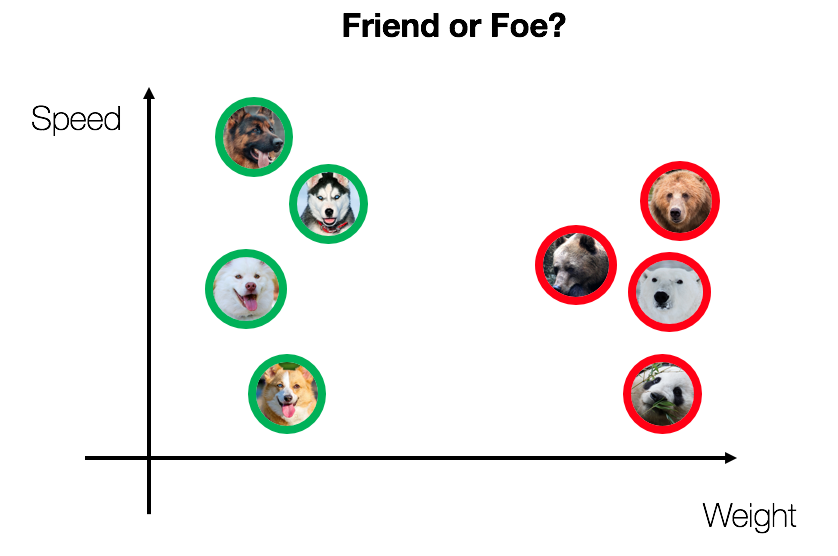
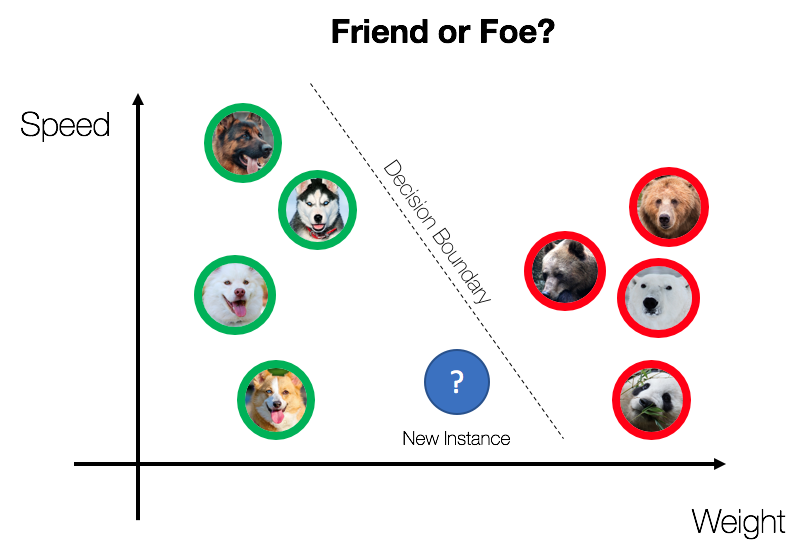
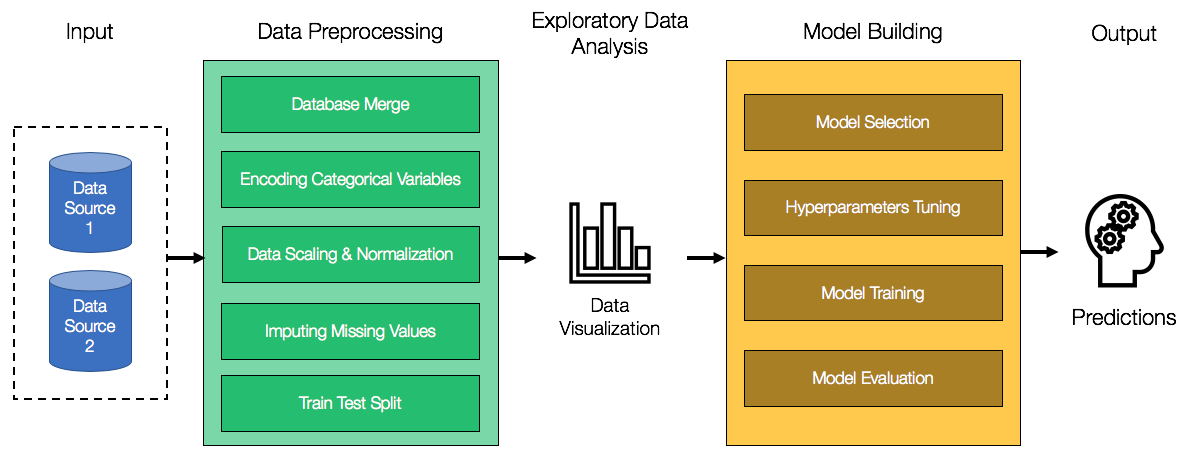
We have discussed what machine learning is. But how exactly do you do machine learning? At a high level, machine learning projects are all about taking in raw data as input and churning out Predictions as Output. To do that, there are several important intermediate steps that must be accomplished. This machine learning workflow can be summarized by the following diagram:
The Input to our machine learning workflow will always be data. Data can come from different sources, with different data formats. For example, if we are working on a computer vision-based project, then our data will likely be images. For most other machine learning projects, the data will be presented in a tabular form, similar to spreadsheets. In some machine learning projects, data collection will be a significant first step. In this book, we will assume that the data will be provided to us, allowing us to focus on the machine learning aspect.
The next step is to preprocess the data. Raw data is often messy, error-prone, and unsuitable for machine learning algorithms. Hence, we need to preprocess the data before we feed it to our models. In cases where data is provided from multiple sources, we need to merge the data into a single dataset. Machine learning models also require a numeric dataset for training purposes. If there are any categorical variables in the raw dataset (that is, gender, country, day of week, and so on), we need to encode those variables as numeric variables. We will see how we can do so later on in the chapter. Data scaling and normalization is also required for certain machine learning algorithms. The intuition behind this is that if the magnitude of certain variables is much greater than other variables, then certain machine learning algorithms will mistakenly place more emphasis on those dominating variables.
Real-world datasets are often messy. You will find that the data is incomplete and contains missing data in several rows and columns. There are several ways to deal with missing data, each with its own advantages and disadvantages. The easiest way is to simply discard rows and columns with missing data. However, this may not be practical, as we may end up discarding a significant percentage of our data. We can also replace the missing variables with the mean of the variables (if the variables happen to be numeric). This approach is more ideal than discarding data, as it preserves our dataset. However, replacing missing values with the mean tends to affect the distribution of the data, which may negatively impact our machine learning models. One other method is to predict what the missing values are, based on other values that are present. However, we have to be careful as doing this may introduce significant bias into our dataset.
Lastly, in Data Preprocessing, we need to split the dataset into a training and testing dataset. Our machine learning models will be trained and fitted only on the training set. Once we are satisfied with the performance of our model, we will then evaluate our model using the testing dataset. Note that our model should never be trained on the testing set. This ensures that the evaluation of model performance is unbiased, and will reflect its real-world performance.
Once Data Preprocessing has been completed, we will move on to Exploratory Data Analysis (EDA). EDA is the process of uncovering insights from your data using data visualization. EDA allows us to construct new features (known as feature engineering) and inject domain knowledge into our machine learning models.
Finally, we get to the heart of machine learning. After Data Preprocessing and EDA have been completed, we move on to Model Building. As mentioned in the earlier section, there are several machine learning algorithms at our disposal, and the nature of the problem should dictate the type of machine learning algorithm used. In this book, we will focus on neural networks. In Model Building, Hyperparameter Tuning is an essential step, and the right hyperparameters can drastically improve the performance of our model. In a later section, we will look at some of the hyperparameters in a neural network. Once the model has been trained, we are finally ready to evaluate our model using the testing set.
As we can see, the machine learning workflow consists of many intermediate steps, each of which are crucial to the overall performance of our model. The major advantage of using Python for machine learning is that the entire machine learning workflow can be executed end-to-end entirely in Python, using just a handful of open source libraries. In this book, you will gain experience using Python in each step of the machine learning workflow, as you create sophisticated neural network projects from scratch.