrix are linearly independent. We can get this solution by solving the normal equation, as follows:
Linear algebra libraries can solve such equations directly with an analytical approach, but it has one significant disadvantage—computational cost. In the case of large dimensions of y and x, requirements for computer memory amount and computational time are too big to solve real-world tasks.
So, usually, this minimization task is solved with iterative approaches. Gradient descent (GD) is an example of such an algorithm. GD is a technique based on the observation that if the function 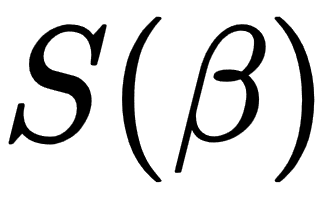 is defined and is differentiable in a neighborhood of a point
is defined and is differentiable in a neighborhood of a point 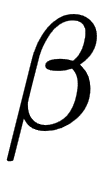 , then
, then 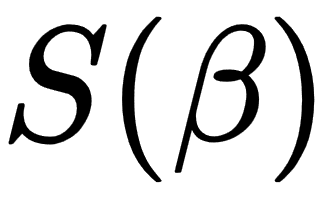 decreases fastest when it goes in the direction of the negative gradient of S at the point
decreases fastest when it goes in the direction of the negative gradient of S at the point 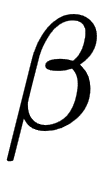 .
.
We can change our 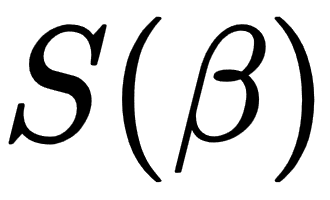 objective function to a form more suitable for an iterative approach. We can use the mean squared error (MSE) function, which measures the difference between the estimator and the estimated value, as illustrated here:
objective function to a form more suitable for an iterative approach. We can use the mean squared error (MSE) function, which measures the difference between the estimator and the estimated value, as illustrated here:
In the case of the multiple regression, we take partial derivatives for this function for each of x components, as follows:
So, in the case of the linear regression, we take the following derivatives:
The whole algorithm has the following description:
- Initialize β with zeros.
- Define a value for the learning rate parameter that controls how much we are adjusting parameters during the learning procedure.
- Calculate the following values of β:
- Repeat steps 1-3 for a number of times or until the MSE value reaches a reasonable amount.
The previously described algorithm is one of the simplest supervised ML algorithms. We described it with the linear algebra concepts we introduced earlier in the chapter. Later, it became more evident that almost all ML algorithms use linear algebra under the hood. The following samples show the higher-level API in different linear algebra libraries for solving the linear regression task, and we provide them to show how libraries can simplify the complicated math used underneath. We will give the details of the APIs used in these samples in the following chapters.























































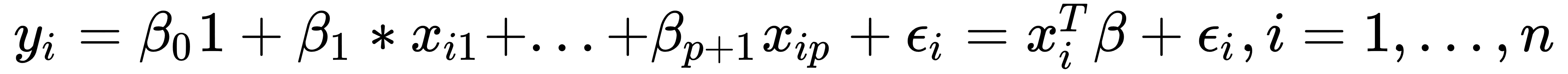
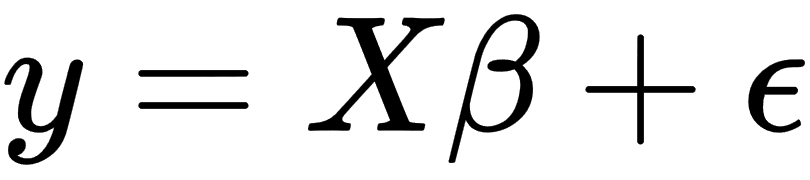
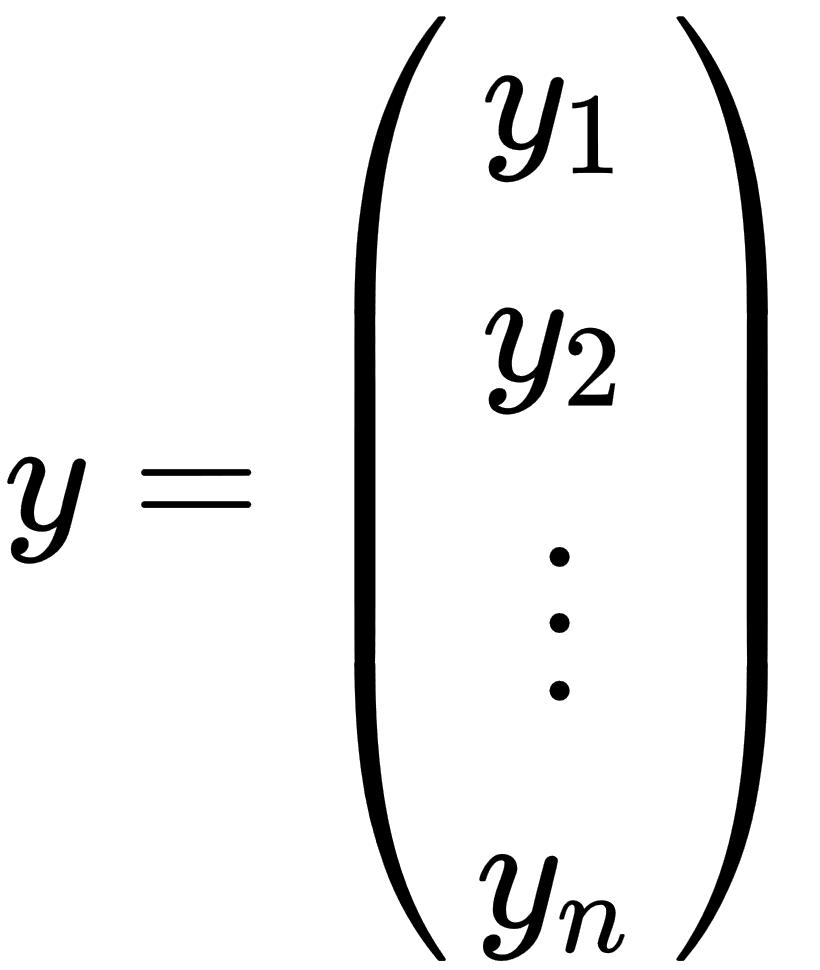 ,
,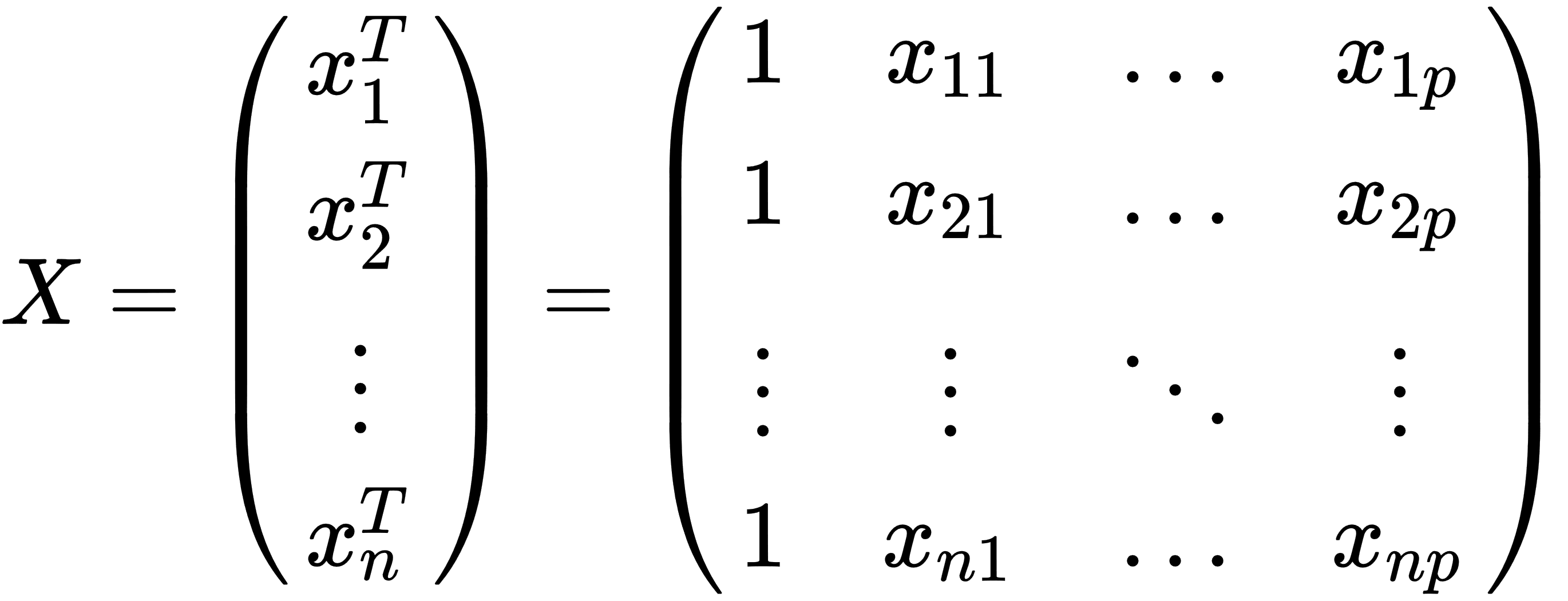 ,
, ,
,
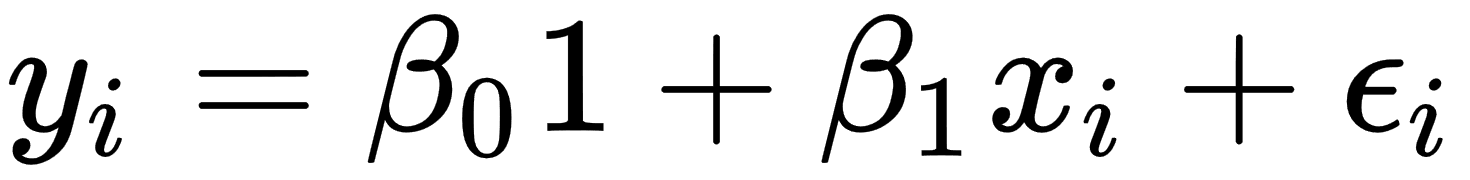
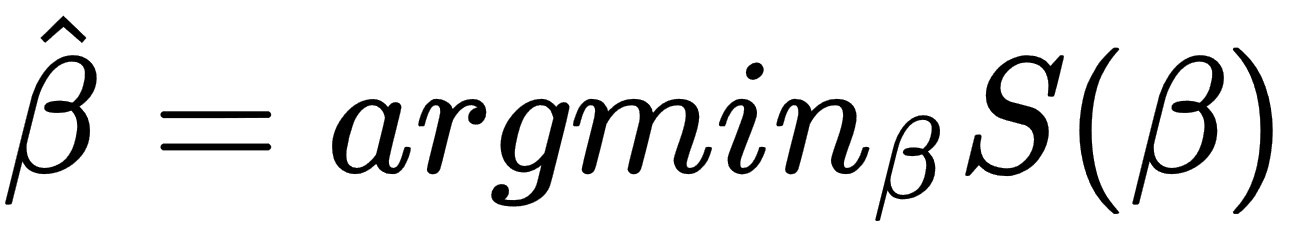
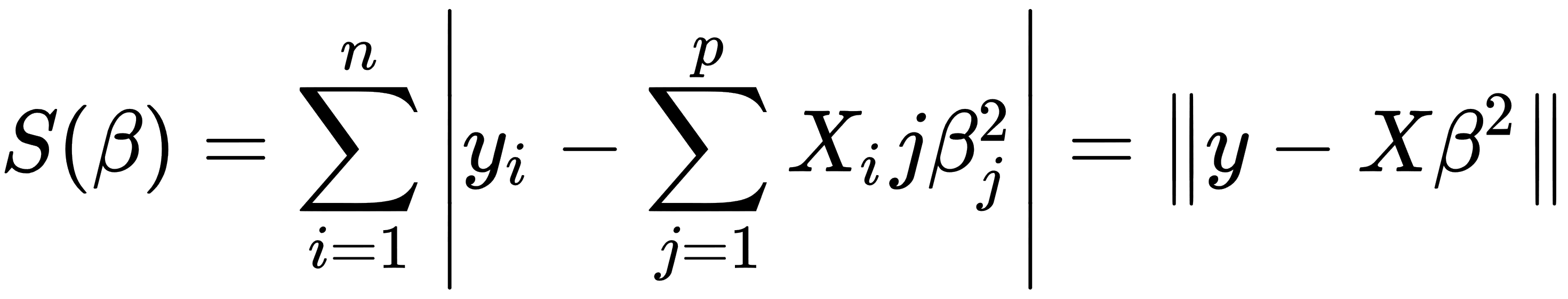
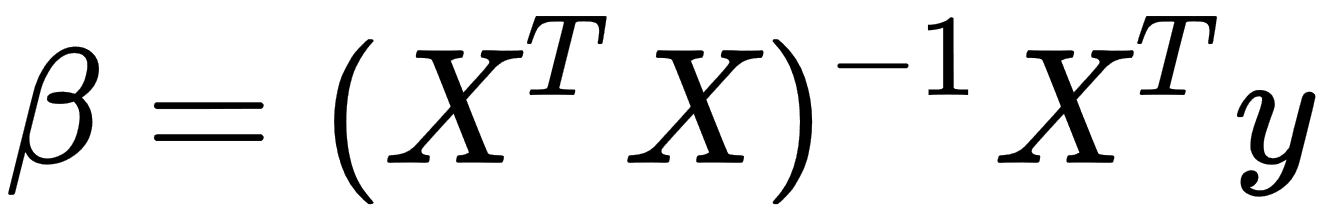
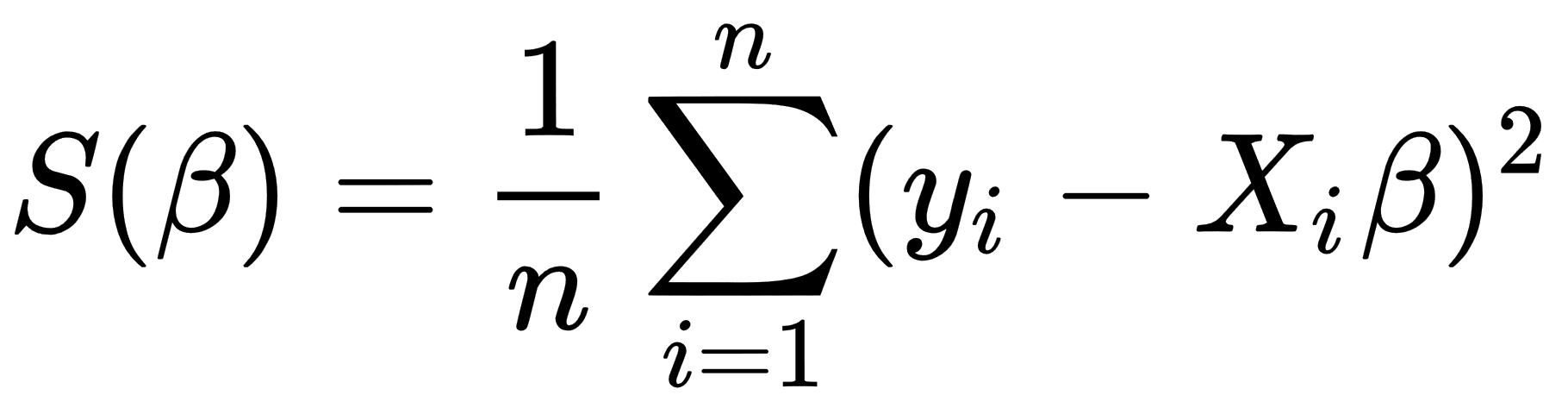
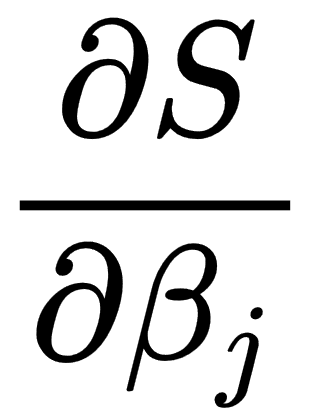
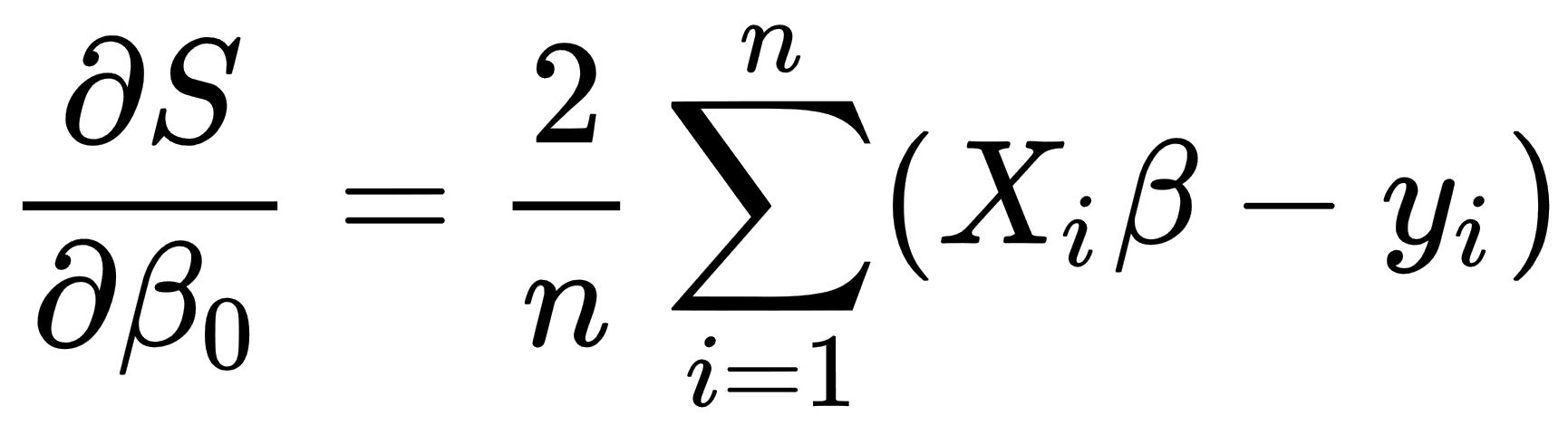
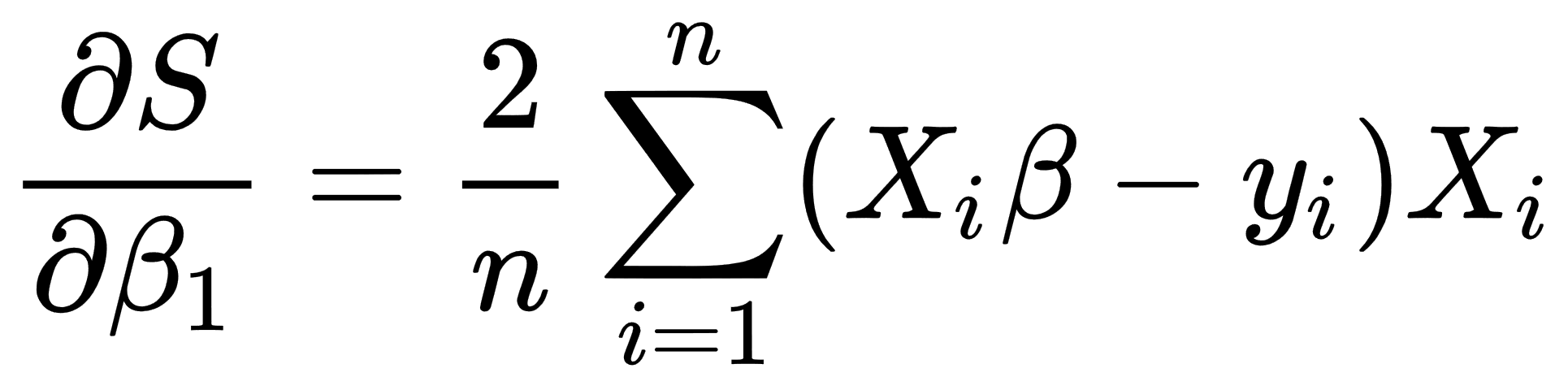
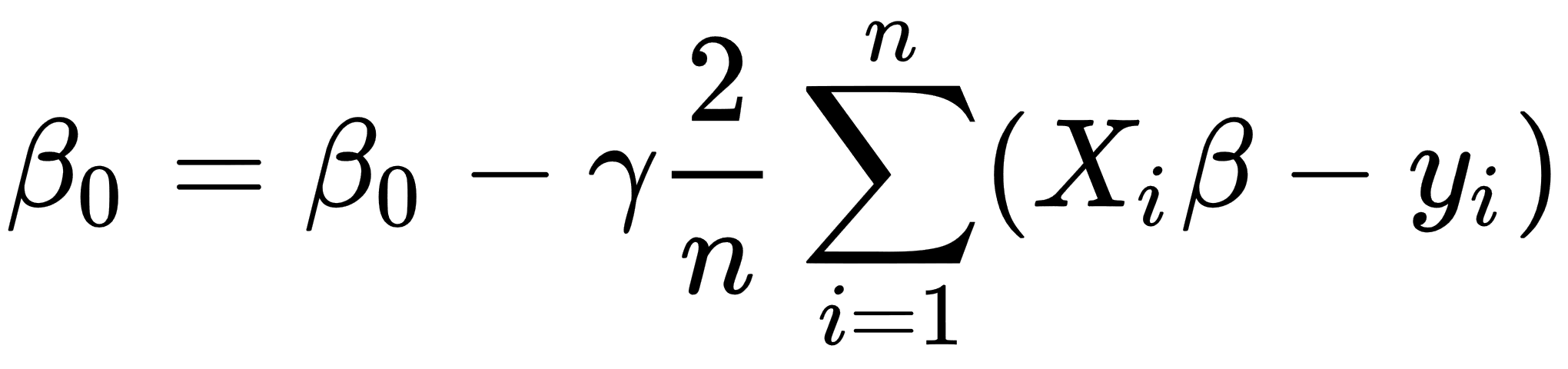
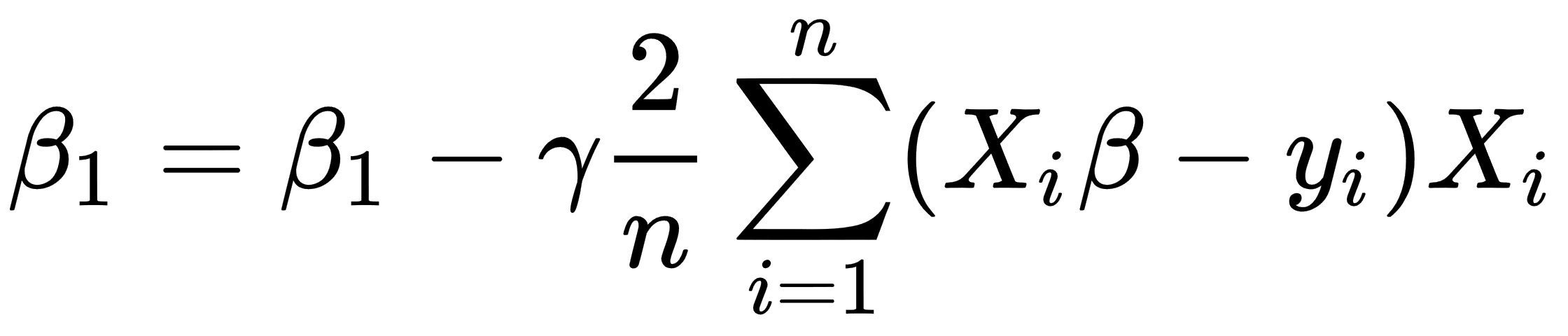
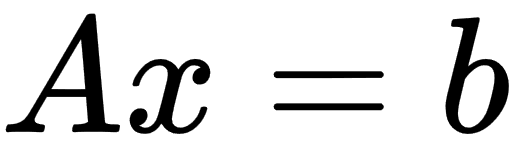 form in the Eigen library. The LeastSquaresConjugateGradient class is one of them, which allows us to solve linear regression problems with the conjugate gradient algorithm. The ConjugateGradient algorithm can converge more quickly to the function's minimum than regular GD but requires that matrix A is positively defined to guarantee numerical stability. The LeastSquaresConjugateGradient class
form in the Eigen library. The LeastSquaresConjugateGradient class is one of them, which allows us to solve linear regression problems with the conjugate gradient algorithm. The ConjugateGradient algorithm can converge more quickly to the function's minimum than regular GD but requires that matrix A is positively defined to guarantee numerical stability. The LeastSquaresConjugateGradient class 





















