






















































Chapter 3. Service-enabling Existing Systems
The heart of service-oriented architecture (SOA) is the creation of processes and applications from existing services. The question arises, where do these services come from? Within an SOA solution, some services will need to be written from scratch, but most of the functions required should already exist in some form within the IT assets of the organization. Existing applications within the enterprise already provide many services that just require exposing to an SOA infrastructure. In this chapter, we will examine some ways to create services from existing applications. We refer to this process as service-enabling existing systems. After discussing some of the different types of systems, we will look at the specific functionality provided in the Oracle SOA Suite that makes it easy to convert file and database interfaces into services.
Types of systems
IT systems come in all sorts of shapes and forms; some have existing web service interfaces which can be consumed directly by an SOA infrastructure, others have completely proprietary interfaces, and others expose functionality through some well understood but non web service-based interfaces. In terms of service-enabling a system, it is useful to classify it by the type of interface it exposes.
Within the SOA Suite, components called adapters provide a mapping between non-web service interfaces and the rest of the SOA Suite. These adapters allow the SOA Suite to treat non-web service interfaces as though they have a web service interface.
Web service interfaces
If an application exposes a web service interface, meaning a SOAP service described by a Web Service Description Language (WSDL) document, then it may be consumed directly. Such web services can directly be included as part of a composite application or business process.
The latest versions of many applications expose web services, for example SAP, Siebel, Peoplesoft, and E-Business Suite applications provide access to at least some of their functionality through web services.
Technology interfaces
Many applications, such as SAP and Oracle E-Business Suite, currently expose only part of their functionality or no functionality through web service interfaces, but they can still participate in service-oriented architecture. Many applications have adopted an interface that is to some extent based on a standard technology.
Examples of standard technology interfaces include the following:
- Files
- Database tables and stored procedures
- Message queues
While these interfaces may be based on a standard technology, they do not provide a standard data model, and generally, there must be a mapping between the raw technology interface and the more structured web service style interface that we would like.
The following table shows how these interfaces are supported through technology adapters provided with the SOA Suite.
|
Technology |
Adapter |
Notes |
|---|---|---|
|
Files |
File |
Reads and writes files mounted directly on the machine. This can be physically attached disks or network mounted devices (for example, Windows shared drives or NFS drives). |
|
FTP |
Reads and writes files mounted on an FTP server. | |
|
Database |
Database |
Reads and writes database tables and invokes stored procedures. |
|
Message queues |
JMS |
Reads and posts messages to Java Messaging Service (JMS) queues and topics. |
|
AQ |
Reads and posts messages to Oracle AQ (Advanced Queuing) queues. | |
|
MQ |
Reads and posts messages to IBM MQ (Message Queue) Series queues. | |
|
Java |
EJB |
Read and writes to EJBs. |
|
TCP/IP |
Socket |
Reads and writes to raw socket interfaces. |
In addition to the eight technology adapters listed previously, there are other technology adapters available, such as a CICS adapter to connect to IBM mainframes and an adapter to connect to systems running Oracle's Tuxedo transaction processing system. There are many other technology adapters that may be purchased to work with the SOA Suite.
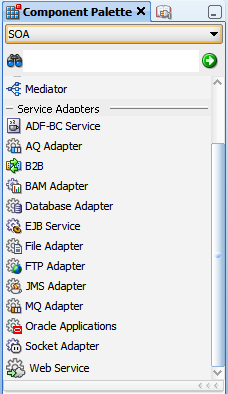
The installed adapters are shown in the Component Palette of JDeveloper in the Service Adapters section when SOA is selected, as shown in the following screenshot:
Application interfaces
The technology adapters leave the task of mapping interfaces and their associated data structures into XML in the hands of the service-enabler. When using an application adapter, such as those for the Oracle E-Business Suite or SAP, the grouping of interfaces and mapping them into XML is already done for you by the adapter developer. These application adapters make life easier for the service-enabler by hiding underlying data formats and transport protocols.
Unfortunately, the topic of application adapters is too large an area to delve into in this book, but you should always check if an application-specific adapter already exists for the system that you want to service-enable. This is because application adapters will be easier to use than the technology adapters.
There are hundreds of third-party adapters that may be purchased to provide SOA Suite with access to functionality within packaged applications.
Java Connector Architecture
Within the SOA Suite, adapters are implemented and accessed using a Java technology known as Java Connector Architecture (JCA). JCA provides a standard packaging and discovery method for adapter functionality. Most of the time, SOA Suite developers will be unaware of JCA because JDeveloper generates a JCA binding as part of a WSDL interface and automatically deploys them with the SCA Assembly. In the current release, JCA adapters must be deployed separately to a WebLogic server for use by the Oracle Service Bus.
Creating services from files
A common mechanism for communicating with an existing application is through a file. Many applications will write their output to a file, expecting it to be picked up and processed by other applications. By using the file adapter, we can create a service representation that makes the file producing application appear as an SOA-enabled service that invokes other services. Similarly, other applications can be configured to take input by reading files. A file adapter allows us to make the production of the file appear as an SOA invocation, but under the covers, the invocation actually creates a file.
File communication is either inbound (this means that a file has been created by an application and must be read) or outbound (this means that a file must be written to provide input to an application). The files that are written and read by existing applications may be in a variety of formats including XML, separator delimited files, or fixed format files.
A payroll use case
Consider a company that has a payroll application that produces a file detailing payments. This file must be transformed into a file format that is accepted by the company's bank and then delivered to the bank via FTP. The company wants to use SOA technologies to perform this transfer because it allows them to perform additional validations or enrichment of the data before sending it to the bank. In addition, they want to store the details of what was sent in a database for audit purposes. In this scenario, a file adapter could be used to take the data from the file, an FTP adapter to deliver it to the bank, and a database adapter could post it into the tables required for audit purposes.
Reading a payroll file
Let's look at how we would read from a payroll file. Normally, we will poll to check for the arrival of a file, although it is also possible to read a file without polling. The key points to be considered beforehand are:
- How often should we poll for the file?
- Do we need to read the contents of the file?
- Do we need to move it to a different location?
- What do we do with the file when we have read or moved it?
- Should we delete it?
- Should we move it to an archive directory?
- How large is the file and its records?
- Does the file have one record or many?
We will consider all these factors as we interact with the File Adapter Wizard.
Starting the wizard
We begin by dragging the file adapter from the component palette in JDeveloper onto either a BPEL process or an SCA Assembly (refer to Chapter 2, Writing your First Composite for more information on building a composite).
This causes the File Adapter Configuration Wizard to start.
Naming the service
Clicking on Next allows us to choose a name for the service that we are creating and optionally a description. We will use the service name PayrollinputFileService. Any name can be used, as long as it has some meaning to the developers. It is a good idea to have a consistent naming convention, for example, identifying the business role (PayrollInput), the technology (File), and the fact that this is a service (PayrollinputFileService).

Identifying the operation
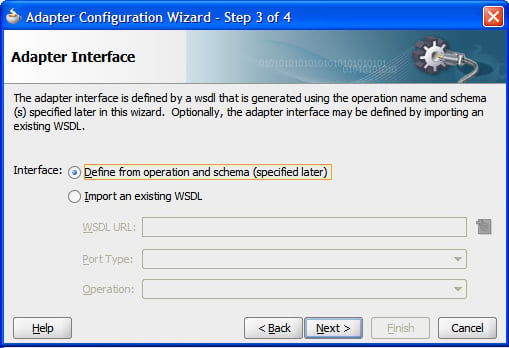
Clicking on Next allows us to either import an existing WSDL definition for our service or create a new service definition. We would import an existing WSDL to reuse an existing adapter configuration that had been created previously. Choosing Define from operation and schema (specified later) allows us to create a new definition.
If we choose to create a new definition, then we start by specifying how we map the files onto a service. It is here that we decide whether we are reading or writing the file. When reading a file, we decide if we wish to generate an event when it is available (a normal Read File operation that requires an inbound operation to receive the message) or if we want to read it only when requested (a Synchronous Read File operation that requires an outbound operation).

Tip
Who calls who?
We usually think of a service as something that we call and then get a result from. However, in reality, services in a service-oriented architecture will often initiate events. These events may be delivered to a BPEL process which is waiting for an event, or routed to another service through the Service Bus, Mediator, or even initiate a whole new SCA Assembly. Under the covers, an adapter might need to poll to detect an event, but the service will always be able to generate an event. With a service, we either call it to get a result or it generates an event that calls some other service or process.
The file adapter wizard exposes four types of operation, as outlined in the following table. We will explore the read operation to generate events as a file is created.
|
Operation Type |
Direction |
Description |
|---|---|---|
|
Read File |
Inbound call from service |
Reads the file and generates one or more calls into BPEL, Mediator, or Service Bus when a file appears. |
|
Write File |
Outbound call to service with no response |
Writes a file, with one or more calls from BPEL, Mediator, or the Service Bus, causing records to be written to a file. |
|
Synchronous Read File |
Outbound call to service returning file contents |
BPEL, Mediator, or Service Bus requests a file to be read, returning nothing if the file doesn't exist. |
|
List Files |
Outbound call to service returning a list of files in a directory |
Provides a means for listing the files in a directory. |
Tip
Why ignore the contents of the file?
The file adapter has an option named Do not read file content. This is used when the file is just a signal for some event. Do not use this feature for the scenario where a file is written and then marked as available by another file being written. This is explicitly handled elsewhere in the file adapter. Instead, the feature can be used as a signal of some event that has no relevant data other than the fact that something has happened. Although the file itself is not readable, certain metadata is made available as part of the message sent.

Defining the file location
Clicking on Next allows us to configure the location of the file. Locations can be specified as either physical (mapped directly onto the filesystem) or logical (an indirection to the real location). The Directory for Incoming Files specifies where the adapter should look to find new files. If the file should appear in a subdirectory of the one specified, then the Process files recursively box should be checked.

The key question now is what to do with the file when it appears. One option is to keep a copy of the file in an archive directory. This is achieved by checking the Archive processed files attribute and providing a location for the file archive. In addition to archiving the file, we need to decide if we want to delete the original file. This is indicated by the Delete files after successful retrieval checkbox.
Tip
Logical versus Physical locations
The file adapter allows us to have logical (Logical Name) or physical locations (Physical Path) for files. Physical locations are easier for developers as we embed the exact file location into the assembly with no more work required. However, this only works if the file locations are the same in the development, test and production environments, particularly unlikely if development is done on Windows but production is on Linux. Hence for production systems, it is best to use logical locations that must be mapped onto physical locations when deployed. Chapter 19, Packaging and Deploying shows how this mapping may be different for each environment.
Selecting specific files
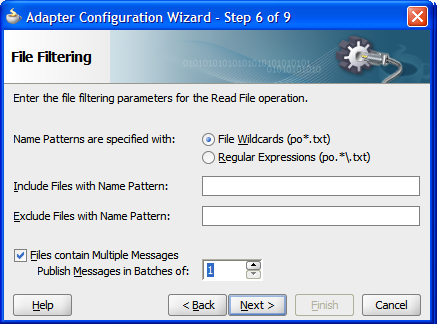
Having defined the location where files are found, we can now move on to the next step in the wizard. Here we describe what the filenames look like. We can describe filenames using either wildcards (using '*' to represent a sequence of 0 or more characters) or using Java regular expressions, as described in the documentation for the java.util.regex.Pattern class. Usually wildcards will be good enough. For example, if we want to select all files that start with "PR" and end with ".txt", then we would use the wildcard string "PR*.txt" or the regular expression "PR.*\.txt". As you can see, it is generally easier to use wildcards rather than regular expressions. We can also specify a pattern to identify which files should not be processed.
The final part of this screen in the adapter wizard asks if the file contains a single message or many messages. This is confusing because when the screen refers to messages, it really means records.
Tip
XML files
It is worth remembering that a well formed XML document can only have a single root element, and hence an XML input file will normally have only a single input record. In the case of very large XML files, it is possible to have the file adapter batch the file up into multiple messages, in which case the root element is replicated in each message, and the second level elements are treated as records. This behavior is requested by setting the streaming option.
By default, a message will contain a single record from the file. Records will be defined in the next step of the wizard. If the file causes a BPEL process to be started, then a 1000 record file would result in 1000 BPEL processes being initiated. To improve efficiency, records can be batched, and the Publish Messages in Batches of attribute controls the maximum number of records in a message.
Tip
Message batching
It is common for an incoming file to contain many records. These records, when processed, can impact system performance and memory requirements. Hence it is important to align the use of the records with their likely impact on system resources.
Detecting that the file is available
The next step in the wizard allows us to configure the frequency of polling for the inbound file. There are two parameters that can be configured here–the Polling Frequency and the Minimum File Age.

The Polling Frequency just means the time delay between checking to see if a file is available for processing. The adapter will check once per interval to see if the file exists. Setting this too low can consume needless CPU resources, setting it too high can make the system appear unresponsive. 'Too high' and 'too low' are very subjective and will depend on your individual requirements. For example, the polling interval for a file that is expected to be written twice a day may be set to three hours, while the interval for a file that is expected to be written every hour may be set to 15 minutes.
Minimum File Age specifies how old a file must be before it is processed by the adapter. This setting allows a file to be completely written before it is read. For example, a large file may take five minutes to write out from the original application. If the file is read three minutes after it has been created, then it is possible for the adapter to run out of records to read and assume the file has been processed, when in reality, the application is still writing to the file. Setting a minimum age to ten minutes would avoid this problem by giving the application at least ten minutes to write the file.
As an alternative to polling for a file directly, we may use a trigger file to indicate that a file is available. Some systems write large files to disk and then indicate that they are available by writing a trigger file. This avoids the problems with reading an incomplete file we identified in the previous paragraph, without the delay in processing the file that a minimum age field may cause.
Message format
The penultimate step in the file adapter is to set up the format of records or messages in the file. This is one of the most critical steps, as this defines the format of messages generated by a file.
Messages may be opaque, meaning that they are passed around as black boxes. This may be appropriate with a Microsoft Word file, for example, that must merely be transported from point A to point B without being examined. This is indicated by the Native format translation is not required (Schema is Opaque) checkbox.
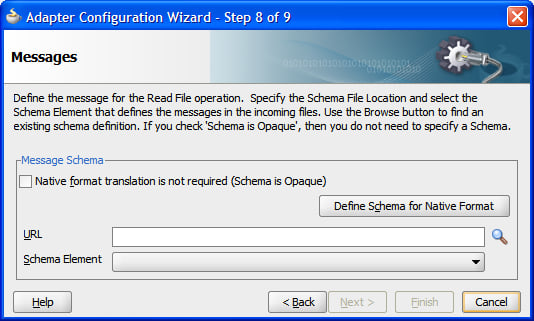
If the document is already in an XML format, then we can just specify a schema and an expected root element and the job is done. Normally the file is in some non-XML format that must be mapped onto an XML Schema generated through the native format builder wizard, which is invoked through the Define Schema for Native Format button.
Defining a native format schema
Invoking the Native Format Builder wizard brings up an initial start screen that leads on to the first step in the wizard, choosing the type of format, as shown in the following screenshot:

This allows us to identify the overall record structure. If we have an existing schema document that describes the record structure, then we can point to that. Usually, we will need to determine the type of structure of the file ourselves. The choices available are:
- Delimited: These are files such as CSV files (Comma Separated Values), records with spaces, or '+' signs for separators.
- Fixed Length: These are files whose records consist of fixed length fields. Be careful not to confuse these with space-separated files, as if a value does not fill the entire field, it will usually be padded with spaces.
- Complex Type: These files may include nested records like a master detail type structure.
- DTD to be converted to XSD: These are XML Data Type Definition XML files that will be mapped onto an XML Schema description of the file content.
- Cobol Copybook to be converted to native format: These are files that have usually been produced by a COBOL system, often originating from a mainframe.
We will look at a delimited file, as it is one of the most common formats.
Although we are using the separator file type, the steps involved are basically the same for most file types including the fixed length field format, which is also extremely common.
Using a sample file
To make it easier to describe the format of the incoming file, the wizard asks us to specify a file to use as a sample. If necessary, we can skip rows in the file and determine the number of records to read. Obviously, reading a very large number of records may take a while, and if all the variability on the file is in the first ten records, then there is no point in wasting time reading any more sample records. We may also choose to restrict the number of rows processed at runtime.
Setting the character set needs to be done carefully, particularly in international environments where non-ASCII character sets may be common.
After selecting a sample file, the wizard will display an initial view of the file with a guess at the field separators.
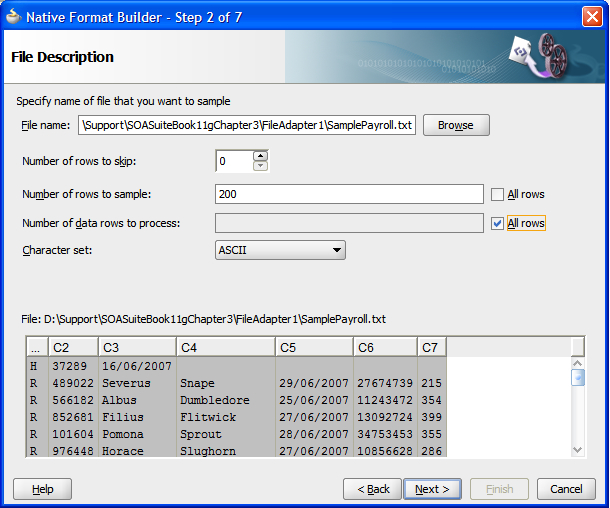
Record structure
The next step of the wizard allows us to describe how the records appear in the file.
The first option File contains only one record allows us to process the file as a single message. This can be useful when the file has multiple records, all of the same format, which we want to read as a single message. Use of this option disables batching.
The next option of File contains multiple record instances allows batching to take place. Records are either of the same type or of different types. They can only be marked of different types if they can be distinguished, based on the first field in the record. In other words, in order to choose the Multiple records are of different types, the first field in all the records must be a record type identifier. In the example shown in the preceding screenshot, the first field is either an H for Header records or an R for Records.

Choosing a root element
The next step allows us to define the target namespace and root element of the schema that we are generating.

Note
Don't forget that when using the Native Format Builder wizard, we are just creating an XML Schema document that describes the native (non-XML) format data. Most of the time this schema is transparent to us. However, at times the XML constructs have to emerge, for example, when identifying a name for a root element. The file is described using an XML Schema extension known as NXSD.
As we can see the root element is mandatory. This root element acts as a wrapper for the records in a message. If message batching is set to 1, then each wrapper will have a single sub-element, namely, the record. If the message is set to greater than 1, then each wrapper will have at least one and possibly more sub-elements, each sub-element being a record. There can never be more sub-elements than the batch size.
Message delimiters
Having described the overall structure of the file, we can now drill down into the individual fields. To do this, we first specify the message delimiters.
In addition to field delimiters, we can also specify a record delimiter. Usually record delimiters are new lines. If fields are also wrapped in quotation marks, then these can be stripped off by specifying the Optionally enclosed by character.

Record type names
The wizard will identify the types of records based on the first field in each record, as shown in the preceding screenshot. It is possible to ignore record types by selecting them and clicking Delete. If this is done by mistake, then it is possible to add them back by using the Add button. Only fields that exist in the sample data can be added in the wizard.
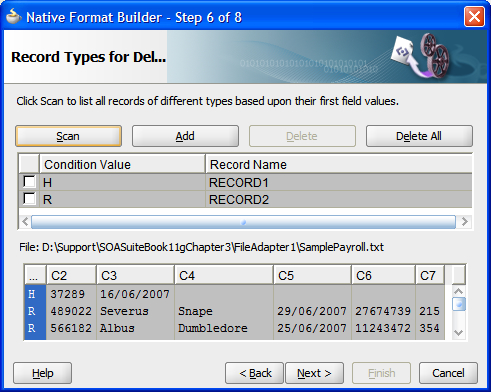
Note that if we want to reset the record types screen, then the Scan button will rescan the sample file and look for all the different record types it contains.
The Record Name field can be set by double-clicking it and providing a suitable record name. This record name is the XML element name that encapsulates the record content.
Field properties
Now that we have identified record and field boundaries, we can drill down into the records and define the data types and names of individual fields. This is done for each record type in turn. We can select which records to define by selecting them from the Record Name drop-down box or by pressing the Next Record Type button.
It is important to be as liberal as possible when defining field data types because any mismatches will cause errors that will need to be handled. Being liberal in our record definitions will allow us to validate the messages, as described in Chapter 13, Building Validation into Services, without raising system errors.

The Name column represents the element name of this field. The wizard will attempt to guess the type of the field, but it is important to always check this because the sample data you are using may not include all possibilities. A common error is identifying numbers to be tagged as integers, when they should really be strings—accept integer types only when they are likely to have arithmetic operations performed on them.
Verifying the result
We have now completed our mapping and can verify what has been done by looking at the generated XML Schema file. Note that the generated schema uses some Oracle extensions to enable a non-XML formatted file to be represented as XML. In particular the nxsd namespace prefix is used to identify field separators and record terminators.
Note
The XML Schema generated can be edited manually. This is useful to support nested records (records inside other records) like those that may be found in a file containing order records with nested detail records (an order record contains multiple line item detail records). In this case, it is useful to use the wizard to generate a schema with order records and detail records at the same level. The schema can then be modified by hand to make the detail records children of the order records.
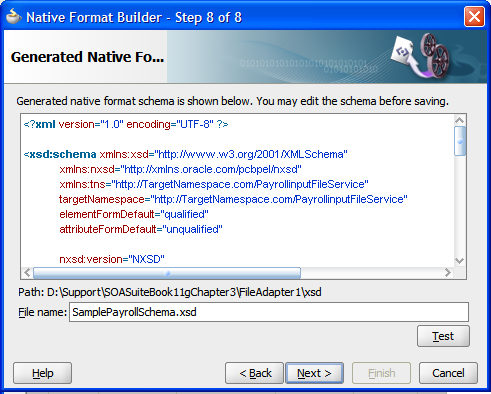
Clicking the Test button brings up a simple test screen that allows us to apply our newly generated schema to the input document and examine the resulting XML.

Clicking Next and then Finish will cause the generated schema file to be saved.
Finishing the wizards
Until now, no work has been saved, except for the XML Schema mapping the file content onto an XML structure. The rest of the adapter settings are not saved, and the endpoint is not set up until the Finish button is clicked on the completion screen, as shown in the following screenshot. Note that the file generated is a Web Service Description Language (WSDL) file with a JCA binding.

Throttling the file and FTP adapter
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Creating a dummy message type
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>Adding an output message to the read operation
In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
Using the modified interface
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
Writing a payroll file
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
Selecting the FTP connection
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
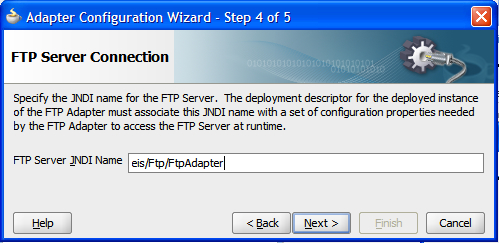
Choosing the operation
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.

Selecting the file destination
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
Note
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.

The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Tip
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Moving, copying, and deleting files
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
Adapter headers
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
Testing the file adapters
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.

A payroll use case
Consider a company that has a payroll application that produces a file detailing payments. This file must be transformed into a file format that is accepted by the company's bank and then delivered to the bank via FTP. The company wants to use SOA technologies to perform this transfer because it allows them to perform additional validations or enrichment of the data before sending it to the bank. In addition, they want to store the details of what was sent in a database for audit purposes. In this scenario, a file adapter could be used to take the data from the file, an FTP adapter to deliver it to the bank, and a database adapter could post it into the tables required for audit purposes.
Reading a payroll file
Let's look at how we would read from a payroll file. Normally, we will poll to check for the arrival of a file, although it is also possible to read a file without polling. The key points to be considered beforehand are:
- How often should we poll for the file?
- Do we need to read the contents of the file?
- Do we need to move it to a different location?
- What do we do with the file when we have read or moved it?
- Should we delete it?
- Should we move it to an archive directory?
- How large is the file and its records?
- Does the file have one record or many?
We will consider all these factors as we interact with the File Adapter Wizard.
Starting the wizard
We begin by dragging the file adapter from the component palette in JDeveloper onto either a BPEL process or an SCA Assembly (refer to Chapter 2, Writing your First Composite for more information on building a composite).
This causes the File Adapter Configuration Wizard to start.
Naming the service
Clicking on Next allows us to choose a name for the service that we are creating and optionally a description. We will use the service name PayrollinputFileService. Any name can be used, as long as it has some meaning to the developers. It is a good idea to have a consistent naming convention, for example, identifying the business role (PayrollInput), the technology (File), and the fact that this is a service (PayrollinputFileService).
Identifying the operation
Clicking on Next allows us to either import an existing WSDL definition for our service or create a new service definition. We would import an existing WSDL to reuse an existing adapter configuration that had been created previously. Choosing Define from operation and schema (specified later) allows us to create a new definition.
If we choose to create a new definition, then we start by specifying how we map the files onto a service. It is here that we decide whether we are reading or writing the file. When reading a file, we decide if we wish to generate an event when it is available (a normal Read File operation that requires an inbound operation to receive the message) or if we want to read it only when requested (a Synchronous Read File operation that requires an outbound operation).
Tip
Who calls who?
We usually think of a service as something that we call and then get a result from. However, in reality, services in a service-oriented architecture will often initiate events. These events may be delivered to a BPEL process which is waiting for an event, or routed to another service through the Service Bus, Mediator, or even initiate a whole new SCA Assembly. Under the covers, an adapter might need to poll to detect an event, but the service will always be able to generate an event. With a service, we either call it to get a result or it generates an event that calls some other service or process.
The file adapter wizard exposes four types of operation, as outlined in the following table. We will explore the read operation to generate events as a file is created.
|
Operation Type |
Direction |
Description |
|---|---|---|
|
Read File |
Inbound call from service |
Reads the file and generates one or more calls into BPEL, Mediator, or Service Bus when a file appears. |
|
Write File |
Outbound call to service with no response |
Writes a file, with one or more calls from BPEL, Mediator, or the Service Bus, causing records to be written to a file. |
|
Synchronous Read File |
Outbound call to service returning file contents |
BPEL, Mediator, or Service Bus requests a file to be read, returning nothing if the file doesn't exist. |
|
List Files |
Outbound call to service returning a list of files in a directory |
Provides a means for listing the files in a directory. |
Tip
Why ignore the contents of the file?
The file adapter has an option named Do not read file content. This is used when the file is just a signal for some event. Do not use this feature for the scenario where a file is written and then marked as available by another file being written. This is explicitly handled elsewhere in the file adapter. Instead, the feature can be used as a signal of some event that has no relevant data other than the fact that something has happened. Although the file itself is not readable, certain metadata is made available as part of the message sent.
Defining the file location
Clicking on Next allows us to configure the location of the file. Locations can be specified as either physical (mapped directly onto the filesystem) or logical (an indirection to the real location). The Directory for Incoming Files specifies where the adapter should look to find new files. If the file should appear in a subdirectory of the one specified, then the Process files recursively box should be checked.
The key question now is what to do with the file when it appears. One option is to keep a copy of the file in an archive directory. This is achieved by checking the Archive processed files attribute and providing a location for the file archive. In addition to archiving the file, we need to decide if we want to delete the original file. This is indicated by the Delete files after successful retrieval checkbox.
Tip
Logical versus Physical locations
The file adapter allows us to have logical (Logical Name) or physical locations (Physical Path) for files. Physical locations are easier for developers as we embed the exact file location into the assembly with no more work required. However, this only works if the file locations are the same in the development, test and production environments, particularly unlikely if development is done on Windows but production is on Linux. Hence for production systems, it is best to use logical locations that must be mapped onto physical locations when deployed. Chapter 19, Packaging and Deploying shows how this mapping may be different for each environment.
Selecting specific files
Having defined the location where files are found, we can now move on to the next step in the wizard. Here we describe what the filenames look like. We can describe filenames using either wildcards (using '*' to represent a sequence of 0 or more characters) or using Java regular expressions, as described in the documentation for the java.util.regex.Pattern class. Usually wildcards will be good enough. For example, if we want to select all files that start with "PR" and end with ".txt", then we would use the wildcard string "PR*.txt" or the regular expression "PR.*\.txt". As you can see, it is generally easier to use wildcards rather than regular expressions. We can also specify a pattern to identify which files should not be processed.
The final part of this screen in the adapter wizard asks if the file contains a single message or many messages. This is confusing because when the screen refers to messages, it really means records.
Tip
XML files
It is worth remembering that a well formed XML document can only have a single root element, and hence an XML input file will normally have only a single input record. In the case of very large XML files, it is possible to have the file adapter batch the file up into multiple messages, in which case the root element is replicated in each message, and the second level elements are treated as records. This behavior is requested by setting the streaming option.
By default, a message will contain a single record from the file. Records will be defined in the next step of the wizard. If the file causes a BPEL process to be started, then a 1000 record file would result in 1000 BPEL processes being initiated. To improve efficiency, records can be batched, and the Publish Messages in Batches of attribute controls the maximum number of records in a message.
Tip
Message batching
It is common for an incoming file to contain many records. These records, when processed, can impact system performance and memory requirements. Hence it is important to align the use of the records with their likely impact on system resources.
Detecting that the file is available
The next step in the wizard allows us to configure the frequency of polling for the inbound file. There are two parameters that can be configured here–the Polling Frequency and the Minimum File Age.
The Polling Frequency just means the time delay between checking to see if a file is available for processing. The adapter will check once per interval to see if the file exists. Setting this too low can consume needless CPU resources, setting it too high can make the system appear unresponsive. 'Too high' and 'too low' are very subjective and will depend on your individual requirements. For example, the polling interval for a file that is expected to be written twice a day may be set to three hours, while the interval for a file that is expected to be written every hour may be set to 15 minutes.
Minimum File Age specifies how old a file must be before it is processed by the adapter. This setting allows a file to be completely written before it is read. For example, a large file may take five minutes to write out from the original application. If the file is read three minutes after it has been created, then it is possible for the adapter to run out of records to read and assume the file has been processed, when in reality, the application is still writing to the file. Setting a minimum age to ten minutes would avoid this problem by giving the application at least ten minutes to write the file.
As an alternative to polling for a file directly, we may use a trigger file to indicate that a file is available. Some systems write large files to disk and then indicate that they are available by writing a trigger file. This avoids the problems with reading an incomplete file we identified in the previous paragraph, without the delay in processing the file that a minimum age field may cause.
Message format
The penultimate step in the file adapter is to set up the format of records or messages in the file. This is one of the most critical steps, as this defines the format of messages generated by a file.
Messages may be opaque, meaning that they are passed around as black boxes. This may be appropriate with a Microsoft Word file, for example, that must merely be transported from point A to point B without being examined. This is indicated by the Native format translation is not required (Schema is Opaque) checkbox.
If the document is already in an XML format, then we can just specify a schema and an expected root element and the job is done. Normally the file is in some non-XML format that must be mapped onto an XML Schema generated through the native format builder wizard, which is invoked through the Define Schema for Native Format button.
Defining a native format schema
Invoking the Native Format Builder wizard brings up an initial start screen that leads on to the first step in the wizard, choosing the type of format, as shown in the following screenshot:
This allows us to identify the overall record structure. If we have an existing schema document that describes the record structure, then we can point to that. Usually, we will need to determine the type of structure of the file ourselves. The choices available are:
- Delimited: These are files such as CSV files (Comma Separated Values), records with spaces, or '+' signs for separators.
- Fixed Length: These are files whose records consist of fixed length fields. Be careful not to confuse these with space-separated files, as if a value does not fill the entire field, it will usually be padded with spaces.
- Complex Type: These files may include nested records like a master detail type structure.
- DTD to be converted to XSD: These are XML Data Type Definition XML files that will be mapped onto an XML Schema description of the file content.
- Cobol Copybook to be converted to native format: These are files that have usually been produced by a COBOL system, often originating from a mainframe.
We will look at a delimited file, as it is one of the most common formats.
Although we are using the separator file type, the steps involved are basically the same for most file types including the fixed length field format, which is also extremely common.
Using a sample file
To make it easier to describe the format of the incoming file, the wizard asks us to specify a file to use as a sample. If necessary, we can skip rows in the file and determine the number of records to read. Obviously, reading a very large number of records may take a while, and if all the variability on the file is in the first ten records, then there is no point in wasting time reading any more sample records. We may also choose to restrict the number of rows processed at runtime.
Setting the character set needs to be done carefully, particularly in international environments where non-ASCII character sets may be common.
After selecting a sample file, the wizard will display an initial view of the file with a guess at the field separators.
Record structure
The next step of the wizard allows us to describe how the records appear in the file.
The first option File contains only one record allows us to process the file as a single message. This can be useful when the file has multiple records, all of the same format, which we want to read as a single message. Use of this option disables batching.
The next option of File contains multiple record instances allows batching to take place. Records are either of the same type or of different types. They can only be marked of different types if they can be distinguished, based on the first field in the record. In other words, in order to choose the Multiple records are of different types, the first field in all the records must be a record type identifier. In the example shown in the preceding screenshot, the first field is either an H for Header records or an R for Records.
Choosing a root element
The next step allows us to define the target namespace and root element of the schema that we are generating.
Note
Don't forget that when using the Native Format Builder wizard, we are just creating an XML Schema document that describes the native (non-XML) format data. Most of the time this schema is transparent to us. However, at times the XML constructs have to emerge, for example, when identifying a name for a root element. The file is described using an XML Schema extension known as NXSD.
As we can see the root element is mandatory. This root element acts as a wrapper for the records in a message. If message batching is set to 1, then each wrapper will have a single sub-element, namely, the record. If the message is set to greater than 1, then each wrapper will have at least one and possibly more sub-elements, each sub-element being a record. There can never be more sub-elements than the batch size.
Message delimiters
Having described the overall structure of the file, we can now drill down into the individual fields. To do this, we first specify the message delimiters.
In addition to field delimiters, we can also specify a record delimiter. Usually record delimiters are new lines. If fields are also wrapped in quotation marks, then these can be stripped off by specifying the Optionally enclosed by character.
Record type names
The wizard will identify the types of records based on the first field in each record, as shown in the preceding screenshot. It is possible to ignore record types by selecting them and clicking Delete. If this is done by mistake, then it is possible to add them back by using the Add button. Only fields that exist in the sample data can be added in the wizard.
Note that if we want to reset the record types screen, then the Scan button will rescan the sample file and look for all the different record types it contains.
The Record Name field can be set by double-clicking it and providing a suitable record name. This record name is the XML element name that encapsulates the record content.
Field properties
Now that we have identified record and field boundaries, we can drill down into the records and define the data types and names of individual fields. This is done for each record type in turn. We can select which records to define by selecting them from the Record Name drop-down box or by pressing the Next Record Type button.
It is important to be as liberal as possible when defining field data types because any mismatches will cause errors that will need to be handled. Being liberal in our record definitions will allow us to validate the messages, as described in Chapter 13, Building Validation into Services, without raising system errors.
The Name column represents the element name of this field. The wizard will attempt to guess the type of the field, but it is important to always check this because the sample data you are using may not include all possibilities. A common error is identifying numbers to be tagged as integers, when they should really be strings—accept integer types only when they are likely to have arithmetic operations performed on them.
Verifying the result
We have now completed our mapping and can verify what has been done by looking at the generated XML Schema file. Note that the generated schema uses some Oracle extensions to enable a non-XML formatted file to be represented as XML. In particular the nxsd namespace prefix is used to identify field separators and record terminators.
Note
The XML Schema generated can be edited manually. This is useful to support nested records (records inside other records) like those that may be found in a file containing order records with nested detail records (an order record contains multiple line item detail records). In this case, it is useful to use the wizard to generate a schema with order records and detail records at the same level. The schema can then be modified by hand to make the detail records children of the order records.
Clicking the Test button brings up a simple test screen that allows us to apply our newly generated schema to the input document and examine the resulting XML.
Clicking Next and then Finish will cause the generated schema file to be saved.
Finishing the wizards
Until now, no work has been saved, except for the XML Schema mapping the file content onto an XML structure. The rest of the adapter settings are not saved, and the endpoint is not set up until the Finish button is clicked on the completion screen, as shown in the following screenshot. Note that the file generated is a Web Service Description Language (WSDL) file with a JCA binding.
Throttling the file and FTP adapter
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Creating a dummy message type
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>Adding an output message to the read operation
In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
Using the modified interface
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
Writing a payroll file
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
Selecting the FTP connection
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
Choosing the operation
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Selecting the file destination
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
Note
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Tip
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Moving, copying, and deleting files
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
Adapter headers
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
Testing the file adapters
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Reading a payroll file
Let's look at how we would read from a payroll file. Normally, we will poll to check for the arrival of a file, although it is also possible to read a file without polling. The key points to be considered beforehand are:
- How often should we poll for the file?
- Do we need to read the contents of the file?
- Do we need to move it to a different location?
- What do we do with the file when we have read or moved it?
- Should we delete it?
- Should we move it to an archive directory?
- How large is the file and its records?
- Does the file have one record or many?
We will consider all these factors as we interact with the File Adapter Wizard.
Starting the wizard
We begin by dragging the file adapter from the component palette in JDeveloper onto either a BPEL process or an SCA Assembly (refer to Chapter 2, Writing your First Composite for more information on building a composite).
This causes the File Adapter Configuration Wizard to start.
Naming the service
Clicking on Next allows us to choose a name for the service that we are creating and optionally a description. We will use the service name PayrollinputFileService. Any name can be used, as long as it has some meaning to the developers. It is a good idea to have a consistent naming convention, for example, identifying the business role (PayrollInput), the technology (File), and the fact that this is a service (PayrollinputFileService).
Identifying the operation
Clicking on Next allows us to either import an existing WSDL definition for our service or create a new service definition. We would import an existing WSDL to reuse an existing adapter configuration that had been created previously. Choosing Define from operation and schema (specified later) allows us to create a new definition.
If we choose to create a new definition, then we start by specifying how we map the files onto a service. It is here that we decide whether we are reading or writing the file. When reading a file, we decide if we wish to generate an event when it is available (a normal Read File operation that requires an inbound operation to receive the message) or if we want to read it only when requested (a Synchronous Read File operation that requires an outbound operation).
Tip
Who calls who?
We usually think of a service as something that we call and then get a result from. However, in reality, services in a service-oriented architecture will often initiate events. These events may be delivered to a BPEL process which is waiting for an event, or routed to another service through the Service Bus, Mediator, or even initiate a whole new SCA Assembly. Under the covers, an adapter might need to poll to detect an event, but the service will always be able to generate an event. With a service, we either call it to get a result or it generates an event that calls some other service or process.
The file adapter wizard exposes four types of operation, as outlined in the following table. We will explore the read operation to generate events as a file is created.
|
Operation Type |
Direction |
Description |
|---|---|---|
|
Read File |
Inbound call from service |
Reads the file and generates one or more calls into BPEL, Mediator, or Service Bus when a file appears. |
|
Write File |
Outbound call to service with no response |
Writes a file, with one or more calls from BPEL, Mediator, or the Service Bus, causing records to be written to a file. |
|
Synchronous Read File |
Outbound call to service returning file contents |
BPEL, Mediator, or Service Bus requests a file to be read, returning nothing if the file doesn't exist. |
|
List Files |
Outbound call to service returning a list of files in a directory |
Provides a means for listing the files in a directory. |
Tip
Why ignore the contents of the file?
The file adapter has an option named Do not read file content. This is used when the file is just a signal for some event. Do not use this feature for the scenario where a file is written and then marked as available by another file being written. This is explicitly handled elsewhere in the file adapter. Instead, the feature can be used as a signal of some event that has no relevant data other than the fact that something has happened. Although the file itself is not readable, certain metadata is made available as part of the message sent.
Defining the file location
Clicking on Next allows us to configure the location of the file. Locations can be specified as either physical (mapped directly onto the filesystem) or logical (an indirection to the real location). The Directory for Incoming Files specifies where the adapter should look to find new files. If the file should appear in a subdirectory of the one specified, then the Process files recursively box should be checked.
The key question now is what to do with the file when it appears. One option is to keep a copy of the file in an archive directory. This is achieved by checking the Archive processed files attribute and providing a location for the file archive. In addition to archiving the file, we need to decide if we want to delete the original file. This is indicated by the Delete files after successful retrieval checkbox.
Tip
Logical versus Physical locations
The file adapter allows us to have logical (Logical Name) or physical locations (Physical Path) for files. Physical locations are easier for developers as we embed the exact file location into the assembly with no more work required. However, this only works if the file locations are the same in the development, test and production environments, particularly unlikely if development is done on Windows but production is on Linux. Hence for production systems, it is best to use logical locations that must be mapped onto physical locations when deployed. Chapter 19, Packaging and Deploying shows how this mapping may be different for each environment.
Selecting specific files
Having defined the location where files are found, we can now move on to the next step in the wizard. Here we describe what the filenames look like. We can describe filenames using either wildcards (using '*' to represent a sequence of 0 or more characters) or using Java regular expressions, as described in the documentation for the java.util.regex.Pattern class. Usually wildcards will be good enough. For example, if we want to select all files that start with "PR" and end with ".txt", then we would use the wildcard string "PR*.txt" or the regular expression "PR.*\.txt". As you can see, it is generally easier to use wildcards rather than regular expressions. We can also specify a pattern to identify which files should not be processed.
The final part of this screen in the adapter wizard asks if the file contains a single message or many messages. This is confusing because when the screen refers to messages, it really means records.
Tip
XML files
It is worth remembering that a well formed XML document can only have a single root element, and hence an XML input file will normally have only a single input record. In the case of very large XML files, it is possible to have the file adapter batch the file up into multiple messages, in which case the root element is replicated in each message, and the second level elements are treated as records. This behavior is requested by setting the streaming option.
By default, a message will contain a single record from the file. Records will be defined in the next step of the wizard. If the file causes a BPEL process to be started, then a 1000 record file would result in 1000 BPEL processes being initiated. To improve efficiency, records can be batched, and the Publish Messages in Batches of attribute controls the maximum number of records in a message.
Tip
Message batching
It is common for an incoming file to contain many records. These records, when processed, can impact system performance and memory requirements. Hence it is important to align the use of the records with their likely impact on system resources.
Detecting that the file is available
The next step in the wizard allows us to configure the frequency of polling for the inbound file. There are two parameters that can be configured here–the Polling Frequency and the Minimum File Age.
The Polling Frequency just means the time delay between checking to see if a file is available for processing. The adapter will check once per interval to see if the file exists. Setting this too low can consume needless CPU resources, setting it too high can make the system appear unresponsive. 'Too high' and 'too low' are very subjective and will depend on your individual requirements. For example, the polling interval for a file that is expected to be written twice a day may be set to three hours, while the interval for a file that is expected to be written every hour may be set to 15 minutes.
Minimum File Age specifies how old a file must be before it is processed by the adapter. This setting allows a file to be completely written before it is read. For example, a large file may take five minutes to write out from the original application. If the file is read three minutes after it has been created, then it is possible for the adapter to run out of records to read and assume the file has been processed, when in reality, the application is still writing to the file. Setting a minimum age to ten minutes would avoid this problem by giving the application at least ten minutes to write the file.
As an alternative to polling for a file directly, we may use a trigger file to indicate that a file is available. Some systems write large files to disk and then indicate that they are available by writing a trigger file. This avoids the problems with reading an incomplete file we identified in the previous paragraph, without the delay in processing the file that a minimum age field may cause.
Message format
The penultimate step in the file adapter is to set up the format of records or messages in the file. This is one of the most critical steps, as this defines the format of messages generated by a file.
Messages may be opaque, meaning that they are passed around as black boxes. This may be appropriate with a Microsoft Word file, for example, that must merely be transported from point A to point B without being examined. This is indicated by the Native format translation is not required (Schema is Opaque) checkbox.
If the document is already in an XML format, then we can just specify a schema and an expected root element and the job is done. Normally the file is in some non-XML format that must be mapped onto an XML Schema generated through the native format builder wizard, which is invoked through the Define Schema for Native Format button.
Defining a native format schema
Invoking the Native Format Builder wizard brings up an initial start screen that leads on to the first step in the wizard, choosing the type of format, as shown in the following screenshot:
This allows us to identify the overall record structure. If we have an existing schema document that describes the record structure, then we can point to that. Usually, we will need to determine the type of structure of the file ourselves. The choices available are:
- Delimited: These are files such as CSV files (Comma Separated Values), records with spaces, or '+' signs for separators.
- Fixed Length: These are files whose records consist of fixed length fields. Be careful not to confuse these with space-separated files, as if a value does not fill the entire field, it will usually be padded with spaces.
- Complex Type: These files may include nested records like a master detail type structure.
- DTD to be converted to XSD: These are XML Data Type Definition XML files that will be mapped onto an XML Schema description of the file content.
- Cobol Copybook to be converted to native format: These are files that have usually been produced by a COBOL system, often originating from a mainframe.
We will look at a delimited file, as it is one of the most common formats.
Although we are using the separator file type, the steps involved are basically the same for most file types including the fixed length field format, which is also extremely common.
Using a sample file
To make it easier to describe the format of the incoming file, the wizard asks us to specify a file to use as a sample. If necessary, we can skip rows in the file and determine the number of records to read. Obviously, reading a very large number of records may take a while, and if all the variability on the file is in the first ten records, then there is no point in wasting time reading any more sample records. We may also choose to restrict the number of rows processed at runtime.
Setting the character set needs to be done carefully, particularly in international environments where non-ASCII character sets may be common.
After selecting a sample file, the wizard will display an initial view of the file with a guess at the field separators.
Record structure
The next step of the wizard allows us to describe how the records appear in the file.
The first option File contains only one record allows us to process the file as a single message. This can be useful when the file has multiple records, all of the same format, which we want to read as a single message. Use of this option disables batching.
The next option of File contains multiple record instances allows batching to take place. Records are either of the same type or of different types. They can only be marked of different types if they can be distinguished, based on the first field in the record. In other words, in order to choose the Multiple records are of different types, the first field in all the records must be a record type identifier. In the example shown in the preceding screenshot, the first field is either an H for Header records or an R for Records.
Choosing a root element
The next step allows us to define the target namespace and root element of the schema that we are generating.
Note
Don't forget that when using the Native Format Builder wizard, we are just creating an XML Schema document that describes the native (non-XML) format data. Most of the time this schema is transparent to us. However, at times the XML constructs have to emerge, for example, when identifying a name for a root element. The file is described using an XML Schema extension known as NXSD.
As we can see the root element is mandatory. This root element acts as a wrapper for the records in a message. If message batching is set to 1, then each wrapper will have a single sub-element, namely, the record. If the message is set to greater than 1, then each wrapper will have at least one and possibly more sub-elements, each sub-element being a record. There can never be more sub-elements than the batch size.
Message delimiters
Having described the overall structure of the file, we can now drill down into the individual fields. To do this, we first specify the message delimiters.
In addition to field delimiters, we can also specify a record delimiter. Usually record delimiters are new lines. If fields are also wrapped in quotation marks, then these can be stripped off by specifying the Optionally enclosed by character.
Record type names
The wizard will identify the types of records based on the first field in each record, as shown in the preceding screenshot. It is possible to ignore record types by selecting them and clicking Delete. If this is done by mistake, then it is possible to add them back by using the Add button. Only fields that exist in the sample data can be added in the wizard.
Note that if we want to reset the record types screen, then the Scan button will rescan the sample file and look for all the different record types it contains.
The Record Name field can be set by double-clicking it and providing a suitable record name. This record name is the XML element name that encapsulates the record content.
Field properties
Now that we have identified record and field boundaries, we can drill down into the records and define the data types and names of individual fields. This is done for each record type in turn. We can select which records to define by selecting them from the Record Name drop-down box or by pressing the Next Record Type button.
It is important to be as liberal as possible when defining field data types because any mismatches will cause errors that will need to be handled. Being liberal in our record definitions will allow us to validate the messages, as described in Chapter 13, Building Validation into Services, without raising system errors.
The Name column represents the element name of this field. The wizard will attempt to guess the type of the field, but it is important to always check this because the sample data you are using may not include all possibilities. A common error is identifying numbers to be tagged as integers, when they should really be strings—accept integer types only when they are likely to have arithmetic operations performed on them.
Verifying the result
We have now completed our mapping and can verify what has been done by looking at the generated XML Schema file. Note that the generated schema uses some Oracle extensions to enable a non-XML formatted file to be represented as XML. In particular the nxsd namespace prefix is used to identify field separators and record terminators.
Note
The XML Schema generated can be edited manually. This is useful to support nested records (records inside other records) like those that may be found in a file containing order records with nested detail records (an order record contains multiple line item detail records). In this case, it is useful to use the wizard to generate a schema with order records and detail records at the same level. The schema can then be modified by hand to make the detail records children of the order records.
Clicking the Test button brings up a simple test screen that allows us to apply our newly generated schema to the input document and examine the resulting XML.
Clicking Next and then Finish will cause the generated schema file to be saved.
Finishing the wizards
Until now, no work has been saved, except for the XML Schema mapping the file content onto an XML structure. The rest of the adapter settings are not saved, and the endpoint is not set up until the Finish button is clicked on the completion screen, as shown in the following screenshot. Note that the file generated is a Web Service Description Language (WSDL) file with a JCA binding.
Throttling the file and FTP adapter
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Creating a dummy message type
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>Adding an output message to the read operation
In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
Using the modified interface
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
Writing a payroll file
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
Selecting the FTP connection
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
Choosing the operation
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Selecting the file destination
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
Note
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Tip
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Moving, copying, and deleting files
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
Adapter headers
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
Testing the file adapters
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Starting the wizard
We begin by dragging the file adapter from the component palette in JDeveloper onto either a BPEL process or an SCA Assembly (refer to Chapter 2, Writing your First Composite for more information on building a composite).
This causes the File Adapter Configuration Wizard to start.
Naming the service
Clicking on Next allows us to choose a name for the service that we are creating and optionally a description. We will use the service name PayrollinputFileService. Any name can be used, as long as it has some meaning to the developers. It is a good idea to have a consistent naming convention, for example, identifying the business role (PayrollInput), the technology (File), and the fact that this is a service (PayrollinputFileService).
Identifying the operation
Clicking on Next allows us to either import an existing WSDL definition for our service or create a new service definition. We would import an existing WSDL to reuse an existing adapter configuration that had been created previously. Choosing Define from operation and schema (specified later) allows us to create a new definition.
If we choose to create a new definition, then we start by specifying how we map the files onto a service. It is here that we decide whether we are reading or writing the file. When reading a file, we decide if we wish to generate an event when it is available (a normal Read File operation that requires an inbound operation to receive the message) or if we want to read it only when requested (a Synchronous Read File operation that requires an outbound operation).
Tip
Who calls who?
We usually think of a service as something that we call and then get a result from. However, in reality, services in a service-oriented architecture will often initiate events. These events may be delivered to a BPEL process which is waiting for an event, or routed to another service through the Service Bus, Mediator, or even initiate a whole new SCA Assembly. Under the covers, an adapter might need to poll to detect an event, but the service will always be able to generate an event. With a service, we either call it to get a result or it generates an event that calls some other service or process.
The file adapter wizard exposes four types of operation, as outlined in the following table. We will explore the read operation to generate events as a file is created.
|
Operation Type |
Direction |
Description |
|---|---|---|
|
Read File |
Inbound call from service |
Reads the file and generates one or more calls into BPEL, Mediator, or Service Bus when a file appears. |
|
Write File |
Outbound call to service with no response |
Writes a file, with one or more calls from BPEL, Mediator, or the Service Bus, causing records to be written to a file. |
|
Synchronous Read File |
Outbound call to service returning file contents |
BPEL, Mediator, or Service Bus requests a file to be read, returning nothing if the file doesn't exist. |
|
List Files |
Outbound call to service returning a list of files in a directory |
Provides a means for listing the files in a directory. |
Tip
Why ignore the contents of the file?
The file adapter has an option named Do not read file content. This is used when the file is just a signal for some event. Do not use this feature for the scenario where a file is written and then marked as available by another file being written. This is explicitly handled elsewhere in the file adapter. Instead, the feature can be used as a signal of some event that has no relevant data other than the fact that something has happened. Although the file itself is not readable, certain metadata is made available as part of the message sent.
Defining the file location
Clicking on Next allows us to configure the location of the file. Locations can be specified as either physical (mapped directly onto the filesystem) or logical (an indirection to the real location). The Directory for Incoming Files specifies where the adapter should look to find new files. If the file should appear in a subdirectory of the one specified, then the Process files recursively box should be checked.
The key question now is what to do with the file when it appears. One option is to keep a copy of the file in an archive directory. This is achieved by checking the Archive processed files attribute and providing a location for the file archive. In addition to archiving the file, we need to decide if we want to delete the original file. This is indicated by the Delete files after successful retrieval checkbox.
Tip
Logical versus Physical locations
The file adapter allows us to have logical (Logical Name) or physical locations (Physical Path) for files. Physical locations are easier for developers as we embed the exact file location into the assembly with no more work required. However, this only works if the file locations are the same in the development, test and production environments, particularly unlikely if development is done on Windows but production is on Linux. Hence for production systems, it is best to use logical locations that must be mapped onto physical locations when deployed. Chapter 19, Packaging and Deploying shows how this mapping may be different for each environment.
Selecting specific files
Having defined the location where files are found, we can now move on to the next step in the wizard. Here we describe what the filenames look like. We can describe filenames using either wildcards (using '*' to represent a sequence of 0 or more characters) or using Java regular expressions, as described in the documentation for the java.util.regex.Pattern class. Usually wildcards will be good enough. For example, if we want to select all files that start with "PR" and end with ".txt", then we would use the wildcard string "PR*.txt" or the regular expression "PR.*\.txt". As you can see, it is generally easier to use wildcards rather than regular expressions. We can also specify a pattern to identify which files should not be processed.
The final part of this screen in the adapter wizard asks if the file contains a single message or many messages. This is confusing because when the screen refers to messages, it really means records.
Tip
XML files
It is worth remembering that a well formed XML document can only have a single root element, and hence an XML input file will normally have only a single input record. In the case of very large XML files, it is possible to have the file adapter batch the file up into multiple messages, in which case the root element is replicated in each message, and the second level elements are treated as records. This behavior is requested by setting the streaming option.
By default, a message will contain a single record from the file. Records will be defined in the next step of the wizard. If the file causes a BPEL process to be started, then a 1000 record file would result in 1000 BPEL processes being initiated. To improve efficiency, records can be batched, and the Publish Messages in Batches of attribute controls the maximum number of records in a message.
Tip
Message batching
It is common for an incoming file to contain many records. These records, when processed, can impact system performance and memory requirements. Hence it is important to align the use of the records with their likely impact on system resources.
Detecting that the file is available
The next step in the wizard allows us to configure the frequency of polling for the inbound file. There are two parameters that can be configured here–the Polling Frequency and the Minimum File Age.
The Polling Frequency just means the time delay between checking to see if a file is available for processing. The adapter will check once per interval to see if the file exists. Setting this too low can consume needless CPU resources, setting it too high can make the system appear unresponsive. 'Too high' and 'too low' are very subjective and will depend on your individual requirements. For example, the polling interval for a file that is expected to be written twice a day may be set to three hours, while the interval for a file that is expected to be written every hour may be set to 15 minutes.
Minimum File Age specifies how old a file must be before it is processed by the adapter. This setting allows a file to be completely written before it is read. For example, a large file may take five minutes to write out from the original application. If the file is read three minutes after it has been created, then it is possible for the adapter to run out of records to read and assume the file has been processed, when in reality, the application is still writing to the file. Setting a minimum age to ten minutes would avoid this problem by giving the application at least ten minutes to write the file.
As an alternative to polling for a file directly, we may use a trigger file to indicate that a file is available. Some systems write large files to disk and then indicate that they are available by writing a trigger file. This avoids the problems with reading an incomplete file we identified in the previous paragraph, without the delay in processing the file that a minimum age field may cause.
Message format
The penultimate step in the file adapter is to set up the format of records or messages in the file. This is one of the most critical steps, as this defines the format of messages generated by a file.
Messages may be opaque, meaning that they are passed around as black boxes. This may be appropriate with a Microsoft Word file, for example, that must merely be transported from point A to point B without being examined. This is indicated by the Native format translation is not required (Schema is Opaque) checkbox.
If the document is already in an XML format, then we can just specify a schema and an expected root element and the job is done. Normally the file is in some non-XML format that must be mapped onto an XML Schema generated through the native format builder wizard, which is invoked through the Define Schema for Native Format button.
Defining a native format schema
Invoking the Native Format Builder wizard brings up an initial start screen that leads on to the first step in the wizard, choosing the type of format, as shown in the following screenshot:
This allows us to identify the overall record structure. If we have an existing schema document that describes the record structure, then we can point to that. Usually, we will need to determine the type of structure of the file ourselves. The choices available are:
- Delimited: These are files such as CSV files (Comma Separated Values), records with spaces, or '+' signs for separators.
- Fixed Length: These are files whose records consist of fixed length fields. Be careful not to confuse these with space-separated files, as if a value does not fill the entire field, it will usually be padded with spaces.
- Complex Type: These files may include nested records like a master detail type structure.
- DTD to be converted to XSD: These are XML Data Type Definition XML files that will be mapped onto an XML Schema description of the file content.
- Cobol Copybook to be converted to native format: These are files that have usually been produced by a COBOL system, often originating from a mainframe.
We will look at a delimited file, as it is one of the most common formats.
Although we are using the separator file type, the steps involved are basically the same for most file types including the fixed length field format, which is also extremely common.
Using a sample file
To make it easier to describe the format of the incoming file, the wizard asks us to specify a file to use as a sample. If necessary, we can skip rows in the file and determine the number of records to read. Obviously, reading a very large number of records may take a while, and if all the variability on the file is in the first ten records, then there is no point in wasting time reading any more sample records. We may also choose to restrict the number of rows processed at runtime.
Setting the character set needs to be done carefully, particularly in international environments where non-ASCII character sets may be common.
After selecting a sample file, the wizard will display an initial view of the file with a guess at the field separators.
Record structure
The next step of the wizard allows us to describe how the records appear in the file.
The first option File contains only one record allows us to process the file as a single message. This can be useful when the file has multiple records, all of the same format, which we want to read as a single message. Use of this option disables batching.
The next option of File contains multiple record instances allows batching to take place. Records are either of the same type or of different types. They can only be marked of different types if they can be distinguished, based on the first field in the record. In other words, in order to choose the Multiple records are of different types, the first field in all the records must be a record type identifier. In the example shown in the preceding screenshot, the first field is either an H for Header records or an R for Records.
Choosing a root element
The next step allows us to define the target namespace and root element of the schema that we are generating.
Note
Don't forget that when using the Native Format Builder wizard, we are just creating an XML Schema document that describes the native (non-XML) format data. Most of the time this schema is transparent to us. However, at times the XML constructs have to emerge, for example, when identifying a name for a root element. The file is described using an XML Schema extension known as NXSD.
As we can see the root element is mandatory. This root element acts as a wrapper for the records in a message. If message batching is set to 1, then each wrapper will have a single sub-element, namely, the record. If the message is set to greater than 1, then each wrapper will have at least one and possibly more sub-elements, each sub-element being a record. There can never be more sub-elements than the batch size.
Message delimiters
Having described the overall structure of the file, we can now drill down into the individual fields. To do this, we first specify the message delimiters.
In addition to field delimiters, we can also specify a record delimiter. Usually record delimiters are new lines. If fields are also wrapped in quotation marks, then these can be stripped off by specifying the Optionally enclosed by character.
Record type names
The wizard will identify the types of records based on the first field in each record, as shown in the preceding screenshot. It is possible to ignore record types by selecting them and clicking Delete. If this is done by mistake, then it is possible to add them back by using the Add button. Only fields that exist in the sample data can be added in the wizard.
Note that if we want to reset the record types screen, then the Scan button will rescan the sample file and look for all the different record types it contains.
The Record Name field can be set by double-clicking it and providing a suitable record name. This record name is the XML element name that encapsulates the record content.
Field properties
Now that we have identified record and field boundaries, we can drill down into the records and define the data types and names of individual fields. This is done for each record type in turn. We can select which records to define by selecting them from the Record Name drop-down box or by pressing the Next Record Type button.
It is important to be as liberal as possible when defining field data types because any mismatches will cause errors that will need to be handled. Being liberal in our record definitions will allow us to validate the messages, as described in Chapter 13, Building Validation into Services, without raising system errors.
The Name column represents the element name of this field. The wizard will attempt to guess the type of the field, but it is important to always check this because the sample data you are using may not include all possibilities. A common error is identifying numbers to be tagged as integers, when they should really be strings—accept integer types only when they are likely to have arithmetic operations performed on them.
Verifying the result
We have now completed our mapping and can verify what has been done by looking at the generated XML Schema file. Note that the generated schema uses some Oracle extensions to enable a non-XML formatted file to be represented as XML. In particular the nxsd namespace prefix is used to identify field separators and record terminators.
Note
The XML Schema generated can be edited manually. This is useful to support nested records (records inside other records) like those that may be found in a file containing order records with nested detail records (an order record contains multiple line item detail records). In this case, it is useful to use the wizard to generate a schema with order records and detail records at the same level. The schema can then be modified by hand to make the detail records children of the order records.
Clicking the Test button brings up a simple test screen that allows us to apply our newly generated schema to the input document and examine the resulting XML.
Clicking Next and then Finish will cause the generated schema file to be saved.
Finishing the wizards
Until now, no work has been saved, except for the XML Schema mapping the file content onto an XML structure. The rest of the adapter settings are not saved, and the endpoint is not set up until the Finish button is clicked on the completion screen, as shown in the following screenshot. Note that the file generated is a Web Service Description Language (WSDL) file with a JCA binding.
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Creating a dummy message type
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>Adding an output message to the read operation
In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
Using the modified interface
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
Selecting the FTP connection
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
Choosing the operation
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Selecting the file destination
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
Note
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Tip
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Naming the service
Clicking on Next allows us to choose a name for the service that we are creating and optionally a description. We will use the service name PayrollinputFileService. Any name can be used, as long as it has some meaning to the developers. It is a good idea to have a consistent naming convention, for example, identifying the business role (PayrollInput), the technology (File), and the fact that this is a service (PayrollinputFileService).
Identifying the operation
Clicking on Next allows us to either import an existing WSDL definition for our service or create a new service definition. We would import an existing WSDL to reuse an existing adapter configuration that had been created previously. Choosing Define from operation and schema (specified later) allows us to create a new definition.
If we choose to create a new definition, then we start by specifying how we map the files onto a service. It is here that we decide whether we are reading or writing the file. When reading a file, we decide if we wish to generate an event when it is available (a normal Read File operation that requires an inbound operation to receive the message) or if we want to read it only when requested (a Synchronous Read File operation that requires an outbound operation).
Tip
Who calls who?
We usually think of a service as something that we call and then get a result from. However, in reality, services in a service-oriented architecture will often initiate events. These events may be delivered to a BPEL process which is waiting for an event, or routed to another service through the Service Bus, Mediator, or even initiate a whole new SCA Assembly. Under the covers, an adapter might need to poll to detect an event, but the service will always be able to generate an event. With a service, we either call it to get a result or it generates an event that calls some other service or process.
The file adapter wizard exposes four types of operation, as outlined in the following table. We will explore the read operation to generate events as a file is created.
|
Operation Type |
Direction |
Description |
|---|---|---|
|
Read File |
Inbound call from service |
Reads the file and generates one or more calls into BPEL, Mediator, or Service Bus when a file appears. |
|
Write File |
Outbound call to service with no response |
Writes a file, with one or more calls from BPEL, Mediator, or the Service Bus, causing records to be written to a file. |
|
Synchronous Read File |
Outbound call to service returning file contents |
BPEL, Mediator, or Service Bus requests a file to be read, returning nothing if the file doesn't exist. |
|
List Files |
Outbound call to service returning a list of files in a directory |
Provides a means for listing the files in a directory. |
Tip
Why ignore the contents of the file?
The file adapter has an option named Do not read file content. This is used when the file is just a signal for some event. Do not use this feature for the scenario where a file is written and then marked as available by another file being written. This is explicitly handled elsewhere in the file adapter. Instead, the feature can be used as a signal of some event that has no relevant data other than the fact that something has happened. Although the file itself is not readable, certain metadata is made available as part of the message sent.
Defining the file location
Clicking on Next allows us to configure the location of the file. Locations can be specified as either physical (mapped directly onto the filesystem) or logical (an indirection to the real location). The Directory for Incoming Files specifies where the adapter should look to find new files. If the file should appear in a subdirectory of the one specified, then the Process files recursively box should be checked.
The key question now is what to do with the file when it appears. One option is to keep a copy of the file in an archive directory. This is achieved by checking the Archive processed files attribute and providing a location for the file archive. In addition to archiving the file, we need to decide if we want to delete the original file. This is indicated by the Delete files after successful retrieval checkbox.
Tip
Logical versus Physical locations
The file adapter allows us to have logical (Logical Name) or physical locations (Physical Path) for files. Physical locations are easier for developers as we embed the exact file location into the assembly with no more work required. However, this only works if the file locations are the same in the development, test and production environments, particularly unlikely if development is done on Windows but production is on Linux. Hence for production systems, it is best to use logical locations that must be mapped onto physical locations when deployed. Chapter 19, Packaging and Deploying shows how this mapping may be different for each environment.
Selecting specific files
Having defined the location where files are found, we can now move on to the next step in the wizard. Here we describe what the filenames look like. We can describe filenames using either wildcards (using '*' to represent a sequence of 0 or more characters) or using Java regular expressions, as described in the documentation for the java.util.regex.Pattern class. Usually wildcards will be good enough. For example, if we want to select all files that start with "PR" and end with ".txt", then we would use the wildcard string "PR*.txt" or the regular expression "PR.*\.txt". As you can see, it is generally easier to use wildcards rather than regular expressions. We can also specify a pattern to identify which files should not be processed.
The final part of this screen in the adapter wizard asks if the file contains a single message or many messages. This is confusing because when the screen refers to messages, it really means records.
Tip
XML files
It is worth remembering that a well formed XML document can only have a single root element, and hence an XML input file will normally have only a single input record. In the case of very large XML files, it is possible to have the file adapter batch the file up into multiple messages, in which case the root element is replicated in each message, and the second level elements are treated as records. This behavior is requested by setting the streaming option.
By default, a message will contain a single record from the file. Records will be defined in the next step of the wizard. If the file causes a BPEL process to be started, then a 1000 record file would result in 1000 BPEL processes being initiated. To improve efficiency, records can be batched, and the Publish Messages in Batches of attribute controls the maximum number of records in a message.
Tip
Message batching
It is common for an incoming file to contain many records. These records, when processed, can impact system performance and memory requirements. Hence it is important to align the use of the records with their likely impact on system resources.
Detecting that the file is available
The next step in the wizard allows us to configure the frequency of polling for the inbound file. There are two parameters that can be configured here–the Polling Frequency and the Minimum File Age.
The Polling Frequency just means the time delay between checking to see if a file is available for processing. The adapter will check once per interval to see if the file exists. Setting this too low can consume needless CPU resources, setting it too high can make the system appear unresponsive. 'Too high' and 'too low' are very subjective and will depend on your individual requirements. For example, the polling interval for a file that is expected to be written twice a day may be set to three hours, while the interval for a file that is expected to be written every hour may be set to 15 minutes.
Minimum File Age specifies how old a file must be before it is processed by the adapter. This setting allows a file to be completely written before it is read. For example, a large file may take five minutes to write out from the original application. If the file is read three minutes after it has been created, then it is possible for the adapter to run out of records to read and assume the file has been processed, when in reality, the application is still writing to the file. Setting a minimum age to ten minutes would avoid this problem by giving the application at least ten minutes to write the file.
As an alternative to polling for a file directly, we may use a trigger file to indicate that a file is available. Some systems write large files to disk and then indicate that they are available by writing a trigger file. This avoids the problems with reading an incomplete file we identified in the previous paragraph, without the delay in processing the file that a minimum age field may cause.
Message format
The penultimate step in the file adapter is to set up the format of records or messages in the file. This is one of the most critical steps, as this defines the format of messages generated by a file.
Messages may be opaque, meaning that they are passed around as black boxes. This may be appropriate with a Microsoft Word file, for example, that must merely be transported from point A to point B without being examined. This is indicated by the Native format translation is not required (Schema is Opaque) checkbox.
If the document is already in an XML format, then we can just specify a schema and an expected root element and the job is done. Normally the file is in some non-XML format that must be mapped onto an XML Schema generated through the native format builder wizard, which is invoked through the Define Schema for Native Format button.
Defining a native format schema
Invoking the Native Format Builder wizard brings up an initial start screen that leads on to the first step in the wizard, choosing the type of format, as shown in the following screenshot:
This allows us to identify the overall record structure. If we have an existing schema document that describes the record structure, then we can point to that. Usually, we will need to determine the type of structure of the file ourselves. The choices available are:
- Delimited: These are files such as CSV files (Comma Separated Values), records with spaces, or '+' signs for separators.
- Fixed Length: These are files whose records consist of fixed length fields. Be careful not to confuse these with space-separated files, as if a value does not fill the entire field, it will usually be padded with spaces.
- Complex Type: These files may include nested records like a master detail type structure.
- DTD to be converted to XSD: These are XML Data Type Definition XML files that will be mapped onto an XML Schema description of the file content.
- Cobol Copybook to be converted to native format: These are files that have usually been produced by a COBOL system, often originating from a mainframe.
We will look at a delimited file, as it is one of the most common formats.
Although we are using the separator file type, the steps involved are basically the same for most file types including the fixed length field format, which is also extremely common.
Using a sample file
To make it easier to describe the format of the incoming file, the wizard asks us to specify a file to use as a sample. If necessary, we can skip rows in the file and determine the number of records to read. Obviously, reading a very large number of records may take a while, and if all the variability on the file is in the first ten records, then there is no point in wasting time reading any more sample records. We may also choose to restrict the number of rows processed at runtime.
Setting the character set needs to be done carefully, particularly in international environments where non-ASCII character sets may be common.
After selecting a sample file, the wizard will display an initial view of the file with a guess at the field separators.
Record structure
The next step of the wizard allows us to describe how the records appear in the file.
The first option File contains only one record allows us to process the file as a single message. This can be useful when the file has multiple records, all of the same format, which we want to read as a single message. Use of this option disables batching.
The next option of File contains multiple record instances allows batching to take place. Records are either of the same type or of different types. They can only be marked of different types if they can be distinguished, based on the first field in the record. In other words, in order to choose the Multiple records are of different types, the first field in all the records must be a record type identifier. In the example shown in the preceding screenshot, the first field is either an H for Header records or an R for Records.
Choosing a root element
The next step allows us to define the target namespace and root element of the schema that we are generating.
Note
Don't forget that when using the Native Format Builder wizard, we are just creating an XML Schema document that describes the native (non-XML) format data. Most of the time this schema is transparent to us. However, at times the XML constructs have to emerge, for example, when identifying a name for a root element. The file is described using an XML Schema extension known as NXSD.
As we can see the root element is mandatory. This root element acts as a wrapper for the records in a message. If message batching is set to 1, then each wrapper will have a single sub-element, namely, the record. If the message is set to greater than 1, then each wrapper will have at least one and possibly more sub-elements, each sub-element being a record. There can never be more sub-elements than the batch size.
Message delimiters
Having described the overall structure of the file, we can now drill down into the individual fields. To do this, we first specify the message delimiters.
In addition to field delimiters, we can also specify a record delimiter. Usually record delimiters are new lines. If fields are also wrapped in quotation marks, then these can be stripped off by specifying the Optionally enclosed by character.
Record type names
The wizard will identify the types of records based on the first field in each record, as shown in the preceding screenshot. It is possible to ignore record types by selecting them and clicking Delete. If this is done by mistake, then it is possible to add them back by using the Add button. Only fields that exist in the sample data can be added in the wizard.
Note that if we want to reset the record types screen, then the Scan button will rescan the sample file and look for all the different record types it contains.
The Record Name field can be set by double-clicking it and providing a suitable record name. This record name is the XML element name that encapsulates the record content.
Field properties
Now that we have identified record and field boundaries, we can drill down into the records and define the data types and names of individual fields. This is done for each record type in turn. We can select which records to define by selecting them from the Record Name drop-down box or by pressing the Next Record Type button.
It is important to be as liberal as possible when defining field data types because any mismatches will cause errors that will need to be handled. Being liberal in our record definitions will allow us to validate the messages, as described in Chapter 13, Building Validation into Services, without raising system errors.
The Name column represents the element name of this field. The wizard will attempt to guess the type of the field, but it is important to always check this because the sample data you are using may not include all possibilities. A common error is identifying numbers to be tagged as integers, when they should really be strings—accept integer types only when they are likely to have arithmetic operations performed on them.
Verifying the result
We have now completed our mapping and can verify what has been done by looking at the generated XML Schema file. Note that the generated schema uses some Oracle extensions to enable a non-XML formatted file to be represented as XML. In particular the nxsd namespace prefix is used to identify field separators and record terminators.
Note
The XML Schema generated can be edited manually. This is useful to support nested records (records inside other records) like those that may be found in a file containing order records with nested detail records (an order record contains multiple line item detail records). In this case, it is useful to use the wizard to generate a schema with order records and detail records at the same level. The schema can then be modified by hand to make the detail records children of the order records.
Clicking the Test button brings up a simple test screen that allows us to apply our newly generated schema to the input document and examine the resulting XML.
Clicking Next and then Finish will cause the generated schema file to be saved.
Finishing the wizards
Until now, no work has been saved, except for the XML Schema mapping the file content onto an XML structure. The rest of the adapter settings are not saved, and the endpoint is not set up until the Finish button is clicked on the completion screen, as shown in the following screenshot. Note that the file generated is a Web Service Description Language (WSDL) file with a JCA binding.
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Creating a dummy message type
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>Adding an output message to the read operation
In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
Using the modified interface
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
Selecting the FTP connection
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
Choosing the operation
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Selecting the file destination
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
Note
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Tip
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Identifying the operation
Clicking on Next allows us to either import an existing WSDL definition for our service or create a new service definition. We would import an existing WSDL to reuse an existing adapter configuration that had been created previously. Choosing Define from operation and schema (specified later) allows us to create a new definition.
If we choose to create a new definition, then we start by specifying how we map the files onto a service. It is here that we decide whether we are reading or writing the file. When reading a file, we decide if we wish to generate an event when it is available (a normal Read File operation that requires an inbound operation to receive the message) or if we want to read it only when requested (a Synchronous Read File operation that requires an outbound operation).
Tip
Who calls who?
We usually think of a service as something that we call and then get a result from. However, in reality, services in a service-oriented architecture will often initiate events. These events may be delivered to a BPEL process which is waiting for an event, or routed to another service through the Service Bus, Mediator, or even initiate a whole new SCA Assembly. Under the covers, an adapter might need to poll to detect an event, but the service will always be able to generate an event. With a service, we either call it to get a result or it generates an event that calls some other service or process.
The file adapter wizard exposes four types of operation, as outlined in the following table. We will explore the read operation to generate events as a file is created.
|
Operation Type |
Direction |
Description |
|---|---|---|
|
Read File |
Inbound call from service |
Reads the file and generates one or more calls into BPEL, Mediator, or Service Bus when a file appears. |
|
Write File |
Outbound call to service with no response |
Writes a file, with one or more calls from BPEL, Mediator, or the Service Bus, causing records to be written to a file. |
|
Synchronous Read File |
Outbound call to service returning file contents |
BPEL, Mediator, or Service Bus requests a file to be read, returning nothing if the file doesn't exist. |
|
List Files |
Outbound call to service returning a list of files in a directory |
Provides a means for listing the files in a directory. |
Tip
Why ignore the contents of the file?
The file adapter has an option named Do not read file content. This is used when the file is just a signal for some event. Do not use this feature for the scenario where a file is written and then marked as available by another file being written. This is explicitly handled elsewhere in the file adapter. Instead, the feature can be used as a signal of some event that has no relevant data other than the fact that something has happened. Although the file itself is not readable, certain metadata is made available as part of the message sent.
Defining the file location
Clicking on Next allows us to configure the location of the file. Locations can be specified as either physical (mapped directly onto the filesystem) or logical (an indirection to the real location). The Directory for Incoming Files specifies where the adapter should look to find new files. If the file should appear in a subdirectory of the one specified, then the Process files recursively box should be checked.
The key question now is what to do with the file when it appears. One option is to keep a copy of the file in an archive directory. This is achieved by checking the Archive processed files attribute and providing a location for the file archive. In addition to archiving the file, we need to decide if we want to delete the original file. This is indicated by the Delete files after successful retrieval checkbox.
Tip
Logical versus Physical locations
The file adapter allows us to have logical (Logical Name) or physical locations (Physical Path) for files. Physical locations are easier for developers as we embed the exact file location into the assembly with no more work required. However, this only works if the file locations are the same in the development, test and production environments, particularly unlikely if development is done on Windows but production is on Linux. Hence for production systems, it is best to use logical locations that must be mapped onto physical locations when deployed. Chapter 19, Packaging and Deploying shows how this mapping may be different for each environment.
Selecting specific files
Having defined the location where files are found, we can now move on to the next step in the wizard. Here we describe what the filenames look like. We can describe filenames using either wildcards (using '*' to represent a sequence of 0 or more characters) or using Java regular expressions, as described in the documentation for the java.util.regex.Pattern class. Usually wildcards will be good enough. For example, if we want to select all files that start with "PR" and end with ".txt", then we would use the wildcard string "PR*.txt" or the regular expression "PR.*\.txt". As you can see, it is generally easier to use wildcards rather than regular expressions. We can also specify a pattern to identify which files should not be processed.
The final part of this screen in the adapter wizard asks if the file contains a single message or many messages. This is confusing because when the screen refers to messages, it really means records.
Tip
XML files
It is worth remembering that a well formed XML document can only have a single root element, and hence an XML input file will normally have only a single input record. In the case of very large XML files, it is possible to have the file adapter batch the file up into multiple messages, in which case the root element is replicated in each message, and the second level elements are treated as records. This behavior is requested by setting the streaming option.
By default, a message will contain a single record from the file. Records will be defined in the next step of the wizard. If the file causes a BPEL process to be started, then a 1000 record file would result in 1000 BPEL processes being initiated. To improve efficiency, records can be batched, and the Publish Messages in Batches of attribute controls the maximum number of records in a message.
Tip
Message batching
It is common for an incoming file to contain many records. These records, when processed, can impact system performance and memory requirements. Hence it is important to align the use of the records with their likely impact on system resources.
Detecting that the file is available
The next step in the wizard allows us to configure the frequency of polling for the inbound file. There are two parameters that can be configured here–the Polling Frequency and the Minimum File Age.
The Polling Frequency just means the time delay between checking to see if a file is available for processing. The adapter will check once per interval to see if the file exists. Setting this too low can consume needless CPU resources, setting it too high can make the system appear unresponsive. 'Too high' and 'too low' are very subjective and will depend on your individual requirements. For example, the polling interval for a file that is expected to be written twice a day may be set to three hours, while the interval for a file that is expected to be written every hour may be set to 15 minutes.
Minimum File Age specifies how old a file must be before it is processed by the adapter. This setting allows a file to be completely written before it is read. For example, a large file may take five minutes to write out from the original application. If the file is read three minutes after it has been created, then it is possible for the adapter to run out of records to read and assume the file has been processed, when in reality, the application is still writing to the file. Setting a minimum age to ten minutes would avoid this problem by giving the application at least ten minutes to write the file.
As an alternative to polling for a file directly, we may use a trigger file to indicate that a file is available. Some systems write large files to disk and then indicate that they are available by writing a trigger file. This avoids the problems with reading an incomplete file we identified in the previous paragraph, without the delay in processing the file that a minimum age field may cause.
Message format
The penultimate step in the file adapter is to set up the format of records or messages in the file. This is one of the most critical steps, as this defines the format of messages generated by a file.
Messages may be opaque, meaning that they are passed around as black boxes. This may be appropriate with a Microsoft Word file, for example, that must merely be transported from point A to point B without being examined. This is indicated by the Native format translation is not required (Schema is Opaque) checkbox.
If the document is already in an XML format, then we can just specify a schema and an expected root element and the job is done. Normally the file is in some non-XML format that must be mapped onto an XML Schema generated through the native format builder wizard, which is invoked through the Define Schema for Native Format button.
Defining a native format schema
Invoking the Native Format Builder wizard brings up an initial start screen that leads on to the first step in the wizard, choosing the type of format, as shown in the following screenshot:
This allows us to identify the overall record structure. If we have an existing schema document that describes the record structure, then we can point to that. Usually, we will need to determine the type of structure of the file ourselves. The choices available are:
- Delimited: These are files such as CSV files (Comma Separated Values), records with spaces, or '+' signs for separators.
- Fixed Length: These are files whose records consist of fixed length fields. Be careful not to confuse these with space-separated files, as if a value does not fill the entire field, it will usually be padded with spaces.
- Complex Type: These files may include nested records like a master detail type structure.
- DTD to be converted to XSD: These are XML Data Type Definition XML files that will be mapped onto an XML Schema description of the file content.
- Cobol Copybook to be converted to native format: These are files that have usually been produced by a COBOL system, often originating from a mainframe.
We will look at a delimited file, as it is one of the most common formats.
Although we are using the separator file type, the steps involved are basically the same for most file types including the fixed length field format, which is also extremely common.
Using a sample file
To make it easier to describe the format of the incoming file, the wizard asks us to specify a file to use as a sample. If necessary, we can skip rows in the file and determine the number of records to read. Obviously, reading a very large number of records may take a while, and if all the variability on the file is in the first ten records, then there is no point in wasting time reading any more sample records. We may also choose to restrict the number of rows processed at runtime.
Setting the character set needs to be done carefully, particularly in international environments where non-ASCII character sets may be common.
After selecting a sample file, the wizard will display an initial view of the file with a guess at the field separators.
Record structure
The next step of the wizard allows us to describe how the records appear in the file.
The first option File contains only one record allows us to process the file as a single message. This can be useful when the file has multiple records, all of the same format, which we want to read as a single message. Use of this option disables batching.
The next option of File contains multiple record instances allows batching to take place. Records are either of the same type or of different types. They can only be marked of different types if they can be distinguished, based on the first field in the record. In other words, in order to choose the Multiple records are of different types, the first field in all the records must be a record type identifier. In the example shown in the preceding screenshot, the first field is either an H for Header records or an R for Records.
Choosing a root element
The next step allows us to define the target namespace and root element of the schema that we are generating.
Note
Don't forget that when using the Native Format Builder wizard, we are just creating an XML Schema document that describes the native (non-XML) format data. Most of the time this schema is transparent to us. However, at times the XML constructs have to emerge, for example, when identifying a name for a root element. The file is described using an XML Schema extension known as NXSD.
As we can see the root element is mandatory. This root element acts as a wrapper for the records in a message. If message batching is set to 1, then each wrapper will have a single sub-element, namely, the record. If the message is set to greater than 1, then each wrapper will have at least one and possibly more sub-elements, each sub-element being a record. There can never be more sub-elements than the batch size.
Message delimiters
Having described the overall structure of the file, we can now drill down into the individual fields. To do this, we first specify the message delimiters.
In addition to field delimiters, we can also specify a record delimiter. Usually record delimiters are new lines. If fields are also wrapped in quotation marks, then these can be stripped off by specifying the Optionally enclosed by character.
Record type names
The wizard will identify the types of records based on the first field in each record, as shown in the preceding screenshot. It is possible to ignore record types by selecting them and clicking Delete. If this is done by mistake, then it is possible to add them back by using the Add button. Only fields that exist in the sample data can be added in the wizard.
Note that if we want to reset the record types screen, then the Scan button will rescan the sample file and look for all the different record types it contains.
The Record Name field can be set by double-clicking it and providing a suitable record name. This record name is the XML element name that encapsulates the record content.
Field properties
Now that we have identified record and field boundaries, we can drill down into the records and define the data types and names of individual fields. This is done for each record type in turn. We can select which records to define by selecting them from the Record Name drop-down box or by pressing the Next Record Type button.
It is important to be as liberal as possible when defining field data types because any mismatches will cause errors that will need to be handled. Being liberal in our record definitions will allow us to validate the messages, as described in Chapter 13, Building Validation into Services, without raising system errors.
The Name column represents the element name of this field. The wizard will attempt to guess the type of the field, but it is important to always check this because the sample data you are using may not include all possibilities. A common error is identifying numbers to be tagged as integers, when they should really be strings—accept integer types only when they are likely to have arithmetic operations performed on them.
Verifying the result
We have now completed our mapping and can verify what has been done by looking at the generated XML Schema file. Note that the generated schema uses some Oracle extensions to enable a non-XML formatted file to be represented as XML. In particular the nxsd namespace prefix is used to identify field separators and record terminators.
Note
The XML Schema generated can be edited manually. This is useful to support nested records (records inside other records) like those that may be found in a file containing order records with nested detail records (an order record contains multiple line item detail records). In this case, it is useful to use the wizard to generate a schema with order records and detail records at the same level. The schema can then be modified by hand to make the detail records children of the order records.
Clicking the Test button brings up a simple test screen that allows us to apply our newly generated schema to the input document and examine the resulting XML.
Clicking Next and then Finish will cause the generated schema file to be saved.
Finishing the wizards
Until now, no work has been saved, except for the XML Schema mapping the file content onto an XML structure. The rest of the adapter settings are not saved, and the endpoint is not set up until the Finish button is clicked on the completion screen, as shown in the following screenshot. Note that the file generated is a Web Service Description Language (WSDL) file with a JCA binding.
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Creating a dummy message type
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>Adding an output message to the read operation
In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
Using the modified interface
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
Selecting the FTP connection
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
Choosing the operation
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Selecting the file destination
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
Note
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Tip
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Defining the file location
Clicking on Next allows us to configure the location of the file. Locations can be specified as either physical (mapped directly onto the filesystem) or logical (an indirection to the real location). The Directory for Incoming Files specifies where the adapter should look to find new files. If the file should appear in a subdirectory of the one specified, then the Process files recursively box should be checked.
The key question now is what to do with the file when it appears. One option is to keep a copy of the file in an archive directory. This is achieved by checking the Archive processed files attribute and providing a location for the file archive. In addition to archiving the file, we need to decide if we want to delete the original file. This is indicated by the Delete files after successful retrieval checkbox.
Tip
Logical versus Physical locations
The file adapter allows us to have logical (Logical Name) or physical locations (Physical Path) for files. Physical locations are easier for developers as we embed the exact file location into the assembly with no more work required. However, this only works if the file locations are the same in the development, test and production environments, particularly unlikely if development is done on Windows but production is on Linux. Hence for production systems, it is best to use logical locations that must be mapped onto physical locations when deployed. Chapter 19, Packaging and Deploying shows how this mapping may be different for each environment.
Selecting specific files
Having defined the location where files are found, we can now move on to the next step in the wizard. Here we describe what the filenames look like. We can describe filenames using either wildcards (using '*' to represent a sequence of 0 or more characters) or using Java regular expressions, as described in the documentation for the java.util.regex.Pattern class. Usually wildcards will be good enough. For example, if we want to select all files that start with "PR" and end with ".txt", then we would use the wildcard string "PR*.txt" or the regular expression "PR.*\.txt". As you can see, it is generally easier to use wildcards rather than regular expressions. We can also specify a pattern to identify which files should not be processed.
The final part of this screen in the adapter wizard asks if the file contains a single message or many messages. This is confusing because when the screen refers to messages, it really means records.
Tip
XML files
It is worth remembering that a well formed XML document can only have a single root element, and hence an XML input file will normally have only a single input record. In the case of very large XML files, it is possible to have the file adapter batch the file up into multiple messages, in which case the root element is replicated in each message, and the second level elements are treated as records. This behavior is requested by setting the streaming option.
By default, a message will contain a single record from the file. Records will be defined in the next step of the wizard. If the file causes a BPEL process to be started, then a 1000 record file would result in 1000 BPEL processes being initiated. To improve efficiency, records can be batched, and the Publish Messages in Batches of attribute controls the maximum number of records in a message.
Tip
Message batching
It is common for an incoming file to contain many records. These records, when processed, can impact system performance and memory requirements. Hence it is important to align the use of the records with their likely impact on system resources.
Detecting that the file is available
The next step in the wizard allows us to configure the frequency of polling for the inbound file. There are two parameters that can be configured here–the Polling Frequency and the Minimum File Age.
The Polling Frequency just means the time delay between checking to see if a file is available for processing. The adapter will check once per interval to see if the file exists. Setting this too low can consume needless CPU resources, setting it too high can make the system appear unresponsive. 'Too high' and 'too low' are very subjective and will depend on your individual requirements. For example, the polling interval for a file that is expected to be written twice a day may be set to three hours, while the interval for a file that is expected to be written every hour may be set to 15 minutes.
Minimum File Age specifies how old a file must be before it is processed by the adapter. This setting allows a file to be completely written before it is read. For example, a large file may take five minutes to write out from the original application. If the file is read three minutes after it has been created, then it is possible for the adapter to run out of records to read and assume the file has been processed, when in reality, the application is still writing to the file. Setting a minimum age to ten minutes would avoid this problem by giving the application at least ten minutes to write the file.
As an alternative to polling for a file directly, we may use a trigger file to indicate that a file is available. Some systems write large files to disk and then indicate that they are available by writing a trigger file. This avoids the problems with reading an incomplete file we identified in the previous paragraph, without the delay in processing the file that a minimum age field may cause.
Message format
The penultimate step in the file adapter is to set up the format of records or messages in the file. This is one of the most critical steps, as this defines the format of messages generated by a file.
Messages may be opaque, meaning that they are passed around as black boxes. This may be appropriate with a Microsoft Word file, for example, that must merely be transported from point A to point B without being examined. This is indicated by the Native format translation is not required (Schema is Opaque) checkbox.
If the document is already in an XML format, then we can just specify a schema and an expected root element and the job is done. Normally the file is in some non-XML format that must be mapped onto an XML Schema generated through the native format builder wizard, which is invoked through the Define Schema for Native Format button.
Defining a native format schema
Invoking the Native Format Builder wizard brings up an initial start screen that leads on to the first step in the wizard, choosing the type of format, as shown in the following screenshot:
This allows us to identify the overall record structure. If we have an existing schema document that describes the record structure, then we can point to that. Usually, we will need to determine the type of structure of the file ourselves. The choices available are:
- Delimited: These are files such as CSV files (Comma Separated Values), records with spaces, or '+' signs for separators.
- Fixed Length: These are files whose records consist of fixed length fields. Be careful not to confuse these with space-separated files, as if a value does not fill the entire field, it will usually be padded with spaces.
- Complex Type: These files may include nested records like a master detail type structure.
- DTD to be converted to XSD: These are XML Data Type Definition XML files that will be mapped onto an XML Schema description of the file content.
- Cobol Copybook to be converted to native format: These are files that have usually been produced by a COBOL system, often originating from a mainframe.
We will look at a delimited file, as it is one of the most common formats.
Although we are using the separator file type, the steps involved are basically the same for most file types including the fixed length field format, which is also extremely common.
Using a sample file
To make it easier to describe the format of the incoming file, the wizard asks us to specify a file to use as a sample. If necessary, we can skip rows in the file and determine the number of records to read. Obviously, reading a very large number of records may take a while, and if all the variability on the file is in the first ten records, then there is no point in wasting time reading any more sample records. We may also choose to restrict the number of rows processed at runtime.
Setting the character set needs to be done carefully, particularly in international environments where non-ASCII character sets may be common.
After selecting a sample file, the wizard will display an initial view of the file with a guess at the field separators.
Record structure
The next step of the wizard allows us to describe how the records appear in the file.
The first option File contains only one record allows us to process the file as a single message. This can be useful when the file has multiple records, all of the same format, which we want to read as a single message. Use of this option disables batching.
The next option of File contains multiple record instances allows batching to take place. Records are either of the same type or of different types. They can only be marked of different types if they can be distinguished, based on the first field in the record. In other words, in order to choose the Multiple records are of different types, the first field in all the records must be a record type identifier. In the example shown in the preceding screenshot, the first field is either an H for Header records or an R for Records.
Choosing a root element
The next step allows us to define the target namespace and root element of the schema that we are generating.
Note
Don't forget that when using the Native Format Builder wizard, we are just creating an XML Schema document that describes the native (non-XML) format data. Most of the time this schema is transparent to us. However, at times the XML constructs have to emerge, for example, when identifying a name for a root element. The file is described using an XML Schema extension known as NXSD.
As we can see the root element is mandatory. This root element acts as a wrapper for the records in a message. If message batching is set to 1, then each wrapper will have a single sub-element, namely, the record. If the message is set to greater than 1, then each wrapper will have at least one and possibly more sub-elements, each sub-element being a record. There can never be more sub-elements than the batch size.
Message delimiters
Having described the overall structure of the file, we can now drill down into the individual fields. To do this, we first specify the message delimiters.
In addition to field delimiters, we can also specify a record delimiter. Usually record delimiters are new lines. If fields are also wrapped in quotation marks, then these can be stripped off by specifying the Optionally enclosed by character.
Record type names
The wizard will identify the types of records based on the first field in each record, as shown in the preceding screenshot. It is possible to ignore record types by selecting them and clicking Delete. If this is done by mistake, then it is possible to add them back by using the Add button. Only fields that exist in the sample data can be added in the wizard.
Note that if we want to reset the record types screen, then the Scan button will rescan the sample file and look for all the different record types it contains.
The Record Name field can be set by double-clicking it and providing a suitable record name. This record name is the XML element name that encapsulates the record content.
Field properties
Now that we have identified record and field boundaries, we can drill down into the records and define the data types and names of individual fields. This is done for each record type in turn. We can select which records to define by selecting them from the Record Name drop-down box or by pressing the Next Record Type button.
It is important to be as liberal as possible when defining field data types because any mismatches will cause errors that will need to be handled. Being liberal in our record definitions will allow us to validate the messages, as described in Chapter 13, Building Validation into Services, without raising system errors.
The Name column represents the element name of this field. The wizard will attempt to guess the type of the field, but it is important to always check this because the sample data you are using may not include all possibilities. A common error is identifying numbers to be tagged as integers, when they should really be strings—accept integer types only when they are likely to have arithmetic operations performed on them.
Verifying the result
We have now completed our mapping and can verify what has been done by looking at the generated XML Schema file. Note that the generated schema uses some Oracle extensions to enable a non-XML formatted file to be represented as XML. In particular the nxsd namespace prefix is used to identify field separators and record terminators.
Note
The XML Schema generated can be edited manually. This is useful to support nested records (records inside other records) like those that may be found in a file containing order records with nested detail records (an order record contains multiple line item detail records). In this case, it is useful to use the wizard to generate a schema with order records and detail records at the same level. The schema can then be modified by hand to make the detail records children of the order records.
Clicking the Test button brings up a simple test screen that allows us to apply our newly generated schema to the input document and examine the resulting XML.
Clicking Next and then Finish will cause the generated schema file to be saved.
Finishing the wizards
Until now, no work has been saved, except for the XML Schema mapping the file content onto an XML structure. The rest of the adapter settings are not saved, and the endpoint is not set up until the Finish button is clicked on the completion screen, as shown in the following screenshot. Note that the file generated is a Web Service Description Language (WSDL) file with a JCA binding.
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Creating a dummy message type
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>Adding an output message to the read operation
In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
Using the modified interface
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
Selecting the FTP connection
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
Choosing the operation
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Selecting the file destination
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
Note
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Tip
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Selecting specific files
Having defined the location where files are found, we can now move on to the next step in the wizard. Here we describe what the filenames look like. We can describe filenames using either wildcards (using '*' to represent a sequence of 0 or more characters) or using Java regular expressions, as described in the documentation for the java.util.regex.Pattern class. Usually wildcards will be good enough. For example, if we want to select all files that start with "PR" and end with ".txt", then we would use the wildcard string "PR*.txt" or the regular expression "PR.*\.txt". As you can see, it is generally easier to use wildcards rather than regular expressions. We can also specify a pattern to identify which files should not be processed.
The final part of this screen in the adapter wizard asks if the file contains a single message or many messages. This is confusing because when the screen refers to messages, it really means records.
Tip
XML files
It is worth remembering that a well formed XML document can only have a single root element, and hence an XML input file will normally have only a single input record. In the case of very large XML files, it is possible to have the file adapter batch the file up into multiple messages, in which case the root element is replicated in each message, and the second level elements are treated as records. This behavior is requested by setting the streaming option.
By default, a message will contain a single record from the file. Records will be defined in the next step of the wizard. If the file causes a BPEL process to be started, then a 1000 record file would result in 1000 BPEL processes being initiated. To improve efficiency, records can be batched, and the Publish Messages in Batches of attribute controls the maximum number of records in a message.
Tip
Message batching
It is common for an incoming file to contain many records. These records, when processed, can impact system performance and memory requirements. Hence it is important to align the use of the records with their likely impact on system resources.
Detecting that the file is available
The next step in the wizard allows us to configure the frequency of polling for the inbound file. There are two parameters that can be configured here–the Polling Frequency and the Minimum File Age.
The Polling Frequency just means the time delay between checking to see if a file is available for processing. The adapter will check once per interval to see if the file exists. Setting this too low can consume needless CPU resources, setting it too high can make the system appear unresponsive. 'Too high' and 'too low' are very subjective and will depend on your individual requirements. For example, the polling interval for a file that is expected to be written twice a day may be set to three hours, while the interval for a file that is expected to be written every hour may be set to 15 minutes.
Minimum File Age specifies how old a file must be before it is processed by the adapter. This setting allows a file to be completely written before it is read. For example, a large file may take five minutes to write out from the original application. If the file is read three minutes after it has been created, then it is possible for the adapter to run out of records to read and assume the file has been processed, when in reality, the application is still writing to the file. Setting a minimum age to ten minutes would avoid this problem by giving the application at least ten minutes to write the file.
As an alternative to polling for a file directly, we may use a trigger file to indicate that a file is available. Some systems write large files to disk and then indicate that they are available by writing a trigger file. This avoids the problems with reading an incomplete file we identified in the previous paragraph, without the delay in processing the file that a minimum age field may cause.
Message format
The penultimate step in the file adapter is to set up the format of records or messages in the file. This is one of the most critical steps, as this defines the format of messages generated by a file.
Messages may be opaque, meaning that they are passed around as black boxes. This may be appropriate with a Microsoft Word file, for example, that must merely be transported from point A to point B without being examined. This is indicated by the Native format translation is not required (Schema is Opaque) checkbox.
If the document is already in an XML format, then we can just specify a schema and an expected root element and the job is done. Normally the file is in some non-XML format that must be mapped onto an XML Schema generated through the native format builder wizard, which is invoked through the Define Schema for Native Format button.
Defining a native format schema
Invoking the Native Format Builder wizard brings up an initial start screen that leads on to the first step in the wizard, choosing the type of format, as shown in the following screenshot:
This allows us to identify the overall record structure. If we have an existing schema document that describes the record structure, then we can point to that. Usually, we will need to determine the type of structure of the file ourselves. The choices available are:
- Delimited: These are files such as CSV files (Comma Separated Values), records with spaces, or '+' signs for separators.
- Fixed Length: These are files whose records consist of fixed length fields. Be careful not to confuse these with space-separated files, as if a value does not fill the entire field, it will usually be padded with spaces.
- Complex Type: These files may include nested records like a master detail type structure.
- DTD to be converted to XSD: These are XML Data Type Definition XML files that will be mapped onto an XML Schema description of the file content.
- Cobol Copybook to be converted to native format: These are files that have usually been produced by a COBOL system, often originating from a mainframe.
We will look at a delimited file, as it is one of the most common formats.
Although we are using the separator file type, the steps involved are basically the same for most file types including the fixed length field format, which is also extremely common.
Using a sample file
To make it easier to describe the format of the incoming file, the wizard asks us to specify a file to use as a sample. If necessary, we can skip rows in the file and determine the number of records to read. Obviously, reading a very large number of records may take a while, and if all the variability on the file is in the first ten records, then there is no point in wasting time reading any more sample records. We may also choose to restrict the number of rows processed at runtime.
Setting the character set needs to be done carefully, particularly in international environments where non-ASCII character sets may be common.
After selecting a sample file, the wizard will display an initial view of the file with a guess at the field separators.
Record structure
The next step of the wizard allows us to describe how the records appear in the file.
The first option File contains only one record allows us to process the file as a single message. This can be useful when the file has multiple records, all of the same format, which we want to read as a single message. Use of this option disables batching.
The next option of File contains multiple record instances allows batching to take place. Records are either of the same type or of different types. They can only be marked of different types if they can be distinguished, based on the first field in the record. In other words, in order to choose the Multiple records are of different types, the first field in all the records must be a record type identifier. In the example shown in the preceding screenshot, the first field is either an H for Header records or an R for Records.
Choosing a root element
The next step allows us to define the target namespace and root element of the schema that we are generating.
Note
Don't forget that when using the Native Format Builder wizard, we are just creating an XML Schema document that describes the native (non-XML) format data. Most of the time this schema is transparent to us. However, at times the XML constructs have to emerge, for example, when identifying a name for a root element. The file is described using an XML Schema extension known as NXSD.
As we can see the root element is mandatory. This root element acts as a wrapper for the records in a message. If message batching is set to 1, then each wrapper will have a single sub-element, namely, the record. If the message is set to greater than 1, then each wrapper will have at least one and possibly more sub-elements, each sub-element being a record. There can never be more sub-elements than the batch size.
Message delimiters
Having described the overall structure of the file, we can now drill down into the individual fields. To do this, we first specify the message delimiters.
In addition to field delimiters, we can also specify a record delimiter. Usually record delimiters are new lines. If fields are also wrapped in quotation marks, then these can be stripped off by specifying the Optionally enclosed by character.
Record type names
The wizard will identify the types of records based on the first field in each record, as shown in the preceding screenshot. It is possible to ignore record types by selecting them and clicking Delete. If this is done by mistake, then it is possible to add them back by using the Add button. Only fields that exist in the sample data can be added in the wizard.
Note that if we want to reset the record types screen, then the Scan button will rescan the sample file and look for all the different record types it contains.
The Record Name field can be set by double-clicking it and providing a suitable record name. This record name is the XML element name that encapsulates the record content.
Field properties
Now that we have identified record and field boundaries, we can drill down into the records and define the data types and names of individual fields. This is done for each record type in turn. We can select which records to define by selecting them from the Record Name drop-down box or by pressing the Next Record Type button.
It is important to be as liberal as possible when defining field data types because any mismatches will cause errors that will need to be handled. Being liberal in our record definitions will allow us to validate the messages, as described in Chapter 13, Building Validation into Services, without raising system errors.
The Name column represents the element name of this field. The wizard will attempt to guess the type of the field, but it is important to always check this because the sample data you are using may not include all possibilities. A common error is identifying numbers to be tagged as integers, when they should really be strings—accept integer types only when they are likely to have arithmetic operations performed on them.
Verifying the result
We have now completed our mapping and can verify what has been done by looking at the generated XML Schema file. Note that the generated schema uses some Oracle extensions to enable a non-XML formatted file to be represented as XML. In particular the nxsd namespace prefix is used to identify field separators and record terminators.
Note
The XML Schema generated can be edited manually. This is useful to support nested records (records inside other records) like those that may be found in a file containing order records with nested detail records (an order record contains multiple line item detail records). In this case, it is useful to use the wizard to generate a schema with order records and detail records at the same level. The schema can then be modified by hand to make the detail records children of the order records.
Clicking the Test button brings up a simple test screen that allows us to apply our newly generated schema to the input document and examine the resulting XML.
Clicking Next and then Finish will cause the generated schema file to be saved.
Finishing the wizards
Until now, no work has been saved, except for the XML Schema mapping the file content onto an XML structure. The rest of the adapter settings are not saved, and the endpoint is not set up until the Finish button is clicked on the completion screen, as shown in the following screenshot. Note that the file generated is a Web Service Description Language (WSDL) file with a JCA binding.
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Creating a dummy message type
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>Adding an output message to the read operation
In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
Using the modified interface
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
Selecting the FTP connection
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
Choosing the operation
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Selecting the file destination
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
Note
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Tip
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Detecting that the file is available
The next step in the wizard allows us to configure the frequency of polling for the inbound file. There are two parameters that can be configured here–the Polling Frequency and the Minimum File Age.
The Polling Frequency just means the time delay between checking to see if a file is available for processing. The adapter will check once per interval to see if the file exists. Setting this too low can consume needless CPU resources, setting it too high can make the system appear unresponsive. 'Too high' and 'too low' are very subjective and will depend on your individual requirements. For example, the polling interval for a file that is expected to be written twice a day may be set to three hours, while the interval for a file that is expected to be written every hour may be set to 15 minutes.
Minimum File Age specifies how old a file must be before it is processed by the adapter. This setting allows a file to be completely written before it is read. For example, a large file may take five minutes to write out from the original application. If the file is read three minutes after it has been created, then it is possible for the adapter to run out of records to read and assume the file has been processed, when in reality, the application is still writing to the file. Setting a minimum age to ten minutes would avoid this problem by giving the application at least ten minutes to write the file.
As an alternative to polling for a file directly, we may use a trigger file to indicate that a file is available. Some systems write large files to disk and then indicate that they are available by writing a trigger file. This avoids the problems with reading an incomplete file we identified in the previous paragraph, without the delay in processing the file that a minimum age field may cause.
Message format
The penultimate step in the file adapter is to set up the format of records or messages in the file. This is one of the most critical steps, as this defines the format of messages generated by a file.
Messages may be opaque, meaning that they are passed around as black boxes. This may be appropriate with a Microsoft Word file, for example, that must merely be transported from point A to point B without being examined. This is indicated by the Native format translation is not required (Schema is Opaque) checkbox.
If the document is already in an XML format, then we can just specify a schema and an expected root element and the job is done. Normally the file is in some non-XML format that must be mapped onto an XML Schema generated through the native format builder wizard, which is invoked through the Define Schema for Native Format button.
Defining a native format schema
Invoking the Native Format Builder wizard brings up an initial start screen that leads on to the first step in the wizard, choosing the type of format, as shown in the following screenshot:
This allows us to identify the overall record structure. If we have an existing schema document that describes the record structure, then we can point to that. Usually, we will need to determine the type of structure of the file ourselves. The choices available are:
- Delimited: These are files such as CSV files (Comma Separated Values), records with spaces, or '+' signs for separators.
- Fixed Length: These are files whose records consist of fixed length fields. Be careful not to confuse these with space-separated files, as if a value does not fill the entire field, it will usually be padded with spaces.
- Complex Type: These files may include nested records like a master detail type structure.
- DTD to be converted to XSD: These are XML Data Type Definition XML files that will be mapped onto an XML Schema description of the file content.
- Cobol Copybook to be converted to native format: These are files that have usually been produced by a COBOL system, often originating from a mainframe.
We will look at a delimited file, as it is one of the most common formats.
Although we are using the separator file type, the steps involved are basically the same for most file types including the fixed length field format, which is also extremely common.
Using a sample file
To make it easier to describe the format of the incoming file, the wizard asks us to specify a file to use as a sample. If necessary, we can skip rows in the file and determine the number of records to read. Obviously, reading a very large number of records may take a while, and if all the variability on the file is in the first ten records, then there is no point in wasting time reading any more sample records. We may also choose to restrict the number of rows processed at runtime.
Setting the character set needs to be done carefully, particularly in international environments where non-ASCII character sets may be common.
After selecting a sample file, the wizard will display an initial view of the file with a guess at the field separators.
Record structure
The next step of the wizard allows us to describe how the records appear in the file.
The first option File contains only one record allows us to process the file as a single message. This can be useful when the file has multiple records, all of the same format, which we want to read as a single message. Use of this option disables batching.
The next option of File contains multiple record instances allows batching to take place. Records are either of the same type or of different types. They can only be marked of different types if they can be distinguished, based on the first field in the record. In other words, in order to choose the Multiple records are of different types, the first field in all the records must be a record type identifier. In the example shown in the preceding screenshot, the first field is either an H for Header records or an R for Records.
Choosing a root element
The next step allows us to define the target namespace and root element of the schema that we are generating.
Note
Don't forget that when using the Native Format Builder wizard, we are just creating an XML Schema document that describes the native (non-XML) format data. Most of the time this schema is transparent to us. However, at times the XML constructs have to emerge, for example, when identifying a name for a root element. The file is described using an XML Schema extension known as NXSD.
As we can see the root element is mandatory. This root element acts as a wrapper for the records in a message. If message batching is set to 1, then each wrapper will have a single sub-element, namely, the record. If the message is set to greater than 1, then each wrapper will have at least one and possibly more sub-elements, each sub-element being a record. There can never be more sub-elements than the batch size.
Message delimiters
Having described the overall structure of the file, we can now drill down into the individual fields. To do this, we first specify the message delimiters.
In addition to field delimiters, we can also specify a record delimiter. Usually record delimiters are new lines. If fields are also wrapped in quotation marks, then these can be stripped off by specifying the Optionally enclosed by character.
Record type names
The wizard will identify the types of records based on the first field in each record, as shown in the preceding screenshot. It is possible to ignore record types by selecting them and clicking Delete. If this is done by mistake, then it is possible to add them back by using the Add button. Only fields that exist in the sample data can be added in the wizard.
Note that if we want to reset the record types screen, then the Scan button will rescan the sample file and look for all the different record types it contains.
The Record Name field can be set by double-clicking it and providing a suitable record name. This record name is the XML element name that encapsulates the record content.
Field properties
Now that we have identified record and field boundaries, we can drill down into the records and define the data types and names of individual fields. This is done for each record type in turn. We can select which records to define by selecting them from the Record Name drop-down box or by pressing the Next Record Type button.
It is important to be as liberal as possible when defining field data types because any mismatches will cause errors that will need to be handled. Being liberal in our record definitions will allow us to validate the messages, as described in Chapter 13, Building Validation into Services, without raising system errors.
The Name column represents the element name of this field. The wizard will attempt to guess the type of the field, but it is important to always check this because the sample data you are using may not include all possibilities. A common error is identifying numbers to be tagged as integers, when they should really be strings—accept integer types only when they are likely to have arithmetic operations performed on them.
Verifying the result
We have now completed our mapping and can verify what has been done by looking at the generated XML Schema file. Note that the generated schema uses some Oracle extensions to enable a non-XML formatted file to be represented as XML. In particular the nxsd namespace prefix is used to identify field separators and record terminators.
Note
The XML Schema generated can be edited manually. This is useful to support nested records (records inside other records) like those that may be found in a file containing order records with nested detail records (an order record contains multiple line item detail records). In this case, it is useful to use the wizard to generate a schema with order records and detail records at the same level. The schema can then be modified by hand to make the detail records children of the order records.
Clicking the Test button brings up a simple test screen that allows us to apply our newly generated schema to the input document and examine the resulting XML.
Clicking Next and then Finish will cause the generated schema file to be saved.
Finishing the wizards
Until now, no work has been saved, except for the XML Schema mapping the file content onto an XML structure. The rest of the adapter settings are not saved, and the endpoint is not set up until the Finish button is clicked on the completion screen, as shown in the following screenshot. Note that the file generated is a Web Service Description Language (WSDL) file with a JCA binding.
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Creating a dummy message type
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>Adding an output message to the read operation
In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
Using the modified interface
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
Selecting the FTP connection
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
Choosing the operation
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Selecting the file destination
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
Note
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Tip
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Message format
The penultimate step in the file adapter is to set up the format of records or messages in the file. This is one of the most critical steps, as this defines the format of messages generated by a file.
Messages may be opaque, meaning that they are passed around as black boxes. This may be appropriate with a Microsoft Word file, for example, that must merely be transported from point A to point B without being examined. This is indicated by the Native format translation is not required (Schema is Opaque) checkbox.
If the document is already in an XML format, then we can just specify a schema and an expected root element and the job is done. Normally the file is in some non-XML format that must be mapped onto an XML Schema generated through the native format builder wizard, which is invoked through the Define Schema for Native Format button.
Defining a native format schema
Invoking the Native Format Builder wizard brings up an initial start screen that leads on to the first step in the wizard, choosing the type of format, as shown in the following screenshot:
This allows us to identify the overall record structure. If we have an existing schema document that describes the record structure, then we can point to that. Usually, we will need to determine the type of structure of the file ourselves. The choices available are:
- Delimited: These are files such as CSV files (Comma Separated Values), records with spaces, or '+' signs for separators.
- Fixed Length: These are files whose records consist of fixed length fields. Be careful not to confuse these with space-separated files, as if a value does not fill the entire field, it will usually be padded with spaces.
- Complex Type: These files may include nested records like a master detail type structure.
- DTD to be converted to XSD: These are XML Data Type Definition XML files that will be mapped onto an XML Schema description of the file content.
- Cobol Copybook to be converted to native format: These are files that have usually been produced by a COBOL system, often originating from a mainframe.
We will look at a delimited file, as it is one of the most common formats.
Although we are using the separator file type, the steps involved are basically the same for most file types including the fixed length field format, which is also extremely common.
Using a sample file
To make it easier to describe the format of the incoming file, the wizard asks us to specify a file to use as a sample. If necessary, we can skip rows in the file and determine the number of records to read. Obviously, reading a very large number of records may take a while, and if all the variability on the file is in the first ten records, then there is no point in wasting time reading any more sample records. We may also choose to restrict the number of rows processed at runtime.
Setting the character set needs to be done carefully, particularly in international environments where non-ASCII character sets may be common.
After selecting a sample file, the wizard will display an initial view of the file with a guess at the field separators.
Record structure
The next step of the wizard allows us to describe how the records appear in the file.
The first option File contains only one record allows us to process the file as a single message. This can be useful when the file has multiple records, all of the same format, which we want to read as a single message. Use of this option disables batching.
The next option of File contains multiple record instances allows batching to take place. Records are either of the same type or of different types. They can only be marked of different types if they can be distinguished, based on the first field in the record. In other words, in order to choose the Multiple records are of different types, the first field in all the records must be a record type identifier. In the example shown in the preceding screenshot, the first field is either an H for Header records or an R for Records.
Choosing a root element
The next step allows us to define the target namespace and root element of the schema that we are generating.
Note
Don't forget that when using the Native Format Builder wizard, we are just creating an XML Schema document that describes the native (non-XML) format data. Most of the time this schema is transparent to us. However, at times the XML constructs have to emerge, for example, when identifying a name for a root element. The file is described using an XML Schema extension known as NXSD.
As we can see the root element is mandatory. This root element acts as a wrapper for the records in a message. If message batching is set to 1, then each wrapper will have a single sub-element, namely, the record. If the message is set to greater than 1, then each wrapper will have at least one and possibly more sub-elements, each sub-element being a record. There can never be more sub-elements than the batch size.
Message delimiters
Having described the overall structure of the file, we can now drill down into the individual fields. To do this, we first specify the message delimiters.
In addition to field delimiters, we can also specify a record delimiter. Usually record delimiters are new lines. If fields are also wrapped in quotation marks, then these can be stripped off by specifying the Optionally enclosed by character.
Record type names
The wizard will identify the types of records based on the first field in each record, as shown in the preceding screenshot. It is possible to ignore record types by selecting them and clicking Delete. If this is done by mistake, then it is possible to add them back by using the Add button. Only fields that exist in the sample data can be added in the wizard.
Note that if we want to reset the record types screen, then the Scan button will rescan the sample file and look for all the different record types it contains.
The Record Name field can be set by double-clicking it and providing a suitable record name. This record name is the XML element name that encapsulates the record content.
Field properties
Now that we have identified record and field boundaries, we can drill down into the records and define the data types and names of individual fields. This is done for each record type in turn. We can select which records to define by selecting them from the Record Name drop-down box or by pressing the Next Record Type button.
It is important to be as liberal as possible when defining field data types because any mismatches will cause errors that will need to be handled. Being liberal in our record definitions will allow us to validate the messages, as described in Chapter 13, Building Validation into Services, without raising system errors.
The Name column represents the element name of this field. The wizard will attempt to guess the type of the field, but it is important to always check this because the sample data you are using may not include all possibilities. A common error is identifying numbers to be tagged as integers, when they should really be strings—accept integer types only when they are likely to have arithmetic operations performed on them.
Verifying the result
We have now completed our mapping and can verify what has been done by looking at the generated XML Schema file. Note that the generated schema uses some Oracle extensions to enable a non-XML formatted file to be represented as XML. In particular the nxsd namespace prefix is used to identify field separators and record terminators.
Note
The XML Schema generated can be edited manually. This is useful to support nested records (records inside other records) like those that may be found in a file containing order records with nested detail records (an order record contains multiple line item detail records). In this case, it is useful to use the wizard to generate a schema with order records and detail records at the same level. The schema can then be modified by hand to make the detail records children of the order records.
Clicking the Test button brings up a simple test screen that allows us to apply our newly generated schema to the input document and examine the resulting XML.
Clicking Next and then Finish will cause the generated schema file to be saved.
Finishing the wizards
Until now, no work has been saved, except for the XML Schema mapping the file content onto an XML structure. The rest of the adapter settings are not saved, and the endpoint is not set up until the Finish button is clicked on the completion screen, as shown in the following screenshot. Note that the file generated is a Web Service Description Language (WSDL) file with a JCA binding.
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Creating a dummy message type
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>Adding an output message to the read operation
In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
Using the modified interface
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
Selecting the FTP connection
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
Choosing the operation
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Selecting the file destination
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
Note
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Tip
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Defining a native format schema
Invoking the Native Format Builder wizard brings up an initial start screen that leads on to the first step in the wizard, choosing the type of format, as shown in the following screenshot:
This allows us to identify the overall record structure. If we have an existing schema document that describes the record structure, then we can point to that. Usually, we will need to determine the type of structure of the file ourselves. The choices available are:
- Delimited: These are files such as CSV files (Comma Separated Values), records with spaces, or '+' signs for separators.
- Fixed Length: These are files whose records consist of fixed length fields. Be careful not to confuse these with space-separated files, as if a value does not fill the entire field, it will usually be padded with spaces.
- Complex Type: These files may include nested records like a master detail type structure.
- DTD to be converted to XSD: These are XML Data Type Definition XML files that will be mapped onto an XML Schema description of the file content.
- Cobol Copybook to be converted to native format: These are files that have usually been produced by a COBOL system, often originating from a mainframe.
We will look at a delimited file, as it is one of the most common formats.
Although we are using the separator file type, the steps involved are basically the same for most file types including the fixed length field format, which is also extremely common.
Using a sample file
To make it easier to describe the format of the incoming file, the wizard asks us to specify a file to use as a sample. If necessary, we can skip rows in the file and determine the number of records to read. Obviously, reading a very large number of records may take a while, and if all the variability on the file is in the first ten records, then there is no point in wasting time reading any more sample records. We may also choose to restrict the number of rows processed at runtime.
Setting the character set needs to be done carefully, particularly in international environments where non-ASCII character sets may be common.
After selecting a sample file, the wizard will display an initial view of the file with a guess at the field separators.
Record structure
The next step of the wizard allows us to describe how the records appear in the file.
The first option File contains only one record allows us to process the file as a single message. This can be useful when the file has multiple records, all of the same format, which we want to read as a single message. Use of this option disables batching.
The next option of File contains multiple record instances allows batching to take place. Records are either of the same type or of different types. They can only be marked of different types if they can be distinguished, based on the first field in the record. In other words, in order to choose the Multiple records are of different types, the first field in all the records must be a record type identifier. In the example shown in the preceding screenshot, the first field is either an H for Header records or an R for Records.
Choosing a root element
The next step allows us to define the target namespace and root element of the schema that we are generating.
Don't forget that when using the Native Format Builder wizard, we are just creating an XML Schema document that describes the native (non-XML) format data. Most of the time this schema is transparent to us. However, at times the XML constructs have to emerge, for example, when identifying a name for a root element. The file is described using an XML Schema extension known as NXSD.
As we can see the root element is mandatory. This root element acts as a wrapper for the records in a message. If message batching is set to 1, then each wrapper will have a single sub-element, namely, the record. If the message is set to greater than 1, then each wrapper will have at least one and possibly more sub-elements, each sub-element being a record. There can never be more sub-elements than the batch size.
Message delimiters
Having described the overall structure of the file, we can now drill down into the individual fields. To do this, we first specify the message delimiters.
In addition to field delimiters, we can also specify a record delimiter. Usually record delimiters are new lines. If fields are also wrapped in quotation marks, then these can be stripped off by specifying the Optionally enclosed by character.
Record type names
The wizard will identify the types of records based on the first field in each record, as shown in the preceding screenshot. It is possible to ignore record types by selecting them and clicking Delete. If this is done by mistake, then it is possible to add them back by using the Add button. Only fields that exist in the sample data can be added in the wizard.
Note that if we want to reset the record types screen, then the Scan button will rescan the sample file and look for all the different record types it contains.
The Record Name field can be set by double-clicking it and providing a suitable record name. This record name is the XML element name that encapsulates the record content.
Field properties
Now that we have identified record and field boundaries, we can drill down into the records and define the data types and names of individual fields. This is done for each record type in turn. We can select which records to define by selecting them from the Record Name drop-down box or by pressing the Next Record Type button.
It is important to be as liberal as possible when defining field data types because any mismatches will cause errors that will need to be handled. Being liberal in our record definitions will allow us to validate the messages, as described in Chapter 13, Building Validation into Services, without raising system errors.
The Name column represents the element name of this field. The wizard will attempt to guess the type of the field, but it is important to always check this because the sample data you are using may not include all possibilities. A common error is identifying numbers to be tagged as integers, when they should really be strings—accept integer types only when they are likely to have arithmetic operations performed on them.
Verifying the result
We have now completed our mapping and can verify what has been done by looking at the generated XML Schema file. Note that the generated schema uses some Oracle extensions to enable a non-XML formatted file to be represented as XML. In particular the nxsd namespace prefix is used to identify field separators and record terminators.
The XML Schema generated can be edited manually. This is useful to support nested records (records inside other records) like those that may be found in a file containing order records with nested detail records (an order record contains multiple line item detail records). In this case, it is useful to use the wizard to generate a schema with order records and detail records at the same level. The schema can then be modified by hand to make the detail records children of the order records.
Clicking the Test button brings up a simple test screen that allows us to apply our newly generated schema to the input document and examine the resulting XML.
Clicking Next and then Finish will cause the generated schema file to be saved.
Until now, no work has been saved, except for the XML Schema mapping the file content onto an XML structure. The rest of the adapter settings are not saved, and the endpoint is not set up until the Finish button is clicked on the completion screen, as shown in the following screenshot. Note that the file generated is a Web Service Description Language (WSDL) file with a JCA binding.
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Using a sample file
To make it easier to describe the format of the incoming file, the wizard asks us to specify a file to use as a sample. If necessary, we can skip rows in the file and determine the number of records to read. Obviously, reading a very large number of records may take a while, and if all the variability on the file is in the first ten records, then there is no point in wasting time reading any more sample records. We may also choose to restrict the number of rows processed at runtime.
Setting the character set needs to be done carefully, particularly in international environments where non-ASCII character sets may be common.
After selecting a sample file, the wizard will display an initial view of the file with a guess at the field separators.
Record structure
The next step of the wizard allows us to describe how the records appear in the file.
The first option File contains only one record allows us to process the file as a single message. This can be useful when the file has multiple records, all of the same format, which we want to read as a single message. Use of this option disables batching.
The next option of File contains multiple record instances allows batching to take place. Records are either of the same type or of different types. They can only be marked of different types if they can be distinguished, based on the first field in the record. In other words, in order to choose the Multiple records are of different types, the first field in all the records must be a record type identifier. In the example shown in the preceding screenshot, the first field is either an H for Header records or an R for Records.
Choosing a root element
The next step allows us to define the target namespace and root element of the schema that we are generating.
Don't forget that when using the Native Format Builder wizard, we are just creating an XML Schema document that describes the native (non-XML) format data. Most of the time this schema is transparent to us. However, at times the XML constructs have to emerge, for example, when identifying a name for a root element. The file is described using an XML Schema extension known as NXSD.
As we can see the root element is mandatory. This root element acts as a wrapper for the records in a message. If message batching is set to 1, then each wrapper will have a single sub-element, namely, the record. If the message is set to greater than 1, then each wrapper will have at least one and possibly more sub-elements, each sub-element being a record. There can never be more sub-elements than the batch size.
Message delimiters
Having described the overall structure of the file, we can now drill down into the individual fields. To do this, we first specify the message delimiters.
In addition to field delimiters, we can also specify a record delimiter. Usually record delimiters are new lines. If fields are also wrapped in quotation marks, then these can be stripped off by specifying the Optionally enclosed by character.
Record type names
The wizard will identify the types of records based on the first field in each record, as shown in the preceding screenshot. It is possible to ignore record types by selecting them and clicking Delete. If this is done by mistake, then it is possible to add them back by using the Add button. Only fields that exist in the sample data can be added in the wizard.
Note that if we want to reset the record types screen, then the Scan button will rescan the sample file and look for all the different record types it contains.
The Record Name field can be set by double-clicking it and providing a suitable record name. This record name is the XML element name that encapsulates the record content.
Field properties
Now that we have identified record and field boundaries, we can drill down into the records and define the data types and names of individual fields. This is done for each record type in turn. We can select which records to define by selecting them from the Record Name drop-down box or by pressing the Next Record Type button.
It is important to be as liberal as possible when defining field data types because any mismatches will cause errors that will need to be handled. Being liberal in our record definitions will allow us to validate the messages, as described in Chapter 13, Building Validation into Services, without raising system errors.
The Name column represents the element name of this field. The wizard will attempt to guess the type of the field, but it is important to always check this because the sample data you are using may not include all possibilities. A common error is identifying numbers to be tagged as integers, when they should really be strings—accept integer types only when they are likely to have arithmetic operations performed on them.
Verifying the result
We have now completed our mapping and can verify what has been done by looking at the generated XML Schema file. Note that the generated schema uses some Oracle extensions to enable a non-XML formatted file to be represented as XML. In particular the nxsd namespace prefix is used to identify field separators and record terminators.
The XML Schema generated can be edited manually. This is useful to support nested records (records inside other records) like those that may be found in a file containing order records with nested detail records (an order record contains multiple line item detail records). In this case, it is useful to use the wizard to generate a schema with order records and detail records at the same level. The schema can then be modified by hand to make the detail records children of the order records.
Clicking the Test button brings up a simple test screen that allows us to apply our newly generated schema to the input document and examine the resulting XML.
Clicking Next and then Finish will cause the generated schema file to be saved.
Until now, no work has been saved, except for the XML Schema mapping the file content onto an XML structure. The rest of the adapter settings are not saved, and the endpoint is not set up until the Finish button is clicked on the completion screen, as shown in the following screenshot. Note that the file generated is a Web Service Description Language (WSDL) file with a JCA binding.
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Record structure
The next step of the wizard allows us to describe how the records appear in the file.
The first option File contains only one record allows us to process the file as a single message. This can be useful when the file has multiple records, all of the same format, which we want to read as a single message. Use of this option disables batching.
The next option of File contains multiple record instances allows batching to take place. Records are either of the same type or of different types. They can only be marked of different types if they can be distinguished, based on the first field in the record. In other words, in order to choose the Multiple records are of different types, the first field in all the records must be a record type identifier. In the example shown in the preceding screenshot, the first field is either an H for Header records or an R for Records.
Choosing a root element
The next step allows us to define the target namespace and root element of the schema that we are generating.
Don't forget that when using the Native Format Builder wizard, we are just creating an XML Schema document that describes the native (non-XML) format data. Most of the time this schema is transparent to us. However, at times the XML constructs have to emerge, for example, when identifying a name for a root element. The file is described using an XML Schema extension known as NXSD.
As we can see the root element is mandatory. This root element acts as a wrapper for the records in a message. If message batching is set to 1, then each wrapper will have a single sub-element, namely, the record. If the message is set to greater than 1, then each wrapper will have at least one and possibly more sub-elements, each sub-element being a record. There can never be more sub-elements than the batch size.
Message delimiters
Having described the overall structure of the file, we can now drill down into the individual fields. To do this, we first specify the message delimiters.
In addition to field delimiters, we can also specify a record delimiter. Usually record delimiters are new lines. If fields are also wrapped in quotation marks, then these can be stripped off by specifying the Optionally enclosed by character.
Record type names
The wizard will identify the types of records based on the first field in each record, as shown in the preceding screenshot. It is possible to ignore record types by selecting them and clicking Delete. If this is done by mistake, then it is possible to add them back by using the Add button. Only fields that exist in the sample data can be added in the wizard.
Note that if we want to reset the record types screen, then the Scan button will rescan the sample file and look for all the different record types it contains.
The Record Name field can be set by double-clicking it and providing a suitable record name. This record name is the XML element name that encapsulates the record content.
Field properties
Now that we have identified record and field boundaries, we can drill down into the records and define the data types and names of individual fields. This is done for each record type in turn. We can select which records to define by selecting them from the Record Name drop-down box or by pressing the Next Record Type button.
It is important to be as liberal as possible when defining field data types because any mismatches will cause errors that will need to be handled. Being liberal in our record definitions will allow us to validate the messages, as described in Chapter 13, Building Validation into Services, without raising system errors.
The Name column represents the element name of this field. The wizard will attempt to guess the type of the field, but it is important to always check this because the sample data you are using may not include all possibilities. A common error is identifying numbers to be tagged as integers, when they should really be strings—accept integer types only when they are likely to have arithmetic operations performed on them.
Verifying the result
We have now completed our mapping and can verify what has been done by looking at the generated XML Schema file. Note that the generated schema uses some Oracle extensions to enable a non-XML formatted file to be represented as XML. In particular the nxsd namespace prefix is used to identify field separators and record terminators.
The XML Schema generated can be edited manually. This is useful to support nested records (records inside other records) like those that may be found in a file containing order records with nested detail records (an order record contains multiple line item detail records). In this case, it is useful to use the wizard to generate a schema with order records and detail records at the same level. The schema can then be modified by hand to make the detail records children of the order records.
Clicking the Test button brings up a simple test screen that allows us to apply our newly generated schema to the input document and examine the resulting XML.
Clicking Next and then Finish will cause the generated schema file to be saved.
Until now, no work has been saved, except for the XML Schema mapping the file content onto an XML structure. The rest of the adapter settings are not saved, and the endpoint is not set up until the Finish button is clicked on the completion screen, as shown in the following screenshot. Note that the file generated is a Web Service Description Language (WSDL) file with a JCA binding.
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Choosing a root element
The next step allows us to define the target namespace and root element of the schema that we are generating.
Don't forget that when using the Native Format Builder wizard, we are just creating an XML Schema document that describes the native (non-XML) format data. Most of the time this schema is transparent to us. However, at times the XML constructs have to emerge, for example, when identifying a name for a root element. The file is described using an XML Schema extension known as NXSD.
As we can see the root element is mandatory. This root element acts as a wrapper for the records in a message. If message batching is set to 1, then each wrapper will have a single sub-element, namely, the record. If the message is set to greater than 1, then each wrapper will have at least one and possibly more sub-elements, each sub-element being a record. There can never be more sub-elements than the batch size.
Message delimiters
Having described the overall structure of the file, we can now drill down into the individual fields. To do this, we first specify the message delimiters.
In addition to field delimiters, we can also specify a record delimiter. Usually record delimiters are new lines. If fields are also wrapped in quotation marks, then these can be stripped off by specifying the Optionally enclosed by character.
Record type names
The wizard will identify the types of records based on the first field in each record, as shown in the preceding screenshot. It is possible to ignore record types by selecting them and clicking Delete. If this is done by mistake, then it is possible to add them back by using the Add button. Only fields that exist in the sample data can be added in the wizard.
Note that if we want to reset the record types screen, then the Scan button will rescan the sample file and look for all the different record types it contains.
The Record Name field can be set by double-clicking it and providing a suitable record name. This record name is the XML element name that encapsulates the record content.
Field properties
Now that we have identified record and field boundaries, we can drill down into the records and define the data types and names of individual fields. This is done for each record type in turn. We can select which records to define by selecting them from the Record Name drop-down box or by pressing the Next Record Type button.
It is important to be as liberal as possible when defining field data types because any mismatches will cause errors that will need to be handled. Being liberal in our record definitions will allow us to validate the messages, as described in Chapter 13, Building Validation into Services, without raising system errors.
The Name column represents the element name of this field. The wizard will attempt to guess the type of the field, but it is important to always check this because the sample data you are using may not include all possibilities. A common error is identifying numbers to be tagged as integers, when they should really be strings—accept integer types only when they are likely to have arithmetic operations performed on them.
Verifying the result
We have now completed our mapping and can verify what has been done by looking at the generated XML Schema file. Note that the generated schema uses some Oracle extensions to enable a non-XML formatted file to be represented as XML. In particular the nxsd namespace prefix is used to identify field separators and record terminators.
The XML Schema generated can be edited manually. This is useful to support nested records (records inside other records) like those that may be found in a file containing order records with nested detail records (an order record contains multiple line item detail records). In this case, it is useful to use the wizard to generate a schema with order records and detail records at the same level. The schema can then be modified by hand to make the detail records children of the order records.
Clicking the Test button brings up a simple test screen that allows us to apply our newly generated schema to the input document and examine the resulting XML.
Clicking Next and then Finish will cause the generated schema file to be saved.
Until now, no work has been saved, except for the XML Schema mapping the file content onto an XML structure. The rest of the adapter settings are not saved, and the endpoint is not set up until the Finish button is clicked on the completion screen, as shown in the following screenshot. Note that the file generated is a Web Service Description Language (WSDL) file with a JCA binding.
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Message delimiters
Having described the overall structure of the file, we can now drill down into the individual fields. To do this, we first specify the message delimiters.
In addition to field delimiters, we can also specify a record delimiter. Usually record delimiters are new lines. If fields are also wrapped in quotation marks, then these can be stripped off by specifying the Optionally enclosed by character.
Record type names
The wizard will identify the types of records based on the first field in each record, as shown in the preceding screenshot. It is possible to ignore record types by selecting them and clicking Delete. If this is done by mistake, then it is possible to add them back by using the Add button. Only fields that exist in the sample data can be added in the wizard.
Note that if we want to reset the record types screen, then the Scan button will rescan the sample file and look for all the different record types it contains.
The Record Name field can be set by double-clicking it and providing a suitable record name. This record name is the XML element name that encapsulates the record content.
Field properties
Now that we have identified record and field boundaries, we can drill down into the records and define the data types and names of individual fields. This is done for each record type in turn. We can select which records to define by selecting them from the Record Name drop-down box or by pressing the Next Record Type button.
It is important to be as liberal as possible when defining field data types because any mismatches will cause errors that will need to be handled. Being liberal in our record definitions will allow us to validate the messages, as described in Chapter 13, Building Validation into Services, without raising system errors.
The Name column represents the element name of this field. The wizard will attempt to guess the type of the field, but it is important to always check this because the sample data you are using may not include all possibilities. A common error is identifying numbers to be tagged as integers, when they should really be strings—accept integer types only when they are likely to have arithmetic operations performed on them.
Verifying the result
We have now completed our mapping and can verify what has been done by looking at the generated XML Schema file. Note that the generated schema uses some Oracle extensions to enable a non-XML formatted file to be represented as XML. In particular the nxsd namespace prefix is used to identify field separators and record terminators.
The XML Schema generated can be edited manually. This is useful to support nested records (records inside other records) like those that may be found in a file containing order records with nested detail records (an order record contains multiple line item detail records). In this case, it is useful to use the wizard to generate a schema with order records and detail records at the same level. The schema can then be modified by hand to make the detail records children of the order records.
Clicking the Test button brings up a simple test screen that allows us to apply our newly generated schema to the input document and examine the resulting XML.
Clicking Next and then Finish will cause the generated schema file to be saved.
Until now, no work has been saved, except for the XML Schema mapping the file content onto an XML structure. The rest of the adapter settings are not saved, and the endpoint is not set up until the Finish button is clicked on the completion screen, as shown in the following screenshot. Note that the file generated is a Web Service Description Language (WSDL) file with a JCA binding.
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Record type names
The wizard will identify the types of records based on the first field in each record, as shown in the preceding screenshot. It is possible to ignore record types by selecting them and clicking Delete. If this is done by mistake, then it is possible to add them back by using the Add button. Only fields that exist in the sample data can be added in the wizard.
Note that if we want to reset the record types screen, then the Scan button will rescan the sample file and look for all the different record types it contains.
The Record Name field can be set by double-clicking it and providing a suitable record name. This record name is the XML element name that encapsulates the record content.
Field properties
Now that we have identified record and field boundaries, we can drill down into the records and define the data types and names of individual fields. This is done for each record type in turn. We can select which records to define by selecting them from the Record Name drop-down box or by pressing the Next Record Type button.
It is important to be as liberal as possible when defining field data types because any mismatches will cause errors that will need to be handled. Being liberal in our record definitions will allow us to validate the messages, as described in Chapter 13, Building Validation into Services, without raising system errors.
The Name column represents the element name of this field. The wizard will attempt to guess the type of the field, but it is important to always check this because the sample data you are using may not include all possibilities. A common error is identifying numbers to be tagged as integers, when they should really be strings—accept integer types only when they are likely to have arithmetic operations performed on them.
Verifying the result
We have now completed our mapping and can verify what has been done by looking at the generated XML Schema file. Note that the generated schema uses some Oracle extensions to enable a non-XML formatted file to be represented as XML. In particular the nxsd namespace prefix is used to identify field separators and record terminators.
The XML Schema generated can be edited manually. This is useful to support nested records (records inside other records) like those that may be found in a file containing order records with nested detail records (an order record contains multiple line item detail records). In this case, it is useful to use the wizard to generate a schema with order records and detail records at the same level. The schema can then be modified by hand to make the detail records children of the order records.
Clicking the Test button brings up a simple test screen that allows us to apply our newly generated schema to the input document and examine the resulting XML.
Clicking Next and then Finish will cause the generated schema file to be saved.
Until now, no work has been saved, except for the XML Schema mapping the file content onto an XML structure. The rest of the adapter settings are not saved, and the endpoint is not set up until the Finish button is clicked on the completion screen, as shown in the following screenshot. Note that the file generated is a Web Service Description Language (WSDL) file with a JCA binding.
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Field properties
Now that we have identified record and field boundaries, we can drill down into the records and define the data types and names of individual fields. This is done for each record type in turn. We can select which records to define by selecting them from the Record Name drop-down box or by pressing the Next Record Type button.
It is important to be as liberal as possible when defining field data types because any mismatches will cause errors that will need to be handled. Being liberal in our record definitions will allow us to validate the messages, as described in Chapter 13, Building Validation into Services, without raising system errors.
The Name column represents the element name of this field. The wizard will attempt to guess the type of the field, but it is important to always check this because the sample data you are using may not include all possibilities. A common error is identifying numbers to be tagged as integers, when they should really be strings—accept integer types only when they are likely to have arithmetic operations performed on them.
Verifying the result
We have now completed our mapping and can verify what has been done by looking at the generated XML Schema file. Note that the generated schema uses some Oracle extensions to enable a non-XML formatted file to be represented as XML. In particular the nxsd namespace prefix is used to identify field separators and record terminators.
The XML Schema generated can be edited manually. This is useful to support nested records (records inside other records) like those that may be found in a file containing order records with nested detail records (an order record contains multiple line item detail records). In this case, it is useful to use the wizard to generate a schema with order records and detail records at the same level. The schema can then be modified by hand to make the detail records children of the order records.
Clicking the Test button brings up a simple test screen that allows us to apply our newly generated schema to the input document and examine the resulting XML.
Clicking Next and then Finish will cause the generated schema file to be saved.
Until now, no work has been saved, except for the XML Schema mapping the file content onto an XML structure. The rest of the adapter settings are not saved, and the endpoint is not set up until the Finish button is clicked on the completion screen, as shown in the following screenshot. Note that the file generated is a Web Service Description Language (WSDL) file with a JCA binding.
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Verifying the result
We have now completed our mapping and can verify what has been done by looking at the generated XML Schema file. Note that the generated schema uses some Oracle extensions to enable a non-XML formatted file to be represented as XML. In particular the nxsd namespace prefix is used to identify field separators and record terminators.
The XML Schema generated can be edited manually. This is useful to support nested records (records inside other records) like those that may be found in a file containing order records with nested detail records (an order record contains multiple line item detail records). In this case, it is useful to use the wizard to generate a schema with order records and detail records at the same level. The schema can then be modified by hand to make the detail records children of the order records.
Clicking the Test button brings up a simple test screen that allows us to apply our newly generated schema to the input document and examine the resulting XML.
Clicking Next and then Finish will cause the generated schema file to be saved.
Until now, no work has been saved, except for the XML Schema mapping the file content onto an XML structure. The rest of the adapter settings are not saved, and the endpoint is not set up until the Finish button is clicked on the completion screen, as shown in the following screenshot. Note that the file generated is a Web Service Description Language (WSDL) file with a JCA binding.
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Finishing the wizards
Until now, no work has been saved, except for the XML Schema mapping the file content onto an XML structure. The rest of the adapter settings are not saved, and the endpoint is not set up until the Finish button is clicked on the completion screen, as shown in the following screenshot. Note that the file generated is a Web Service Description Language (WSDL) file with a JCA binding.
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Creating a dummy message type
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>Adding an output message to the read operation
In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
Using the modified interface
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
Selecting the FTP connection
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
Choosing the operation
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Selecting the file destination
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
Note
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Tip
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Throttling the file and FTP adapter
The file and FTP adapters can consume a lot of resources when processing large files (thousands of records) because they keep sending messages with batches of records until the file is processed, while not waiting for the records to be processed. This behavior can be altered by forcing them to wait until a message is processed before sending another message. This is done by making the following changes to the WSDL generated by the wizard. This changes the one-way read operation into a two-way read operation that will not complete until a reply is generated by our code in BPEL or the Service Bus.
Creating a dummy message type
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>Adding an output message to the read operation
In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
Using the modified interface
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
Writing a payroll file
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
Selecting the FTP connection
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
Choosing the operation
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Selecting the file destination
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
Note
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Tip
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Moving, copying, and deleting files
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
Adapter headers
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
Testing the file adapters
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Creating a dummy message type
Add a new message definition to the WSDL like the one in the following code snippet:
<message name="Dummy_msg">
<part xmlns:xsd="http://www.w3.org/2001/XMLSchema"
name="Dummy" type="xsd:string"/>
</message>Adding an output message to the read operation
In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
Using the modified interface
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
Selecting the FTP connection
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
Choosing the operation
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Selecting the file destination
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
Note
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Tip
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Adding an output message to the read operation
In the <portType>
, add an <output> element to the read <operation> element.
<portType name="Read_ptt">
<operation name="Read">
<input message="tns:PayrollList_msg"/>
<output message="tns:Dummy_msg"/>
</operation>
</portType>In the <jca:operation> element, add an empty <output/> element.
Using the modified interface
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
Selecting the FTP connection
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
Choosing the operation
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Selecting the file destination
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
Note
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Tip
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Using the modified interface
The adapter will now have a two way interface and will need to receive a reply to a message before it sends the next batch of records, thus throttling the throughput. Note that no data needs to be sent in the reply message. This will limit the number of active operations to the number of threads assigned to the file adapter.
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
Selecting the FTP connection
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
Choosing the operation
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Selecting the file destination
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
Note
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Tip
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Writing a payroll file
We can now use the FTP adapter to write the payroll file to a remote filesystem. This requires us to create another adapter within our BPEL process, Mediator, or Service Bus. Setting up the FTP adapter to write to a remote filesystem is very similar to reading files with the file adapter.
Selecting the FTP connection
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
Choosing the operation
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Selecting the file destination
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
Note
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Tip
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Moving, copying, and deleting files
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
Adapter headers
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
Testing the file adapters
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Selecting the FTP connection
The first difference is that when using the FTP adapter instead of the File adapter, we have to specify an FTP connection to use in the underlying application server. This connection is set up in the application server running the adapter. For example, when using the WebLogic Application Server, the WebLogic Console can be used. The JNDI location of the connection factory is the location that must be provided to the wizard. The JNDI location must be configured in the application server using the administrative tools provided by the application server. Refer to your application server documentation for details on how to do this, as it varies between applications servers.
Choosing the operation
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Selecting the file destination
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
Note
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Tip
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Choosing the operation
When we choose the type of operation, we again notice that the screen is different from the file adapter, having an additional File Type category. This relates to the Ascii and Binary settings of an FTP session. ASCII causes the FTP transfer to adapt to changes in character encoding between the two systems, for example, converting between EBCDIC and ASCII or altering line feeds between systems. When using text files, it is generally a good idea to select the ASCII format. When sending binary files, it is vital that the binary file type is used to avoid any unfortunate and unwanted transformations.
Selecting the file destination
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
Note
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Tip
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Selecting the file destination
Choosing where the file is created is the same for both the FTP and the file adapter. Again, there is a choice of physical or logical paths. The file naming convention allows us some control over the name of the output file. In addition to the %SEQ% symbol that inserts a unique sequence number, it is also possible to insert a date or date time string into the filename. Note that in the current release, you cannot have both a date time string and a sequence string in the file naming convention.
Note
When using a date time string as part of the filename, files with the same date time string will overwrite each other. If this is the case, then consider using a sequence number instead.
When producing an output file, we can either keep appending to a single file by selecting the Append to existing file checkbox, which will keep growing without limit, or we can create new files, which will be dependent on attributes of the data being written. This is the normal way of working for non-XML files, and a new output file will be generated when one or more records are written to the adapter.
The criteria for deciding to write to a new file are as follows:
- Number of Messages Equals: This criterion forces the file to be written when the given number of messages is reached. This can be thought of as batching the output so that we reduce the number of files created.
- Elapsed Time Exceeds: This criterion puts a time limit on how long the adapter will keep the file open. This places an upper time limit on creating an output file.
- File Size Exceeds: This criterion allows us to limit the file sizes. As soon as a message causes the file to exceed the given size, no further message will be appended to this file.
These criteria can all be applied together, and as soon as one of them is satisfied, a new file will be created.
Tip
Writing XML files
When writing XML files, care should be taken to have only a single message per file, or else there will be multiple XML root elements in the document that will make it an invalid XML document.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Completing the FTP file writer service
The next step in the wizard is to define the actual record formats. This is exactly the same as when creating an input file. If we don't have an existing XML Schema for the output file, then we can use the wizard to create one if we have a sample file to use.
Finally, remember to run through the wizard to the end, and click Finish rather than Cancel or our entire configuration will be lost.
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Moving, copying, and deleting files
Sometimes we will just want an adapter to move, copy, or delete a file without reading it. We will use the ability of the file adapter to move a file (refer to Chapter 16, Message Interaction Patterns, to set up a scheduler service within the SOA Suite).
The following steps will configure an outbound file or FTP adapter to move, copy, or delete a file without reading it.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
Adapter headers
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
Testing the file adapters
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Generating an adapter
Use the file or FTP adapter wizard to generate an outbound adapter with a file synchronous read or FTP synchronous get operation. You may also use a write or put operation. The data location should use physical directories, and the content should be marked as opaque, so that there is no need to understand the content of the file. Once this has been done, we will modify the WSDL generated to add additional operations.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Modifying the port type
First, we edit the WSDL file itself, which we call <AdapterServiceName>.wsdl. Modify the port type of the adapter to include the additional operations required, as shown in the following code snippet. Use the same message type as the operation generated by the wizard.
<portType name="Write_ptt">
<operation name="Write">
<input message="tns:Write_msg"/>
</operation>
<operation name="Move">
<input message="tns:Write_msg"/>
</operation>
</portType>Note that the following operation names are supported:
- Move
- Copy
- Delete
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Modifying the binding
We now edit the bindings which are contained in a separate file to the WSDL called <AdapterServiceName>_<file/ftp>.jca. Bindings describe how the service description maps onto the physical service implementation. For now, we will just modify the binding to add the additional operations needed and map them to the appropriate implementation, as shown in the following code snippet:
<endpoint-interaction portType="Write_ptt" operation="Write">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileInteractionSpec">
<property name="PhysicalDirectory" value="/user/oracle"/>
<property name="FileNamingConvention" value="fred.txt"/>
<property name="Append" value="false"/>
</interaction-spec>
</endpoint-interaction>
<endpoint-interaction portType="Write_ptt" operation="Move">
<interaction-spec className="oracle.tip.adapter.file.outbound.FileIoInteractionSpec">
<property name="Type" value="MOVE"/>
<property name="SourcePhysicalDirectory" value="/usr/oracle"/>
<property name="SourceFileName" value="fred.txt"/>
<property name="TargetPhysicalDirectory" value="/usr/payroll"/>
<property name="TargetFileName" value="Payroll.txt"/>
</interaction-spec>
</endpoint-interaction>
Note that the following types are supported for use with the equivalent operation names. Observe that operation names are mixed case and types are uppercase:
MOVECOPYDELETE
The interaction-spec is used to define the types of operations supported by this particular binding. It references a Java class that provides the functionality and may have properties associated with it to configure its behavior. When using the FTP adapter for move, copy, and delete operations, the InteractionSpec property in the <AdapterServiceName>_ftp.jca file must be changed to oracle.tip.adapter.ftp.outbound.FTPIoInteractionSpec.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Configuring file locations through additional header properties
In order to allow runtime configuration of the source and destination locations, it is necessary to pass the source and destination information as properties of the call to the adapter.
For example, when using a BPEL invoke activity, we would pass the properties, as shown in the following code snippet:
<invoke name="Invoke_Move" inputVariable="Invoke_Move_InputVariable"
partnerLink="MoveFileService" portType="ns1:Write_ptt"
operation="Move">
<bpelx:inputProperty name="jca.file.SourceDirectory"
variable="srcDir"/>
<bpelx:inputProperty name="jca.file.SourceFileName"
variable="srcFile"/>
<bpelx:inputProperty name="jca.file.TargetDirectory"
variable="dstDir"/>
<bpelx:inputProperty name="jca.file.TargetFileName"
variable="dstFile"/>
</invoke>These properties will override the default values in the .jca file and can be used to dynamically select at runtime the locations to be used for the move, copy, or delete operation. The properties may be edited in the source tab of the BPEL document, the .bpel file, or they may be created and modified through the Properties tab of the Invoke dialog in the BPEL visual editor.
With these modifications, the move, copy, or delete operations will appear as additional operations on the service that can be invoked from the service bus or within BPEL.
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Adapter headers
In addition to the data associated with the service being provided by the adapter, sometimes referred to as the payload of the service, it is also possible to configure or obtain information about the operation of an adapter through header messages. Header messages are passed as properties to the adapter. We demonstrated this in the previous section when setting the header properties for the Move operation of the file adapter.
The properties passed are of the following two formats:
<property name="AdapterSpecificPropertyName" value="data"/> <property name="AdapterSpecificPropertyName" variable="varName"/>
The former style allows the passing of literal values through the header. The latter allows the property to be set from a string variable.
Testing the file adapters
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Testing the file adapters
We can test the adapters by using them within a BPEL process or a Mediator like the one shown in the following screenshot. Building a BPEL process is covered in Chapter 5, Building Composite Services and Business Processes. This uses the two services we that have just described and links them with a copy operation that transforms data from one format to the other.
Creating services from databases
Along with files, databases are one of the most common ways of interacting with existing applications and providing them with a service interface. In this section we will investigate how to write recordrs into the database using the database adapter.
Writing to a database
Before we configure a database adapter, we first need to create a new database connection within JDeveloper. This is done by creating a Database Connection from the New Gallery.
Choosing a database connection brings up the database connection wizard, which allows us to enter the connection details of our database.
Selecting the database schema
With an established database connection, we can now create a service based on a database table. We will create a service that updates the database with the payroll details. The model for the database tables is shown in the following screenshot:

Now that we have our database connection, we can run the Database Adapter Wizard by dragging the database adapter icon from the tool palette onto a BPEL process or an SCA Assembly. This starts the Database Adapter Wizard, and after giving the service a name, we come to the Service Connection screen. This is shown as follows:

This allows us to choose a local connection in JDeveloper to use and also to select the JNDI location in the runtime environment of the database connection. Note that this JNDI connection must be configured as part of the database adapter in the default application in a similar way to the configuration of the FTP adapter.
Tip
How connections are resolved by the database adapter
When the adapter tries to connect to the database, it first tries to use the JNDI name provided, which should map to a JCA connection factory in the application server. If this name does not exist, then the adapter will use the database connection details from the JDeveloper database connection that was used in the wizard. This behavior is very convenient for development environments because it means that you can deploy and test the adapters in development without having to configure the JCA connection factories. However, best practice is to always configure the JCA adapter in the target environment to avoid unexpected connection failures.
Identifying the operation type
The database adapter has many ways in which it can interact with the database to provide a service interface.

The Operation Type splits into two groups, calls into the database and events generated from the database. Calls into the database cover the following operations:
- The stored procedure or function call to execute a specific piece of code in the database. This could either update the database or retrieve information, but in either case, it is a synchronous call into the database.
- Perform an insert, update, delete, or select operation on the database. Again, this is done synchronously as a call into the database.
- Poll for new or changed records in a database table. This is done as a call into the SCA Assembly or BPEL.
- Execute custom SQL. This again runs the SQL synchronously against the database.
Polling for new or changed records is the only way for the database adapter to generate messages to be consumed in a BPEL process or an SCA Assembly. If we wish the adapter to wait for BPEL or the SCA Assembly to process the message, then we can use the Do Synchronous Post to BPEL checkbox. For this exercise, we will select insert / update for the operation.
Identifying tables to be operated on
The next step in the wizard asks which table is the root table or the beginning of the query. To select this, we first click the Import Tables… button to bring up the Import Tables dialog.

Once we have imported the tables we need, we then select the PAYROLLITEM table as the root table. We do this because each record will create a new PAYROLLITEM entry. All operations through the database adapter must be done with a root table. Any other table must be referenceable from this root table.

Identifying the relationship between tables
As we have more than one table involved in this operation, we need to decide which table relationship we want to use. In this case, we want to tie a payroll item back to a single employee, so we select the one-to-one relationship.

We can now finish the creation of the database adapter and hook it up with the file adapter we created earlier to allow us to read records from a file and place them in a database.
Note
In our example, the adapter was able to work out relationships between tables by analysis of the foreign keys. If foreign key relationships do not exist, then the Create button may be used to inform the adapter of relationships that exist between tables.
Under the covers
Under the covers, a lot has happened. An offline copy of the relevant database schema has been created so that the design time is not reliant on being permanently connected to a database. The actual mapping of a database onto an XML document has also occurred. This is done using Oracle TopLink to create the mapping and a lot of the functions of the wizard are implemented using TopLink. The mapping can be further refined using the features of TopLink.
Tip
Using keys
Always identify the Primary Key for any table used by the database adapter. This can be done by applying a Primary Key constraint in the database, or if no such key has been created, then TopLink will prompt you to create one. If you have to create one in TopLink, then make sure it is really a Primary Key. TopLink optimizes its use of the database by maintaining an identity for each row in a table with a Primary Key. It only reads the Primary Key on select statements and then checks to see which records it needs to read in from the database. This reduces the amount of work mapping fields that have already been mapped because a record appears multiple times in the selection. If you don't identify a Primary Key correctly, then TopLink may incorrectly identify different records as being the same record and only load the data for the first such record encountered. So if you seem to be getting a lot of identical records in response to a query that should have separate records, then check your Primary Key definitions.
Writing to a database
Before we configure a database adapter, we first need to create a new database connection within JDeveloper. This is done by creating a Database Connection from the New Gallery.
Choosing a database connection brings up the database connection wizard, which allows us to enter the connection details of our database.
Selecting the database schema
With an established database connection, we can now create a service based on a database table. We will create a service that updates the database with the payroll details. The model for the database tables is shown in the following screenshot:
Now that we have our database connection, we can run the Database Adapter Wizard by dragging the database adapter icon from the tool palette onto a BPEL process or an SCA Assembly. This starts the Database Adapter Wizard, and after giving the service a name, we come to the Service Connection screen. This is shown as follows:
This allows us to choose a local connection in JDeveloper to use and also to select the JNDI location in the runtime environment of the database connection. Note that this JNDI connection must be configured as part of the database adapter in the default application in a similar way to the configuration of the FTP adapter.
Tip
How connections are resolved by the database adapter
When the adapter tries to connect to the database, it first tries to use the JNDI name provided, which should map to a JCA connection factory in the application server. If this name does not exist, then the adapter will use the database connection details from the JDeveloper database connection that was used in the wizard. This behavior is very convenient for development environments because it means that you can deploy and test the adapters in development without having to configure the JCA connection factories. However, best practice is to always configure the JCA adapter in the target environment to avoid unexpected connection failures.
Identifying the operation type
The database adapter has many ways in which it can interact with the database to provide a service interface.
The Operation Type splits into two groups, calls into the database and events generated from the database. Calls into the database cover the following operations:
- The stored procedure or function call to execute a specific piece of code in the database. This could either update the database or retrieve information, but in either case, it is a synchronous call into the database.
- Perform an insert, update, delete, or select operation on the database. Again, this is done synchronously as a call into the database.
- Poll for new or changed records in a database table. This is done as a call into the SCA Assembly or BPEL.
- Execute custom SQL. This again runs the SQL synchronously against the database.
Polling for new or changed records is the only way for the database adapter to generate messages to be consumed in a BPEL process or an SCA Assembly. If we wish the adapter to wait for BPEL or the SCA Assembly to process the message, then we can use the Do Synchronous Post to BPEL checkbox. For this exercise, we will select insert / update for the operation.
Identifying tables to be operated on
The next step in the wizard asks which table is the root table or the beginning of the query. To select this, we first click the Import Tables… button to bring up the Import Tables dialog.
Once we have imported the tables we need, we then select the PAYROLLITEM table as the root table. We do this because each record will create a new PAYROLLITEM entry. All operations through the database adapter must be done with a root table. Any other table must be referenceable from this root table.
Identifying the relationship between tables
As we have more than one table involved in this operation, we need to decide which table relationship we want to use. In this case, we want to tie a payroll item back to a single employee, so we select the one-to-one relationship.
We can now finish the creation of the database adapter and hook it up with the file adapter we created earlier to allow us to read records from a file and place them in a database.
Note
In our example, the adapter was able to work out relationships between tables by analysis of the foreign keys. If foreign key relationships do not exist, then the Create button may be used to inform the adapter of relationships that exist between tables.
Under the covers
Under the covers, a lot has happened. An offline copy of the relevant database schema has been created so that the design time is not reliant on being permanently connected to a database. The actual mapping of a database onto an XML document has also occurred. This is done using Oracle TopLink to create the mapping and a lot of the functions of the wizard are implemented using TopLink. The mapping can be further refined using the features of TopLink.
Tip
Using keys
Always identify the Primary Key for any table used by the database adapter. This can be done by applying a Primary Key constraint in the database, or if no such key has been created, then TopLink will prompt you to create one. If you have to create one in TopLink, then make sure it is really a Primary Key. TopLink optimizes its use of the database by maintaining an identity for each row in a table with a Primary Key. It only reads the Primary Key on select statements and then checks to see which records it needs to read in from the database. This reduces the amount of work mapping fields that have already been mapped because a record appears multiple times in the selection. If you don't identify a Primary Key correctly, then TopLink may incorrectly identify different records as being the same record and only load the data for the first such record encountered. So if you seem to be getting a lot of identical records in response to a query that should have separate records, then check your Primary Key definitions.
Selecting the database schema
With an established database connection, we can now create a service based on a database table. We will create a service that updates the database with the payroll details. The model for the database tables is shown in the following screenshot:
Now that we have our database connection, we can run the Database Adapter Wizard by dragging the database adapter icon from the tool palette onto a BPEL process or an SCA Assembly. This starts the Database Adapter Wizard, and after giving the service a name, we come to the Service Connection screen. This is shown as follows:
This allows us to choose a local connection in JDeveloper to use and also to select the JNDI location in the runtime environment of the database connection. Note that this JNDI connection must be configured as part of the database adapter in the default application in a similar way to the configuration of the FTP adapter.
Tip
How connections are resolved by the database adapter
When the adapter tries to connect to the database, it first tries to use the JNDI name provided, which should map to a JCA connection factory in the application server. If this name does not exist, then the adapter will use the database connection details from the JDeveloper database connection that was used in the wizard. This behavior is very convenient for development environments because it means that you can deploy and test the adapters in development without having to configure the JCA connection factories. However, best practice is to always configure the JCA adapter in the target environment to avoid unexpected connection failures.
Identifying the operation type
The database adapter has many ways in which it can interact with the database to provide a service interface.
The Operation Type splits into two groups, calls into the database and events generated from the database. Calls into the database cover the following operations:
- The stored procedure or function call to execute a specific piece of code in the database. This could either update the database or retrieve information, but in either case, it is a synchronous call into the database.
- Perform an insert, update, delete, or select operation on the database. Again, this is done synchronously as a call into the database.
- Poll for new or changed records in a database table. This is done as a call into the SCA Assembly or BPEL.
- Execute custom SQL. This again runs the SQL synchronously against the database.
Polling for new or changed records is the only way for the database adapter to generate messages to be consumed in a BPEL process or an SCA Assembly. If we wish the adapter to wait for BPEL or the SCA Assembly to process the message, then we can use the Do Synchronous Post to BPEL checkbox. For this exercise, we will select insert / update for the operation.
Identifying tables to be operated on
The next step in the wizard asks which table is the root table or the beginning of the query. To select this, we first click the Import Tables… button to bring up the Import Tables dialog.
Once we have imported the tables we need, we then select the PAYROLLITEM table as the root table. We do this because each record will create a new PAYROLLITEM entry. All operations through the database adapter must be done with a root table. Any other table must be referenceable from this root table.
Identifying the relationship between tables
As we have more than one table involved in this operation, we need to decide which table relationship we want to use. In this case, we want to tie a payroll item back to a single employee, so we select the one-to-one relationship.
We can now finish the creation of the database adapter and hook it up with the file adapter we created earlier to allow us to read records from a file and place them in a database.
Note
In our example, the adapter was able to work out relationships between tables by analysis of the foreign keys. If foreign key relationships do not exist, then the Create button may be used to inform the adapter of relationships that exist between tables.
Under the covers
Under the covers, a lot has happened. An offline copy of the relevant database schema has been created so that the design time is not reliant on being permanently connected to a database. The actual mapping of a database onto an XML document has also occurred. This is done using Oracle TopLink to create the mapping and a lot of the functions of the wizard are implemented using TopLink. The mapping can be further refined using the features of TopLink.
Tip
Using keys
Always identify the Primary Key for any table used by the database adapter. This can be done by applying a Primary Key constraint in the database, or if no such key has been created, then TopLink will prompt you to create one. If you have to create one in TopLink, then make sure it is really a Primary Key. TopLink optimizes its use of the database by maintaining an identity for each row in a table with a Primary Key. It only reads the Primary Key on select statements and then checks to see which records it needs to read in from the database. This reduces the amount of work mapping fields that have already been mapped because a record appears multiple times in the selection. If you don't identify a Primary Key correctly, then TopLink may incorrectly identify different records as being the same record and only load the data for the first such record encountered. So if you seem to be getting a lot of identical records in response to a query that should have separate records, then check your Primary Key definitions.
Identifying the operation type
The database adapter has many ways in which it can interact with the database to provide a service interface.
The Operation Type splits into two groups, calls into the database and events generated from the database. Calls into the database cover the following operations:
- The stored procedure or function call to execute a specific piece of code in the database. This could either update the database or retrieve information, but in either case, it is a synchronous call into the database.
- Perform an insert, update, delete, or select operation on the database. Again, this is done synchronously as a call into the database.
- Poll for new or changed records in a database table. This is done as a call into the SCA Assembly or BPEL.
- Execute custom SQL. This again runs the SQL synchronously against the database.
Polling for new or changed records is the only way for the database adapter to generate messages to be consumed in a BPEL process or an SCA Assembly. If we wish the adapter to wait for BPEL or the SCA Assembly to process the message, then we can use the Do Synchronous Post to BPEL checkbox. For this exercise, we will select insert / update for the operation.
Identifying tables to be operated on
The next step in the wizard asks which table is the root table or the beginning of the query. To select this, we first click the Import Tables… button to bring up the Import Tables dialog.
Once we have imported the tables we need, we then select the PAYROLLITEM table as the root table. We do this because each record will create a new PAYROLLITEM entry. All operations through the database adapter must be done with a root table. Any other table must be referenceable from this root table.
Identifying the relationship between tables
As we have more than one table involved in this operation, we need to decide which table relationship we want to use. In this case, we want to tie a payroll item back to a single employee, so we select the one-to-one relationship.
We can now finish the creation of the database adapter and hook it up with the file adapter we created earlier to allow us to read records from a file and place them in a database.
Note
In our example, the adapter was able to work out relationships between tables by analysis of the foreign keys. If foreign key relationships do not exist, then the Create button may be used to inform the adapter of relationships that exist between tables.
Under the covers
Under the covers, a lot has happened. An offline copy of the relevant database schema has been created so that the design time is not reliant on being permanently connected to a database. The actual mapping of a database onto an XML document has also occurred. This is done using Oracle TopLink to create the mapping and a lot of the functions of the wizard are implemented using TopLink. The mapping can be further refined using the features of TopLink.
Tip
Using keys
Always identify the Primary Key for any table used by the database adapter. This can be done by applying a Primary Key constraint in the database, or if no such key has been created, then TopLink will prompt you to create one. If you have to create one in TopLink, then make sure it is really a Primary Key. TopLink optimizes its use of the database by maintaining an identity for each row in a table with a Primary Key. It only reads the Primary Key on select statements and then checks to see which records it needs to read in from the database. This reduces the amount of work mapping fields that have already been mapped because a record appears multiple times in the selection. If you don't identify a Primary Key correctly, then TopLink may incorrectly identify different records as being the same record and only load the data for the first such record encountered. So if you seem to be getting a lot of identical records in response to a query that should have separate records, then check your Primary Key definitions.
Identifying tables to be operated on
The next step in the wizard asks which table is the root table or the beginning of the query. To select this, we first click the Import Tables… button to bring up the Import Tables dialog.
Once we have imported the tables we need, we then select the PAYROLLITEM table as the root table. We do this because each record will create a new PAYROLLITEM entry. All operations through the database adapter must be done with a root table. Any other table must be referenceable from this root table.
Identifying the relationship between tables
As we have more than one table involved in this operation, we need to decide which table relationship we want to use. In this case, we want to tie a payroll item back to a single employee, so we select the one-to-one relationship.
We can now finish the creation of the database adapter and hook it up with the file adapter we created earlier to allow us to read records from a file and place them in a database.
Note
In our example, the adapter was able to work out relationships between tables by analysis of the foreign keys. If foreign key relationships do not exist, then the Create button may be used to inform the adapter of relationships that exist between tables.
Under the covers
Under the covers, a lot has happened. An offline copy of the relevant database schema has been created so that the design time is not reliant on being permanently connected to a database. The actual mapping of a database onto an XML document has also occurred. This is done using Oracle TopLink to create the mapping and a lot of the functions of the wizard are implemented using TopLink. The mapping can be further refined using the features of TopLink.
Tip
Using keys
Always identify the Primary Key for any table used by the database adapter. This can be done by applying a Primary Key constraint in the database, or if no such key has been created, then TopLink will prompt you to create one. If you have to create one in TopLink, then make sure it is really a Primary Key. TopLink optimizes its use of the database by maintaining an identity for each row in a table with a Primary Key. It only reads the Primary Key on select statements and then checks to see which records it needs to read in from the database. This reduces the amount of work mapping fields that have already been mapped because a record appears multiple times in the selection. If you don't identify a Primary Key correctly, then TopLink may incorrectly identify different records as being the same record and only load the data for the first such record encountered. So if you seem to be getting a lot of identical records in response to a query that should have separate records, then check your Primary Key definitions.
Identifying the relationship between tables
As we have more than one table involved in this operation, we need to decide which table relationship we want to use. In this case, we want to tie a payroll item back to a single employee, so we select the one-to-one relationship.
We can now finish the creation of the database adapter and hook it up with the file adapter we created earlier to allow us to read records from a file and place them in a database.
Note
In our example, the adapter was able to work out relationships between tables by analysis of the foreign keys. If foreign key relationships do not exist, then the Create button may be used to inform the adapter of relationships that exist between tables.
Under the covers
Under the covers, a lot has happened. An offline copy of the relevant database schema has been created so that the design time is not reliant on being permanently connected to a database. The actual mapping of a database onto an XML document has also occurred. This is done using Oracle TopLink to create the mapping and a lot of the functions of the wizard are implemented using TopLink. The mapping can be further refined using the features of TopLink.
Tip
Using keys
Always identify the Primary Key for any table used by the database adapter. This can be done by applying a Primary Key constraint in the database, or if no such key has been created, then TopLink will prompt you to create one. If you have to create one in TopLink, then make sure it is really a Primary Key. TopLink optimizes its use of the database by maintaining an identity for each row in a table with a Primary Key. It only reads the Primary Key on select statements and then checks to see which records it needs to read in from the database. This reduces the amount of work mapping fields that have already been mapped because a record appears multiple times in the selection. If you don't identify a Primary Key correctly, then TopLink may incorrectly identify different records as being the same record and only load the data for the first such record encountered. So if you seem to be getting a lot of identical records in response to a query that should have separate records, then check your Primary Key definitions.
Under the covers
Under the covers, a lot has happened. An offline copy of the relevant database schema has been created so that the design time is not reliant on being permanently connected to a database. The actual mapping of a database onto an XML document has also occurred. This is done using Oracle TopLink to create the mapping and a lot of the functions of the wizard are implemented using TopLink. The mapping can be further refined using the features of TopLink.
Tip
Using keys
Always identify the Primary Key for any table used by the database adapter. This can be done by applying a Primary Key constraint in the database, or if no such key has been created, then TopLink will prompt you to create one. If you have to create one in TopLink, then make sure it is really a Primary Key. TopLink optimizes its use of the database by maintaining an identity for each row in a table with a Primary Key. It only reads the Primary Key on select statements and then checks to see which records it needs to read in from the database. This reduces the amount of work mapping fields that have already been mapped because a record appears multiple times in the selection. If you don't identify a Primary Key correctly, then TopLink may incorrectly identify different records as being the same record and only load the data for the first such record encountered. So if you seem to be getting a lot of identical records in response to a query that should have separate records, then check your Primary Key definitions.
Summary
In this chapter, we have looked at how to use the file and database adapters to turn file and database interfaces into services that can be consumed by the rest of the SOA Suite. Note that when using the adapters, the schemas are automatically generated and changing the way the adapter works may mean a change in the schema. Therefore, in the next chapter, we will look at how to isolate our applications from the actual adapter service details.
