Around 10 years ago, developers used to use the Apache web server with a scripting programming language to create web applications, rendering the views on the server-side. This meant that there was no need to split applications into pieces and it was simpler to keep the code together. With the emergence of Single-Page Applications (SPAs), we only needed server-side rendering for special cases and applications were divided into two parts: frontend and backend. Another tendency was that servers changed processing method from synchronous (where every client interaction lives in a separate thread) to asynchronous (where one thread processes many clients simultaneously using non-blocking, input-output operations). This trend promotes the better performance of single server units, meaning they can serve thousands of clients. This means that we don't need special hardware, proprietary software, or a special toolchain or compiler to write a tiny server with great performance.
The invasion of microservices happened when scripting programming languages become popular. By this, we are not only referring to languages for server-side scripting, but general-purpose high-level programming languages such as Python or Ruby. The adoption of JavaScript for backend needs, which had previously always been asynchronous, was particularly influential.
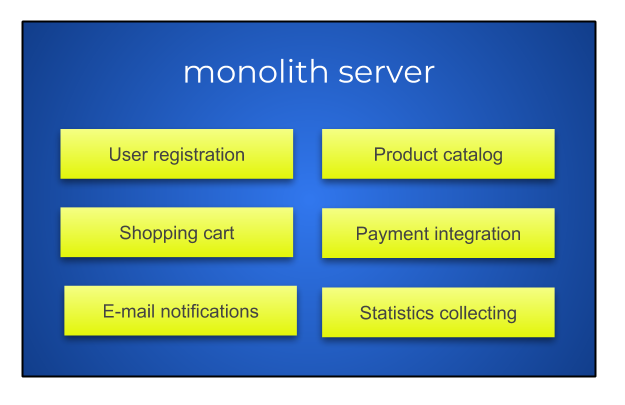
If writing your own server wasn't hard enough, you could create a separate server for special cases and use them directly from the frontend application. This would not require rendering procedures on the server. This section has provided a short description of the evolution from monolithic servers to microservices. We are now going to examine how to break a monolithic server into small pieces.