























































Contiguous Versus Linked Data Structures
Before processing the data in any application, we must decide how we want to store data. The answer to that question depends on what kind of operations we want to perform on the data and the frequency of the operations. We should choose the implementation that gives us the best performance in terms of latency, memory, or any other parameter, without affecting the correctness of the application.
A useful metric for determining the type of data structure to be used is algorithmic complexity, also called time complexity. Time complexity indicates the relative amount of time required, in proportion to the size of the data, to perform a certain operation. Thus, time complexity shows how the time will vary if we change the size of the dataset. The time complexity of different operations on any data type is dependent on how the data is stored inside it.
Data structures can be divided into two types: contiguous and linked data structures. We shall take a closer look at both of them in the following sections.
Contiguous Data Structures
As mentioned earlier, contiguous data structures store all the elements in a single chunk of memory. The following diagram shows how data is stored in contiguous data structures:

Figure 1.1: Diagrammatic representation of contiguous data structures
In the preceding diagram, consider the larger rectangle to be the single memory chunk in which all the elements are stored, while the smaller rectangles represent the memory allocated for each element. An important thing to note here is that all the elements are of the same type. Hence, all of them require the same amount of memory, which is indicated by sizeof(type). The address of the first element is also known as the Base Address (BA). Since all of them are of the same type, the next element is present in the BA + sizeof(type) location, and the one after that is present in BA + 2 * sizeof(type), and so on. Therefore, to access any element at index i, we can get it with the generic formula: BA + i * sizeof(type).
In this case, we can always access any element using the formula instantly, regardless of the size of the array. Hence, the access time is always constant. This is indicated by O(1) in the Big-O notation.
The two main types of arrays are static and dynamic. A static array has a lifetime only inside its declaration block, but a dynamic array provides better flexibility since the programmer can determine when it should be allocated and when it should be deallocated. We can choose either of them depending on the requirement. Both have the same performance for different operations. Since this array was introduced in C, it is also known as a C-style array. Here is how these arrays are declared:
- A static array is declared as int arr[size];.
- A dynamic array in C is declared as int* arr = (int*)malloc(size * sizeof(int));.
- A dynamic array is declared in C++ as int* arr = new int[size];.
A static array is aggregated, which means that it is allocated on the stack, and hence gets deallocated when the flow goes out of the function. On the other hand, a dynamic array is allocated on a heap and stays there until the memory is freed manually.
Since all the elements are present next to each other, when one of the elements is accessed, a few elements next to it are also brought into the cache. Hence, if you want to access those elements, it is a very fast operation as the data is already present in the cache. This property is also known as cache locality. Although it doesn't affect the asymptotic time complexity of any operations, while traversing an array, it can give an impressive advantage for contiguous data in practice. Since traversing requires going through all the elements sequentially, after fetching the first element, the next few elements can be retrieved directly from the cache. Hence, the array is said to have good cache locality.
Linked Data Structures
Linked data structures hold the data in multiple chunks of memory, also known as nodes, which may be placed at different places in the memory. The following diagram shows how data is stored in linked data structures:

Figure 1.2: Linked data structures
In the basic structure of a linked list, each node contains the data to be stored in that node and a pointer to the next node. The last node contains a NULL pointer to indicate the end of the list. To reach any element, we must start from the beginning of the linked list, that is, the head, and then follow the next pointer until we reach the intended element. So, to reach the element present at index i, we need to traverse through the linked list and iterate i times. Hence, we can say that the complexity of accessing elements is O(n); that is, the time varies proportionally with the number of nodes.
If we want to insert or delete any element, and if we have a pointer to that element, the operation is really small and quite fast for a linked list compared to arrays. Let's take a look at how the insertion of an element works in a linked list. The following diagram illustrates a case where we are inserting an element between two elements in a linked list:
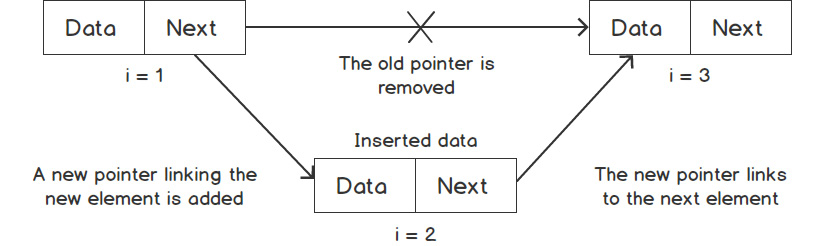
Figure 1.3: Inserting an element into a linked list
For insertion, once we've constructed the new node to be inserted, we just need to rearrange the links so that the next pointer of the preceding element (i = 1) points to the new element (i = 2) instead of its current element (i = 3), and the next pointer of the new element (i = 2) points to the current element's next element (i = 3). In this way, the new node becomes part of the linked list.
Similarly, if we want to remove any element, we just need to rearrange the links so that the element to be deleted is no longer connected to any of the list elements. Then, we can deallocate that element or take any other appropriate action on it.
A linked list can't provide cache locality at all since the elements are not stored contiguously in memory. Hence, there's no way to bring the next element into the cache without actually visiting it with the pointer stored in the current element. So, although, in theory, it has the same time complexity for traversal as an array, in practice, it gives poor performance.
The following section provides a summary of the comparison of contiguous and linked data structures.
Comparison
The following table briefly summarizes the important differences between linked and contiguous data structures in general:
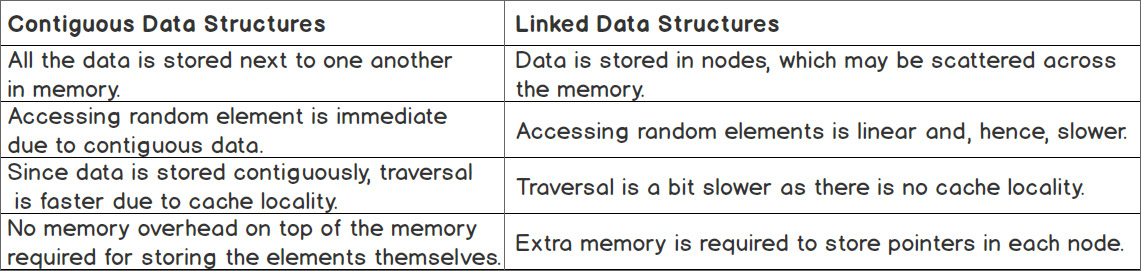
Figure 1.4: Table comparing contiguous and linked data structures
The following table contains a summary of the performance of arrays and linked lists regarding various parameters:
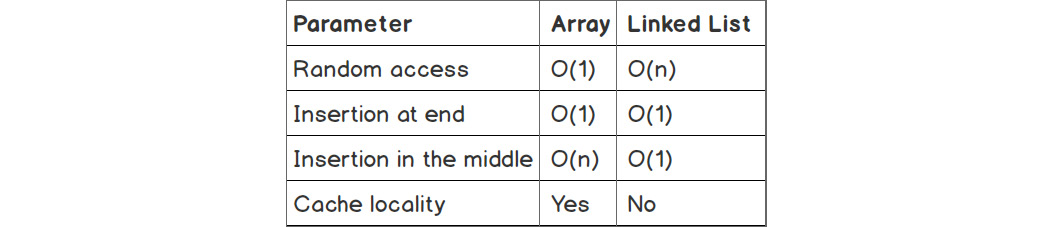
Figure 1.5: Table showing time complexities of some operations for arrays and linked lists
For any application, we can choose either data structure or a combination of both, based on the requirements and the frequencies of the different operations.
Arrays and linked lists are very common and are extensively used in any application to store data. Hence, the implementation of these data structures must be as bug-free and as efficient as possible. To avoid reinventing the code, C++ provides various structures, such as std::array, std::vector, and std::list. We will see some of them in more detail in upcoming sections.
Limitations of C-style Arrays
Though C-style arrays do the job, they are not commonly used. There are a number of limitations that indicate the necessity of better solutions. Some of the major limitations among those are as follows:
- Memory allocation and deallocation have to be handled manually. A failure to deallocate can cause a memory leak, which is when a memory address becomes inaccessible.
- The operator[] function does not check whether the argument is larger than the size of an array. This may lead to segmentation faults or memory corruption if used incorrectly.
- The syntax for nested arrays gets very complicated and leads to unreadable code.
- Deep copying is not available as a default function. It has to be implemented manually.
To avoid these issues, C++ provides a very thin wrapper over a C-style array called std::array.






















