






















































Imagination augmented agents
Are you a fan of chess? If I asked you to play chess, how would you play it? Before moving any chess piece on the chessboard, you might imagine the consequences of moving a chess piece and move the chess piece that you think would help you to win the game. So, basically, before taking any action, we imagine the consequence and, if it is favorable, we proceed with that action, else we refrain from performing that action.
Similarly, Imagination Augmented Agents (I2As) are augmented with imagination. Before taking any action in an environment, the agent imagines the consequences of taking the action and if they think the action will provide a good reward, they will perform the action. The I2A takes advantage of both model-based and model-free learning. Figure 17.8 shows the architecture of I2As:
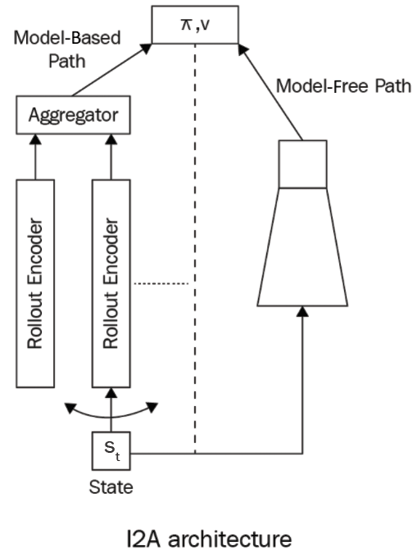
Figure 17.8: I2A architecture
As we can observe from Figure 17.8, I2A architecture has both model-based and model-free paths. Thus, the action...























