While that Q-learning equation may seem a lot more complex, actually implementing the equation is not unlike building our agent that just learned values earlier. To keep things simpler, we will use the same base of code but turn it into a Q-learning example. Open up the code example, Chapter_1_4.py, and follow the exercise here:
- Here is the full code listing for reference:
import random
arms = 7
bandits = 7
learning_rate = .1
gamma = .9
episodes = 10000
reward = []
for i in range(bandits):
reward.append([])
for j in range(arms):
reward[i].append(random.uniform(-1,1))
print(reward)
Q = []
for i in range(bandits):
Q.append([])
for j in range(arms):
Q[i].append(10.0)
print(Q)
def greedy(values):
return values.index(max(values))
def learn(state, action, reward, next_state):
q = gamma * max(Q[next_state])
q += reward
q -= Q[state][action]
q *= learning_rate
q += Q[state][action]
Q[state][action] = q
# agent learns
bandit = random.randint(0,bandits-1)
for i in range(0, episodes):
last_bandit = bandit
bandit = random.randint(0,bandits-1)
action = greedy(Q[bandit])
r = reward[last_bandit][action]
learn(last_bandit, action, r, bandit)
print(Q)
- All of the highlighted sections of code are new and worth paying closer attention to. Let's take a look at each section in more detail here:
arms = 7
bandits = 7
gamma = .9
- We start by initializing the arms variable to 7 then a new bandits variable to 7 as well. Recall that arms is analogous to actions and bandits likewise is to state. The last new variable, gamma, is a new learning parameter used to discount rewards. We will explore this discount factor concept in future chapters:
reward = []
for i in range(bandits):
reward.append([])
for j in range(arms):
reward[i].append(random.uniform(-1,1))
print(reward)
- The next section of code builds up the reward table matrix as a set of random values from -1 to 1. We use a list of lists in this example to better represent the separate concepts:
Q = []
for i in range(bandits):
Q.append([])
for j in range(arms):
Q[i].append(10.0)
print(Q)
- The following section is very similar and this time sets up a Q table matrix to hold our calculated quality values. Notice how we initialize our starting Q value to 10.0. We do this to account for subtle changes in the math, again something we will discuss later.
- Since our states and actions can be all mapped onto a matrix/table, we refer to our RL system as using a model. A model represents all actions and states of an environment:
def learn(state, action, reward, next_state):
q = gamma * max(Q[next_state])
q += reward
q -= Q[state][action]
q *= learning_rate
q += Q[state][action]
Q[state][action] = q
- We next define a new function called learn. This new function is just a straight implementation of the Q equation we observed earlier:
bandit = random.randint(0,bandits-1)
for i in range(0, episodes):
last_bandit = bandit
bandit = random.randint(0,bandits-1)
action = greedy(Q[bandit])
r = reward[last_bandit][action]
learn(last_bandit, action, r, bandit)
print(Q)
- Finally, the agent learning section is updated significantly with new code. This new code sets up the parameters we need for the new learn function we looked at earlier. Notice how the bandit or state is getting randomly selected each time. Essentially, this means our agent is just randomly walking from bandit to bandit.
- Run the code as you normally would and notice the new calculated Q values printed out at the end. Do they match the rewards for each of the arm pulls?
Likely, a few of your arms don't match up with their respective reward values. This is because the new Q-learning equation solves the entire MDP but our agent is NOT moving in an MDP. Instead, our agent is just randomly moving from state to state with no care on which state it saw before. Think back to our example and you will realize since our current state does not affect our future state, it fails to be a Markov property and hence is not an MDP. However, that doesn't mean we can't successfully solve this problem and we will look to do that in the next section.























































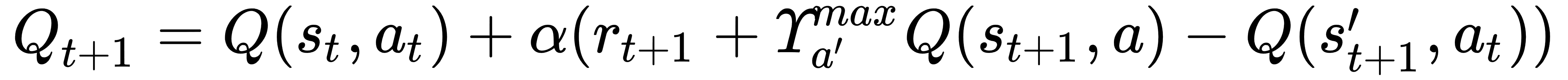
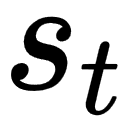 : state
: state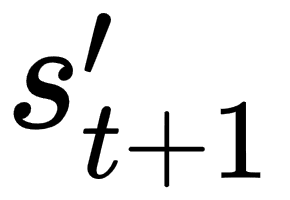 : current state
: current state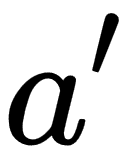 : next action
: next action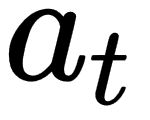 : current action
: current action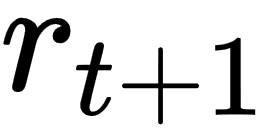 : next reward
: next reward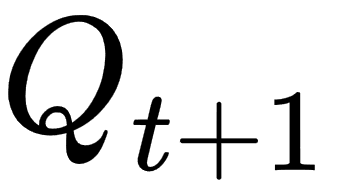 : quality
: quality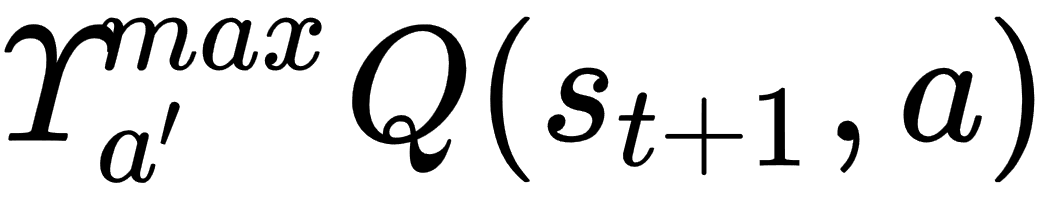 . Gamma and this term are a way of discounting future rewards and something we will discuss at length starting in
. Gamma and this term are a way of discounting future rewards and something we will discuss at length starting in 







