






















































Similarities measures
In order to compute similarity s between two different vectors x and y, which can be users (rows of utility matrix) or items (columns of utility matrix), two measures are typically used:
-
Cosine similarity:
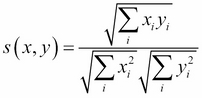
-
Pearson correlation:
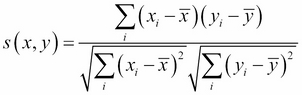 , where x and y are the averages of the two vectors.
, where x and y are the averages of the two vectors.
Note that the two measures coincide if the average is 0. We can now start discussing the different algorithms, starting from the CF category. The following sim() function will be used to evaluate the similarity between two vectors:

The SciPy library has been used to compute both similarities (note that the cosine scipy definition is the opposite of what has been defined previously, so the value is subtracted from 1).


