






















































Introduction
Machine learning is the science of utilizing machines to emulate human tasks and to have the machine improve their performance of that task over time. By feeding machines data in the form of observations of real-world events, they can develop patterns and relationships that will optimize an objective function, such as the accuracy of a binary classification task or the error in a regression task. In general, the usefulness of machine learning is in the ability to learn highly complex and non-linear relationships in large datasets and to replicate the results of that learning many times.
Take, for example, the classification of a dataset of pictures of either dogs or cats into classes of their respective type. For a human, this is trivial, and the accuracy would likely be very high. However, it may take around a second to categorize each picture, and scaling the task can only be achieved by increasing the number of humans, which may be infeasible. While it may be difficult, though certainly not impossible, for machines to reach the same level of accuracy as humans for this task, machines can classify many images per second, and scaling can be easily done by increasing the processing power of single machine, or making the algorithm more efficient.

Figure 1.1: A trivial classification task for humans, but quite difficult for machines
While the trivial task of classifying dogs and cats may be simple for us humans, the same principles that are used to create a machine learning model classify dogs and cats can be applied to other classification tasks that humans may struggle with. An example of this is identifying tumors in Magnetic Resonance Images (MRIs). For humans, this task requires a medical professional with years of experience, whereas a machine may only need a dataset of labeled images.
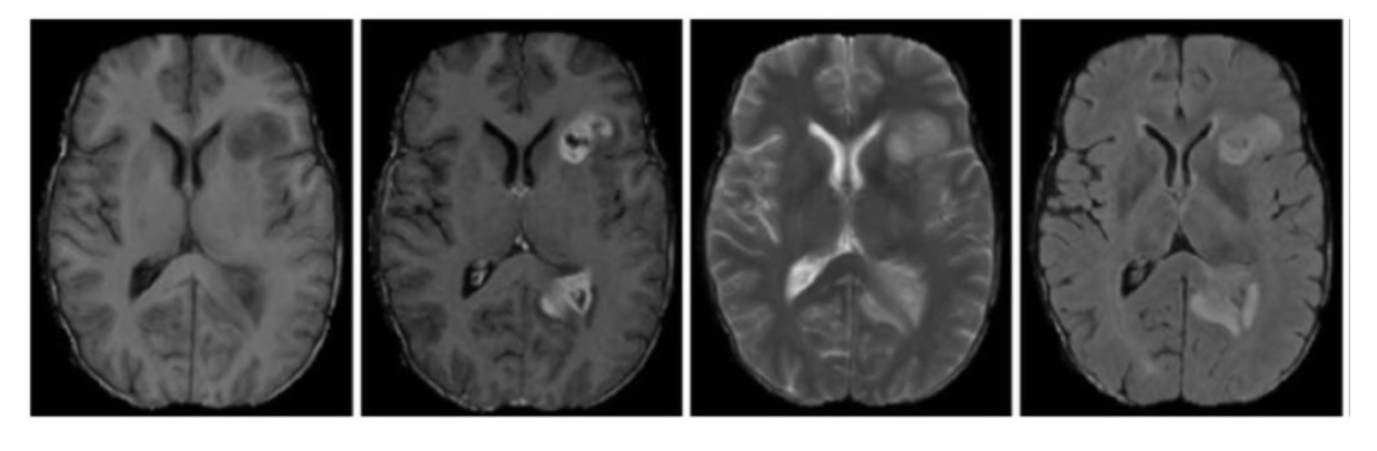
Figure 1.2: A non-trivial classification task for humans. Are you able to spot the tumors?






