






















































Understanding Docker
This book assumes that you have a foundational understanding of Docker and container concepts. However, we know that not everyone will have prior experience with Docker or containers. Therefore, we have included this crash course to introduce you to container concepts and guide you through the usage of Docker.
If you are new to containers, we suggest reading the documentation that can be found on Docker’s website for additional information: https://docs.docker.com/.
Containers are ephemeral
The first thing to understand is that containers are ephemeral.
The term “ephemeral” means something that exists for a short period. Containers can be intentionally terminated, or automatically restarted without any user involvement or consequences. To better understand this concept, let’s look at an example – imagine someone interactively adds files to a web server running within a container. The uploaded files are temporary because they were not originally part of the base image.
This means that once a container is built and running, any changes that are made to the container will not be saved once it is removed, or destroyed, from the Docker host. Let’s look at a full example:
- You start a container running a web server using NGINX on your host without any base HTML pages.
- Using a Docker command, you execute a
copycommand to copy some web files into the container’s filesystem. - To test that the copy was successful, you go to the website and confirm that it is serving the correct web pages.
- Happy with the results, you stop the container and remove it from the host. Later that day, you want to show a coworker the website and you start your NGINX container. You go to the website again, but when the site opens, you receive a
404error (page not found error).
What happened to the files you uploaded before you stopped and removed the container from the host?
The reason your web pages cannot be found after the container was restarted is that all containers are ephemeral. Whatever is in the base container image is all that will be included each time the container is initially started. Any changes that you make inside a container are short-lived.
If you need to add permanent files to an existing image, you need to rebuild the image with the files included or, as we will explain in the Persistent data section later in this chapter, you could mount a Docker volume in your container.
At this point, the main concept to understand is that containers are ephemeral.
But wait! You may be wondering, “If containers are ephemeral, how did I add web pages to the server?” Ephemeral just means that changes will not be saved; it doesn’t stop you from making changes to a running container.
Any changes made to a running container will be written to a temporary layer, called the container layer, which is a directory on the localhost filesystem. Docker uses a storage driver, which is in charge of handling requests that use the container layer. The storage driver is responsible for managing and storing images and containers on your Docker host. It controls the mechanisms and processes involved in their storage and management.
This location will store all changes in the container’s filesystem so that when you add the HTML pages to the container, they will be stored on the local host. The container layer is tied to the container ID of the running image and it will remain on the host system until the container is removed from Docker, either by using the CLI or by running a Docker prune job (see Figure 1.1 on the next page).
Considering that containers are temporary and are read only, you might wonder how it’s possible to modify data within a container. Docker addresses this by utilizing image layering, which involves creating interconnected layers that collectively function as a single filesystem. Through this, changes can be made to the container’s data, even though the underlying image remains immutable.
Docker images
A Docker image is composed of multiple image layers, each accompanied by a JavaScript Object Notation (JSON) file that stores metadata specific to the layer. When a container image is launched, these layers are combined to form the application that users interact with.
You can read more about the contents of an image on Docker’s GitHub at https://github.com/moby/moby/blob/master/image/spec/v1.1.md.
Image layers
As we mentioned in the previous section, a running container uses a container layer that is “on top” of the base image layer, as shown in the following diagram:
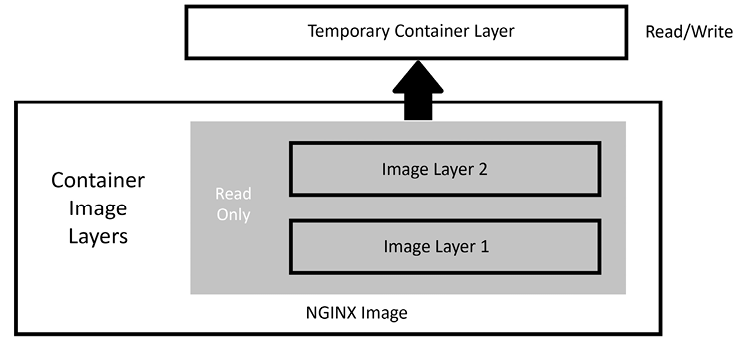
Figure 1.1: Docker image layers
The image layers cannot be written to since they are in a read-only state, but the temporary container layer is in a writeable state. Any data that you add to the container is stored in this layer and will be retained as long as the container is running.
To deal with multiple layers efficiently, Docker implements copy-on-write, which means that if a file already exists, it will not be created. However, if a file is required that does not exist in the current image, it will be written. In the container world, if a file exists in a lower layer, the layers above it do not need to include it. For example, if layer 1 had a file called /opt/nginx/index.html in it, layer 2 does not need the same file in its layer.
This explains how the system handles files that either exist or do not exist, but what about a file that has been modified? There will be times when you’ll need to replace a file that is in a lower layer. You may need to do this when you are building an image or as a temporary fix to a running container issue. The copy-on-write system knows how to deal with these issues. Since images read from the top down, the container uses only the highest layer file. If your system had a /opt/nginx/index.html file in layer 1 and you modified and saved the file, the running container would store the new file in the container layer. Since the container layer is the topmost layer, the new copy of index.html would always be read before the older version in the image layer.
Persistent data
Being limited to ephemeral-only containers would severely limit the use cases for Docker. You will probably encounter use cases where persistent storage is needed or data must be retained even if a container is stopped.
Remember, when you store data in the container image layer, the base image does not change. When the container is removed from the host, the container layer is also removed. If the same image is used to start a new container, a new container image layer is created. While containers themselves are ephemeral, you can achieve data persistence by incorporating a Docker volume. By utilizing a Docker volume, data can be stored externally in the container, enabling it to persist beyond the container’s lifespan.
Accessing services running in containers
Unlike a physical machine or a virtual machine, containers do not connect to a network directly. When a container needs to send or receive traffic, it goes through the Docker host system using a bridged network address translation (NAT) connection. This means that when you run a container and you want to receive incoming traffic requests, you need to expose the ports for each of the containers that you wish to receive traffic on. On a Linux-based system, iptables has rules to forward traffic to the Docker daemon, which will service the assigned ports for each container. There is no need to worry about how the iptables rules are created, as Docker will handle that for you by using the port information provided when you start the container. If you are new to Linux, iptables may be new to you.
At a high level, iptables is used to manage network traffic and keep it secure within a cluster. It controls the flow of network connections between components in the cluster, deciding which connections are allowed and which ones are blocked.
That concludes the introduction to container fundamentals and Docker concepts. In the next section, we will guide you through the process of installing Docker on your host.









