






















































Generalized linear models
The generalized linear model is a group of models that try to find the M parameters 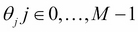 that form a linear relationship between the labels yi and the feature vector x(i) that is as follows:
that form a linear relationship between the labels yi and the feature vector x(i) that is as follows:

Here, 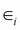 are the errors of the model. The algorithm for finding the parameters tries to minimize the total error of the model defined by the cost function J:
are the errors of the model. The algorithm for finding the parameters tries to minimize the total error of the model defined by the cost function J:

The minimization of J is achieved using an iterative algorithm called batch gradient descent:

Here, α is called learning rate, and it is a trade-off between convergence speed and convergence precision. An alternative algorithm that is called stochastic gradient descent, that is loop for 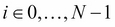 :
:

The θj is updated for each training example i instead of waiting to sum over the entire training set. The last algorithm converges near the minimum of J, typically faster than batch gradient descent, but the final solution may oscillate around the real values of the parameters. The following paragraphs describe the most common model...


