























































In this section, we will use AWS Glue to create a crawler, an ETL job, and a job that runs KMeans clustering algorithm on the input data.
We use a publicly available dataset about the students' knowledge status on a subject. The dataset and the field descriptions are available for download from the UCI site: https://archive.ics.uci.edu/ml/datasets/User+Knowledge+Modeling
- Log in to the AWS Management Console and go to the Glue console. Click on the Add crawler button.
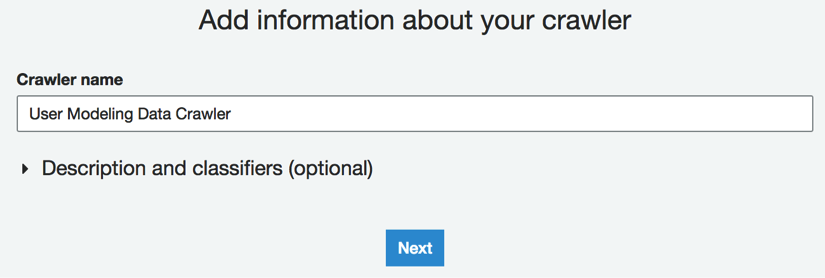
- Specify the Crawler name as User Modeling Data Crawler as shown here. Click on the Next button:
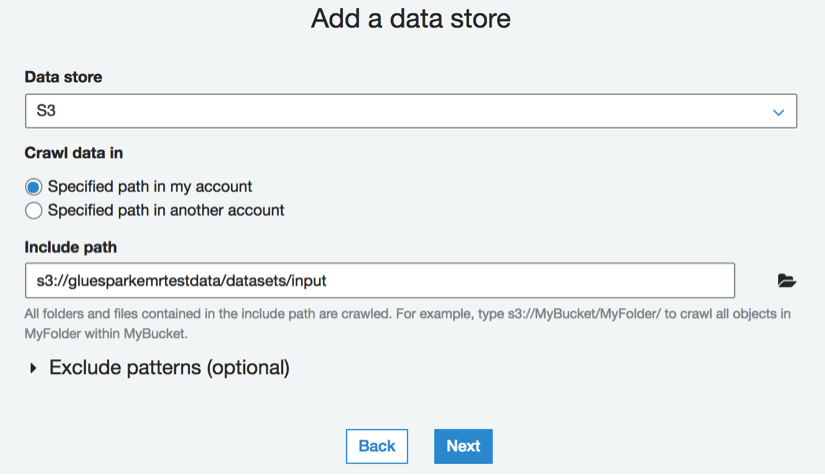
- In the Add a data store screen, select S3 as the Data store, and select the Specified path in my account option. Specify the path for the S3 bucket containing the input data. Click on the Next button:
- Select No on the Add another data store and click on the Next button.
- On the...






















