






















































Importance of Data Wrangling
A common mantra of the modern age is Data is the New Oil, meaning data is now a resource that's more valuable than oil. But just as crude oil does not come out of the rig as gasoline and must be processed to get gasoline and other products, data must be curated, massaged, or cleaned and refined to be used in data science and products based on data science. This is known as wrangling. Most data scientists spend the majority of their time data wrangling.
Data wrangling is generally done at the very first stage of a data science/analytics pipeline. After the data scientists have identified any useful data sources for solving the business problem at hand (for instance, in-house database storage, the internet, or streaming sensor data such as an underwater seismic sensor), they then proceed to extract, clean, and format the necessary data from those sources.
Generally, the task of data wrangling involves the following steps:
- Scraping raw data from multiple sources (including web and database tables)
- Imputing (replacing missing data using various techniques), formatting, and transforming – basically making it ready to be used in the modeling process (such as advanced machine learning)
- Handling read/write errors
- Detecting outliers
- Performing quick visualizations (plotting) and basic statistical analysis to judge the quality of formatted data
The following is an illustrative representation of the positioning and the essential functional role of data wrangling in a typical data science pipeline:
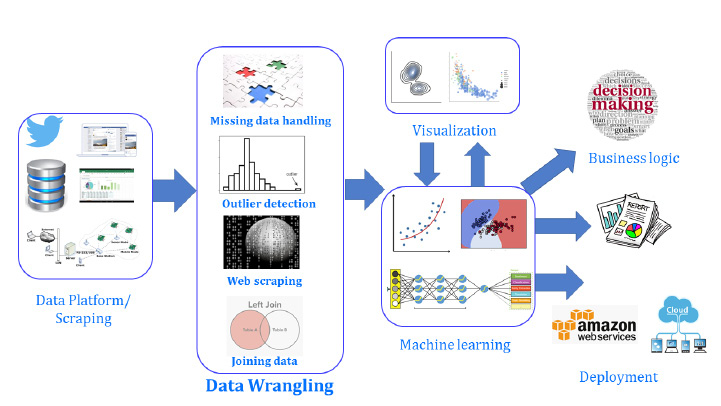
Figure 1.1: Process of data wrangling
The process of data wrangling includes finding the appropriate data that's necessary for the analysis. Often, analysis is exploratory, so there is not enough scope. You often need to do data wrangling for this type of analysis to be able to understand your data better. This could lead to more analysis or machine learning.
This data can be from one or multiple sources, such as tweets, bank transaction statements in a relational database, sensor data, and so on. This data needs to be cleaned. If there is missing data, we will either delete or substitute it, with the help of several techniques. If there are outliers, we need to detect them and then handle them appropriately. If the data is from multiple sources, we will have to combine it using Structured Query Language (SQL) operations like JOIN.
In an extremely rare situation, data wrangling may not be needed. For example, if the data that's necessary for a machine learning task is already stored in an acceptable format in an in-house database, then a simple SQL query may be enough to extract the data into a table, ready to be passed on to the modeling stage.





