






















































Hello World in KNIME
As you put together your first workflow, you will learn how to interact with KNIME's user interface to connect, configure, and execute nodes: this is the bread and butter of any KNIME user, which you are about to become.
The title of this section is a thing for geeks: in fact, when you learn a new programming language, "Hello, World!" is the first program you get to write. It is very simple and is meant to illustrate the basic syntax of a language.
Let's imagine we have a simple and repetitive data operation to perform regularly: every day we receive a text file in Comma-Separated Value (CSV) format, which reports the cumulative sales generated by country in the year to date. The original file has some unnecessary columns and the order of rows is random. We need to apply some basic transformation steps so that we end up with a simple table showing just two columns: one is the name of the country and the other the amount of generated sales. We also want the rows to be sorted by decreasing sales. Lastly, we need to convert the file into Excel as it is a format that's easier to read for our colleagues. We can build a KNIME workflow that does exactly that once, in a way that we don't need to repeat the tedious task manually every day. Let's open KNIME Analytics Platform and build our time-saving workflow.
To keep our workflows tidy, we can organize them hierarchically, in folders: in KNIME, folders are called Workflow Groups. So, let's start by creating a workflow group that will host our first piece of work:
- Right-click on the LOCAL entry in the KNIME Explorer section (top-left) and then click on New Workflow Group... in the pop-up menu.
- Enter the name of your new folder (you can call it
Chapter 2) and click on Finish:
Figure 2.5: Creating a Workflow Group in KNIME: keep your work tidy by organizing it in folders
You will see that the new folder has appeared in your local workspace. Now we can finally create a new workflow within this group. Similar to what you just did when creating a group, you just need to follow a few more steps:
- Right-click on the newly created workflow group and then on New KNIME Workflow....
- Enter the name of your new workflow (how about
Hello World?) and then click Finish. Your workflow will appear in the editor, which at this point will look like a sheet of squared paper. - It's time to load our CSV file into KNIME, using the proper input node. The fastest way to do so is to drag and drop the file directly into the Workflow Editor: just grab the file named
raw_sales_country.csvfrom the folder where it is located and drop it anywhere on the blank editor. KNIME will recognize the type of file and automatically implement the right node for reading it: in this case, CSV Reader. As you drop the file, its configuration dialog will appear. If at any point you need to revise its configuration, you can just double-click on the node to obtain the same dialog.Like we will do every time we meet a new KNIME node on our journey, let's quickly discover how it works and how to configure it.
 CSV Reader
CSV Reader
This node (available in the repository under the path IO > Reader) reads data from a text file stored in a CSV format and makes it available as a table in KNIME. This node is pretty handy: it attempts to detect the format of the file and recognizes the type of data stored in each column, allowing you to manually change it if needed. It also lets you run some basic reformatting on the fly, like changing the names of columns. As you see in Figure 2.6, its configuration window displays multiple tabs, whose headers appear at the top. The first tab (Settings) lets you set the fundamentals:
- In the first section at the top, you can specify the path of the file to be read: to do so, just click on the Browse... button and select the file. If you dragged and dropped your file in the Workflow Editor, this field is pre-populated. The node lets you also read multiple files in a folder having the same format, by selecting the Files in folder mode.
- In the middle section, you can specify the format of the file, like the characters used to delimit rows and columns and if it has column headers. All these parameters get automatically guessed by the node when a new file is loaded (you can click on Autodetect format to force a new attempt). One useful option is Support short data rows: if this box is ticked, the node will keep working even if some rows have incomplete data points. The good news is that in most cases you will not need to change any of these parameters manually as the automatic detection feature is pretty robust.
- At the bottom of the tab, you find the Preview of the table read in the file. This lets you check that the format has been determined correctly.
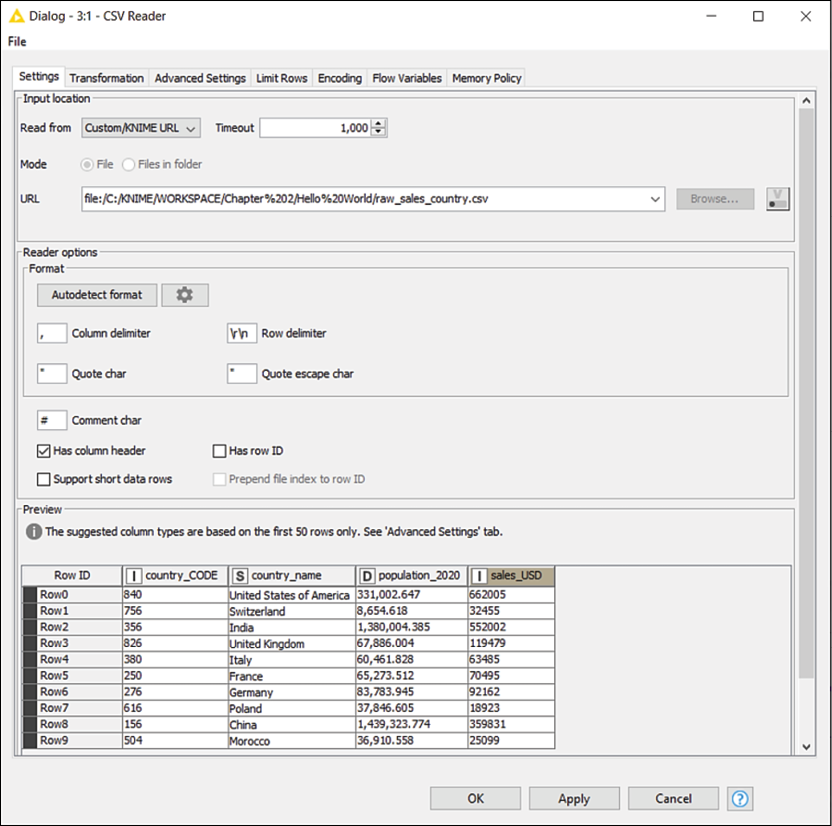
Figure 2.6: Configuration dialog of the CSV Reader node: you can specify which file to read and how
If you move to the second tab of the window (called Transformation) you will have the opportunity to apply some simple reformatting to your table as it gets loaded. For instance, you can: change the name of columns (just write the new one in the New name column), drop some columns you don't need (untick the box on the left of their name), change the column order (drag and drop them using your mouse), and change their data type (for instance, from text to numbers).
Every column in a KNIME table is associated with a data type, indicated by a squared letter beside the name of the column. The most common data types are strings (indicated by the letter S, which are sets of text characters), decimal numbers (letter D), integer numbers (I), long integers (L, like integers but able to store more digits), and Boolean values (B, which can be only FALSE or TRUE).
You can check the results of your transformation in the preview section at the bottom. To be clear, you could do these transformations later in your workflow (you have specific KNIME nodes for renaming columns, changing their orders, and so on) but it might be just faster and easier to make these changes here on the spot, using one single node.
In case the CSV Reader node fails in reading your data as you required, try another node called File Reader. Especially with ill-formatted files, the latter node is more robust than CSV Reader, although it cannot transform the structure of the table on the fly.
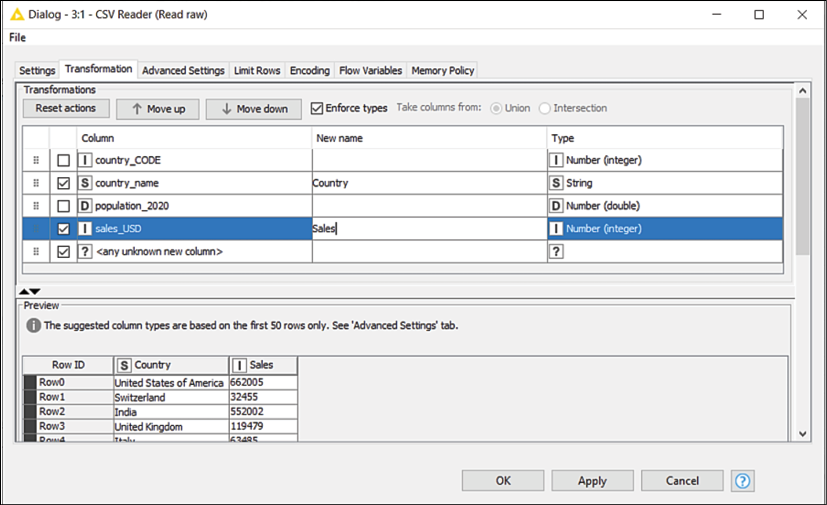
Figure 2.7: The transformation tab of the CSV Reader node: reformat your table on the fly
- Looking at the preview of the table in the Settings tab, it looks like the node has done a good job of interpreting the format of the file. We just noticed that there are some columns we don't need to carry and they can be dropped (specifically,
country_CODEandpopulation_2020) and, also, that we can simplify some of the column names by renaming them. To do this, we need to move to the Transformation tab: just click on its name at the top of the window. - Let's first remove the columns we don't need, by just unticking the boxes beside their names, as shown in Figure 2.7.
- Let's also assign more friendly titles to the other two columns by typing them in the New name section: let's rename
country_nametoCountryandsales_USDtoSales. - The preview of the transformed table looks exactly like we wanted; this means we are done with the configuration of this node, and we can close it by clicking on the OK button.
- To keep things clear to ourselves and others we want to comment on every node in our workflows. Let's start from this very first node. If we double-click on the label underneath (which by default will read Node 1), we can change it to something more meaningful, like
Read raw data. From this point on, I will not mention every time we need to comment on each node—just make it become a habit. - Our node is displaying an encouraging yellow traffic light: it means it has all it needs to fulfill its duty—we just need to say the word. To execute a node in KNIME, we can either select it and press F7 on our keyboard or right-click on the node to obtain the pop-up menu, as shown in Figure 2.8. When it appears, click on Execute:

Figure 2.8: The pop-up menu in the Workflow Editor: right-click on any node to make it appear
- The traffic light turning green is a good sign: our node was successfully executed. A useful feature of KNIME is that you can easily inspect what's going on at each step of the flow, by viewing what data is available at the output ports of every node. In the pop-up menu obtained by right-clicking on a node, you will find one or more icons showing a magnifying lens (normally one for each output port, at the bottom of the menu). By clicking on these icons, you will open a window showing the data you are after. Let's do so now: right-click to make the pop-up menu appear and then click on File Table at the bottom of the menu (alternatively you can check out the Node Monitor or use the keyboard shortcut to open the first output view of a node, which is Shift + F6). Not surprisingly, we obtain the same table we had in preview in the preview step. It seems that, so far, everything is working right. We can click OK and move on.
- The next step is to sort rows by decreasing amounts of sales. We can use a node that is meant to do exactly that: Sorter. Let's add our Sorter node to the workflow, pulling it from the Node Repository at the bottom left. You can either look it up by typing
Sorterin the search box or find it in the hierarchy by clicking first on Manipulation, then Row, and—finally—Transform. When you see the Sorter node, grab it with your mouse and drop it on the workflow, at the right of the CSV Reader node. - Your node is now lying alone in the workflow while we want it to be cooperating with other nodes. In fact, we need it to sort the table output by the CSV Reader, so we need to create a connection between the two nodes. In KNIME, we create connections by just drawing them with the mouse. Click on the output port of the CSV Reader (the little arrow on its right) and while keeping the mouse button pressed, go to the input port of the Sorter node. When you release the button, you will see a connection appearing between the nodes. This is exactly what we wanted, the table given in the output by the CSV Reader has now become an input for the Sorter.
We are now ready to configure the Sorter: let's learn about our new node.
 Sorter
Sorter
This node (available in the repository in Manipulation > Row > Transform) can sort the rows of a table according to a set of criteria defined by the user. Its configuration is self-explanatory: from the drop-down menu, you can select the column you wish to sort by. The radio buttons on the right let you choose whether the sorting shall follow an Ascending (A to Z or 1 to 9) or Descending (the other way around) order. You can add additional rules on other columns that will come to play to break the ties in case multiple rows carry the same value in a column. To do so, just click on the Add Rule button and you will see further drop-down menus appearing. You can change the order of precedence among multiple rules by using the ↑ and ↓ arrows:
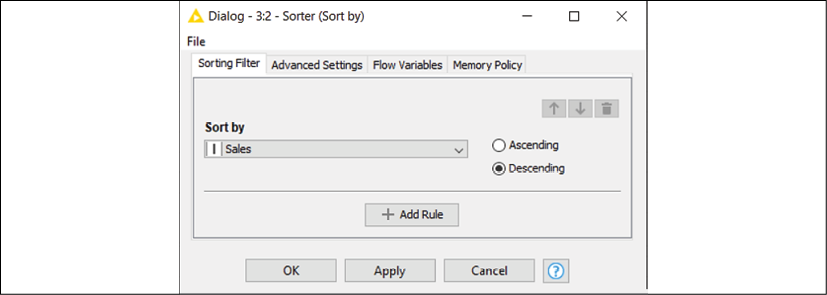
Figure 2.9: Configuration window of the node Sorter: define the desired order of your rows
- To open the configuration window of Sorter, you can either double-click on the node or right-click on it and then press Configure…. You could also just press F6 on your keyboard after selecting the node with your mouse.
- Given our needs, the configuration of the node is straightforward: just select
Salesin the drop-down menu and then click on the second radio button to apply a descending order. Press OK to close the window. - The Sorter node is now clear about the input table to use and about the way we want the sorting to happen: it is all ready to go. Let's execute it (F7 or right-click and select Execute) and open the view showing its output (Shift + F6 or right-click and select Sorted Table, the last icon with the magnifying lens):

Figure 2.10: Output of Sorter node: our countries are now showing by decreasing sales
Every row in a KNIME table is associated with a unique label called Row ID. When a table is created, row IDs are normally generated in the form of a counter (Row0, Row1, Row2, and so on) and are preserved along the workflow. That's why in the output of the Sorter node you can still find the original row position by looking at the Row IDs on the left.
It looks like we have our countries sorted in the right order and we can proceed to the last step: exporting our table as an Excel file.
 Excel Writer
Excel Writer
This node (available within IO > Write in the repository) saves data as Excel worksheets. The configuration dialog will let you first select the format of the file to create (the legacy .xls or the latest .xlsx one) and where to save it (click on the Browse... button to select a path). By selecting the if exists radio buttons, you can specify what to do if a file with that name is already there where you want to save it: you can overwrite the old data, append the new data as additional rows, or preserve the original file. An important option to check is Write column headers: when selected, the column names of your table are added as headers in the first row of your Excel file.
Although we don't need to do that now, it's useful to know that some KNIME nodes can also save files on cloud-based file systems, like Google Drive or Microsoft Sharepoint. This is why you also see the option Add ports | File System Connection when you click on the three dots (...) at the bottom left of the node. Another useful feature of the node is that it can manage multiple input tables and save them as separate worksheets in the same Excel file. To do so, you need to click on the three dots on the node and click on Add ports > Sheet Input Ports. You can give different names to the various sheets by typing in the Sheets section of the configuration window.
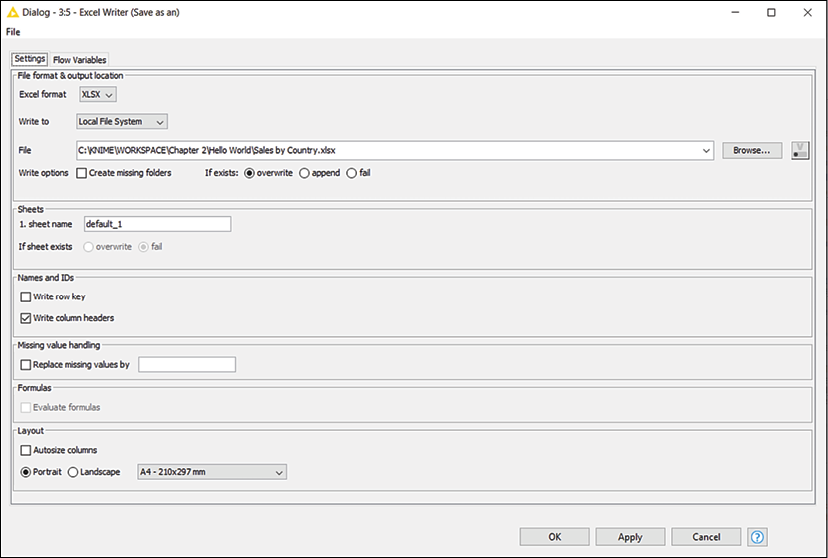
Figure 2.11: Configuration window of Excel Writer: select where to save your output file
- Let's add the Excel Writer node to our workflow, dragging it from the Node Repository, and then create a connection between the output port of the Sorter and the input node of the Excel Writer.
- Open the configuration window of the Excel Writer (double-click on it). The only configurations we need to add in this case are the location and the name of the output file (click on the Browse... button, go to the desired folder, and type the name of the new file) and, since we might need to repeat this process regularly, select the overwrite option using the radio button below.
- It's time to run the node (F7 or right-click and select Execute) and open the new file in Excel. You'll be pleased to see that the new file looks exactly how we wanted.
Congratulations on creating your first KNIME workflow! By combining three nodes and configuring them appropriately, you implemented a simple data transformation routine that you can now repeat in a matter of seconds, whenever it's needed. More importantly, we used this first tutorial to get acquainted with the fundamental operations you need to build any workflow, such as pulling the right nodes, configuring and executing them, and checking that all works as it should:
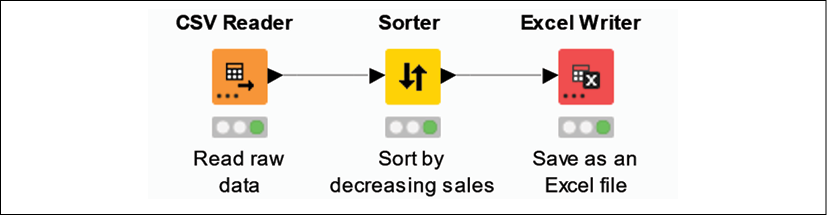
Figure 2.12: Hello World: your first workflow in KNIME
We now have all we need to start building more complex data operations, discovering what other KNIME nodes can do, and this is exactly what we will do in the next few pages. Since we don't want to lose our precious Hello World workflow, it would be a good idea to save it: just press Ctrl + S on your keyboard or click on the disk icon at the top left of your screen. If you want to share your workflow with others, you first need to export it as a standalone file. To do so, right-click on the name of the workflow within the KNIME Explorer panel on the left and then select Export KNIME Workflow...:
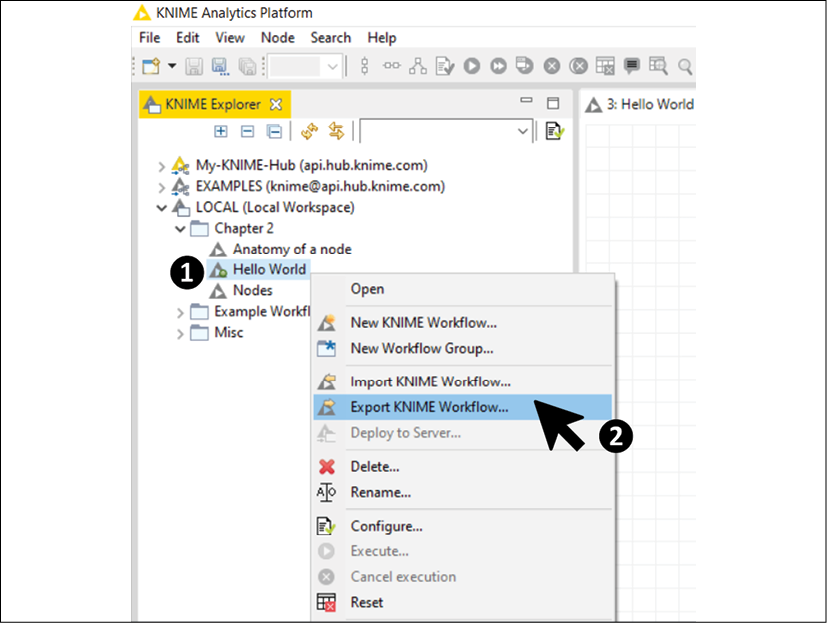
Figure 2.13: How to export a KNIME workflow: you can then share it with whoever you like
In the window that appears, you will have to specify the location and name of the file with your workflow by clicking on the Browse... button. If you keep the Reset Workflow(s) before export option checked, KNIME will only export the definition of the workflow (the nodes' structure and their configuration) without any data in it. If you untick it, the data stored in every executed node will be exported as well (making your export much larger in size). You can now send the resulting file (with .KNWF as an extension) via email or save it in a safe place. Whoever receives it can import it back in their KNIME installation by clicking on File | Import KNIME Workflow... and selecting the location of the file to import and the destination of the workflow.
















