























































Chapter materials
All the files for this book are on GitHub at https://github.com/stefmolin/Hands-On-Data-Analysis-with-Pandas-2nd-edition. While having a GitHub account isn't necessary to work through this book, it is a good idea to create one, as it will serve as a portfolio for any data/coding projects. In addition, working with Git will provide a version control system and make collaboration easy.
Tip
Check out this article to learn some Git basics: https://www.freecodecamp.org/news/learn-the-basics-of-git-in-under-10-minutes-da548267cc91/.
In order to get a local copy of the files, we have a few options (ordered from least useful to most useful):
- Download the ZIP file and extract the files locally.
- Clone the repository without forking it.
- Fork the repository and then clone it.
This book includes exercises for every chapter; therefore, for those who want to keep a copy of their solutions along with the original content on GitHub, it is highly recommended to fork the repository and clone the forked version. When we fork a repository, GitHub will make a repository under our own profile with the latest version of the original. Then, whenever we make changes to our version, we can push the changes back up. Note that if we simply clone, we don't get this benefit.
The relevant buttons for initiating this process are circled in the following screenshot:
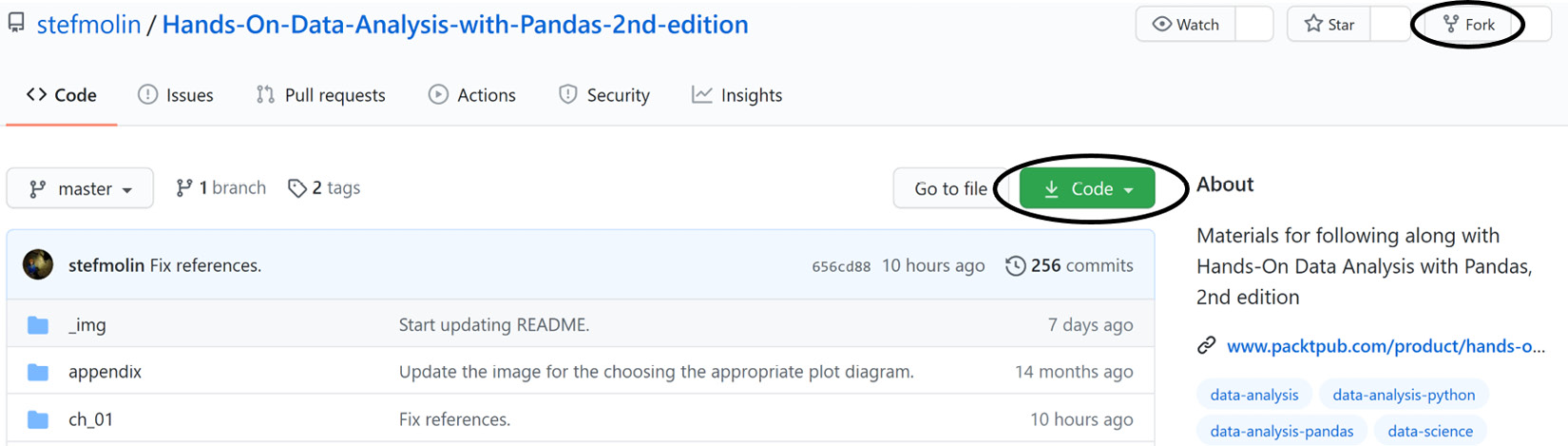
Figure 1.1 – Getting a local copy of the code for following along
Important note
The cloning process will copy the files to the current working directory in a folder called Hands-On-Data-Analysis-with-Pandas-2nd-edition. To make a folder to put this repository in, we can use mkdir my_folder && cd my_folder. This will create a new folder (directory) called my_folder and then change the current directory to that folder, after which we can clone the repository. We can chain these two commands (and any number of commands) together by adding && in between them. This can be thought of as and then (provided the first command succeeds).
This repository has folders for each chapter. This chapter's materials can be found at https://github.com/stefmolin/Hands-On-Data-Analysis-with-Pandas-2nd-edition/tree/master/ch_01. While the bulk of this chapter doesn't involve any coding, feel free to follow along in the introduction_to_data_analysis.ipynb notebook on the GitHub website until we set up our environment toward the end of the chapter. After we do so, we will use the check_your_environment.ipynb notebook to get familiar with Jupyter Notebooks and to run some checks to make sure that everything is set up properly for the rest of this book.
Since the code that's used to generate the content in these notebooks is not the main focus of this chapter, the majority of it has been separated into the visual_aids package, which is used to create visuals for explaining concepts throughout the book, and the check_environment.py file. If you choose to inspect these files, don't be overwhelmed; everything that's relevant to data science will be covered in this book.
Every chapter includes exercises; however, for this chapter only, there is an exercises.ipynb notebook, with code to generate some initial data. Knowledge of basic Python will be necessary to complete these exercises. For those who would like to review the basics, make sure to run through the python_101.ipynb notebook, included in the materials for this chapter, for a crash course. The official Python tutorial is a good place to start for a more formal introduction: https://docs.python.org/3/tutorial/index.html.






















