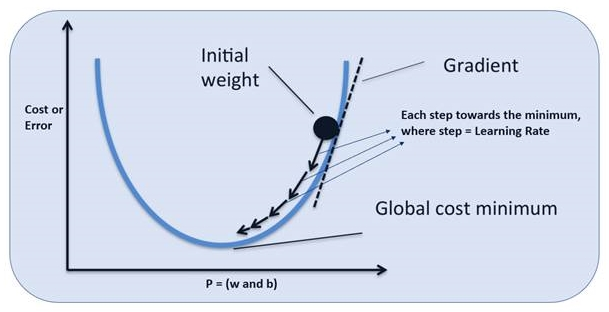
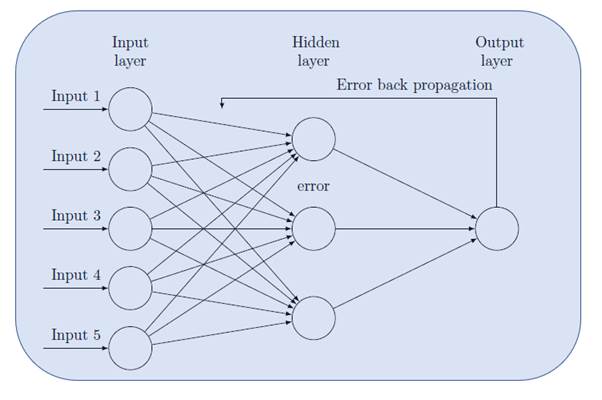
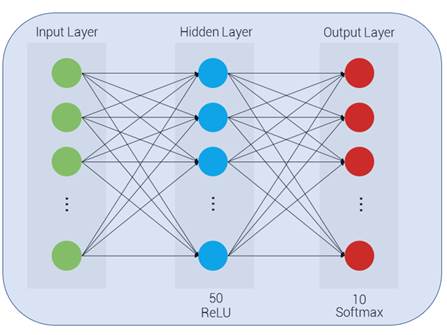
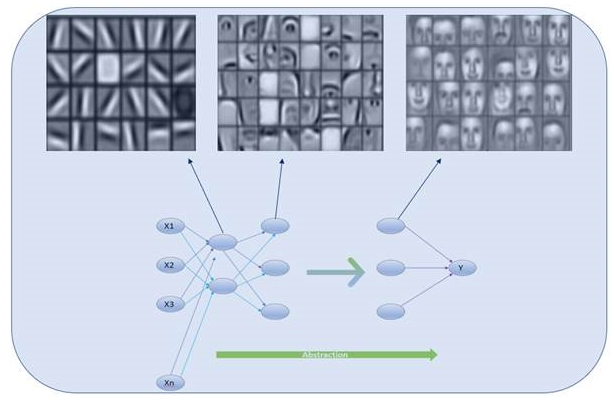
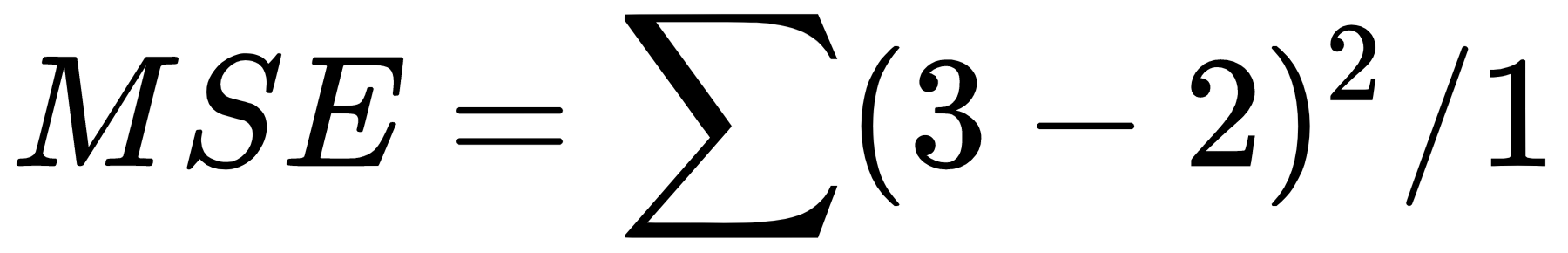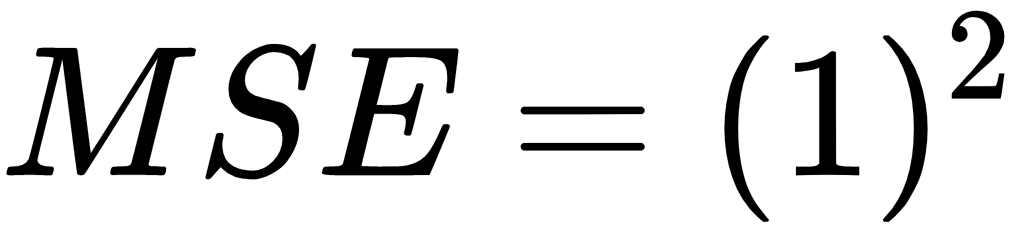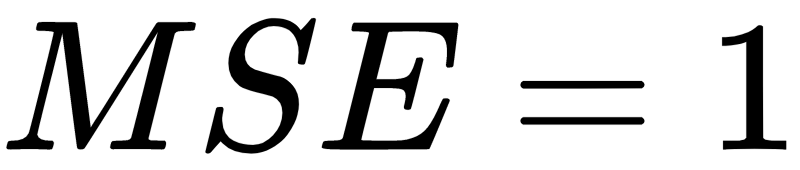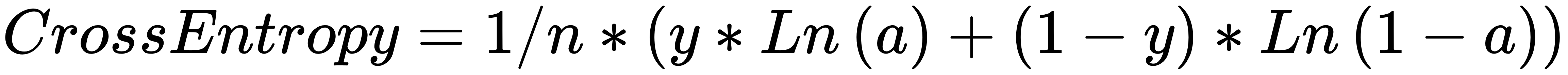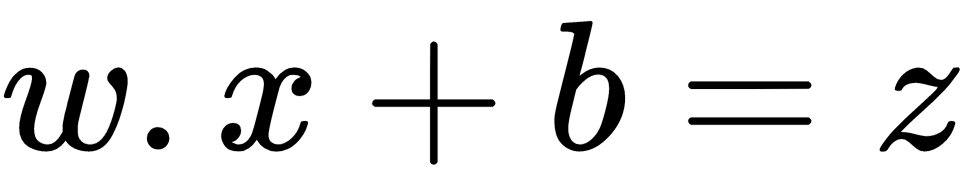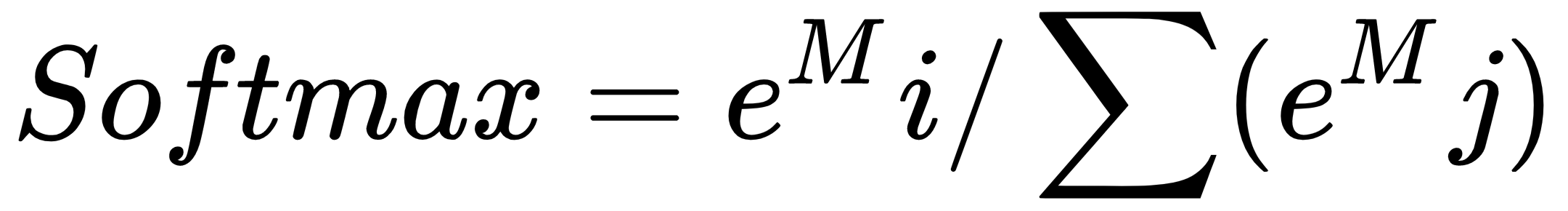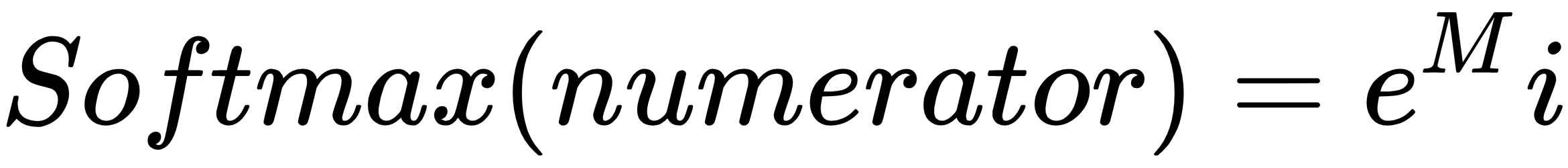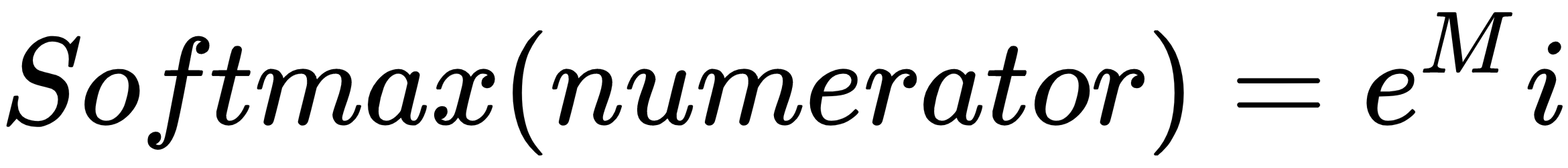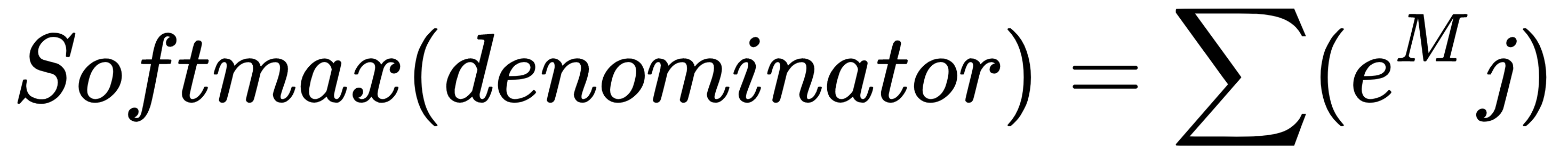We have reached our final conceptual topic for this chapter. We've covered types of neurons, cost functions, gradient descent, and finally a mechanism to apply gradient descent across the network, making it possible to learn over repeated iterations.
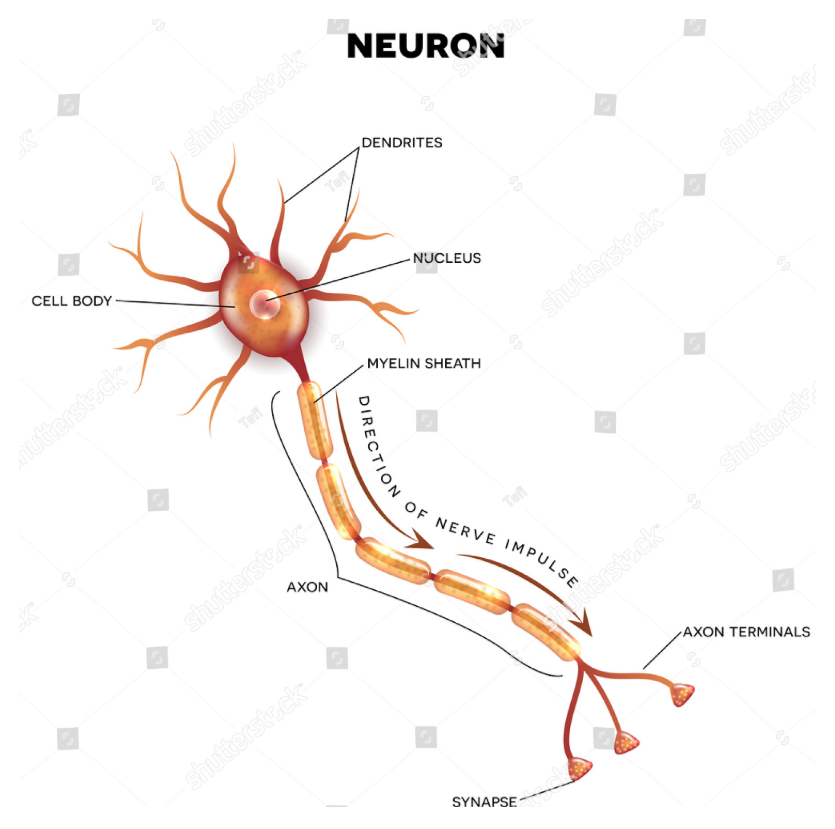
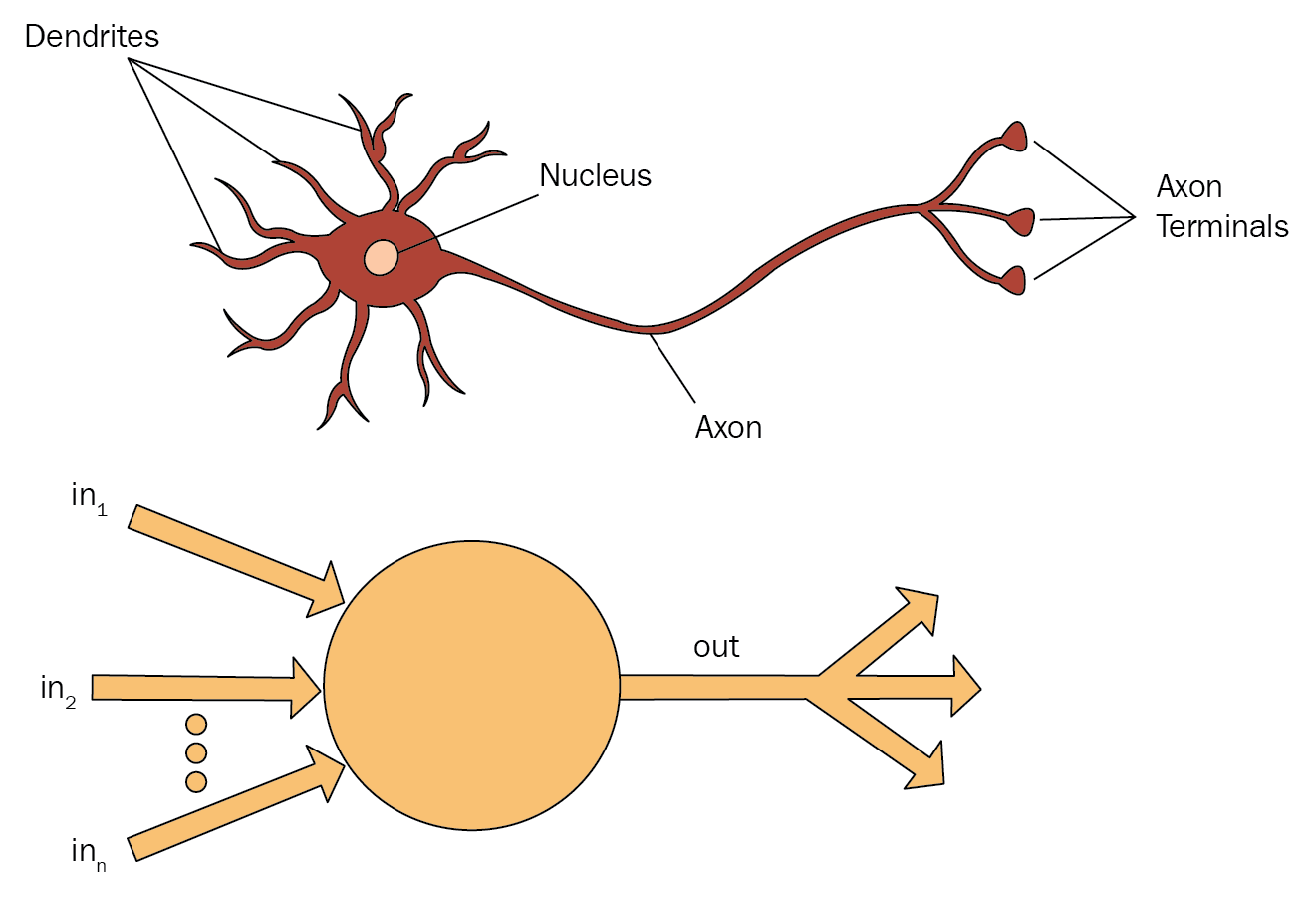
Previously, we saw the input layer and dense or hidden layers of an ANN:
Softmax is a special kind of neuron that's used in the output layer to describe the probability of the respective output:
To understand the softmax equation and its concepts, we will be using some code. Like before, for now, you can use any online Python editor to follow the code.
First, import the exponential methods from the math library:
from math import exp
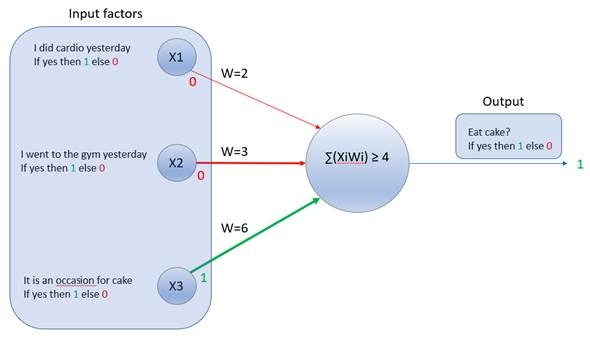
For the sake of this example, let's say that this network is designed to classify three possible labels: A, B, and C. Let's say that there are three signals going into the softmax from the previous layers (-1, 1, 5):
a=[-1.0,1.0,5.0]
The explanation is as follows:
- The first signal indicates that the output should be A, but is weak and is represented with a value of -1
- The second signal indicates that the output should be B and is slightly stronger and represented with a value of 1
- The third signal is the strongest, indicating that the output should be C and is represented with a value of 5
These represented values are confidence measures of what the expected output should be.
Now, let's take the numerator of the softmax for the first signal, guessing that the output is A:
Here, M is the output signal strength indicating that the output should be A:
exp(a[0]) # taking the first element of a[-1,1,5] which represents A
0.36787944117144233
Next, there's the numerator of the softmax for the second signal, guessing that the output is B:
Here, M is the output signal strength indicating that the output should be B:
exp(a[0]) # taking the second element of a[-1,1,5] which represents B
2.718281828459045
Finally, there's the numerator of the softmax for the second signal, guessing that the output is C:
Here, M is the output signal strength indicating that the output should be C:
exp(a[2])
# taking the third element of a[-1,1,5] which represents C
148.4131591025766
We can observe that the represented confidence values are always placed above 0 and that the resultant is made exponentially larger.
Now, let's interpret the denominator of the softmax function, which is a sum of the exponential of each signal value:
Let's write some code for softmax function:
sigma = exp ( a [ 0 ]) + exp ( a [ 1 ]) + exp ( a [ 2 ])
sigma
151.49932037220708
Therefore, the probability that the first signal is correct is as follows:
exp(a[0])/sigma
0.0024282580295913376
This is less than a 1% chance that it is A.
Similarly, the probability that the third signal is correct is as follows:
exp(a[2])/sigma
0.9796292071670795
This means there is over a 97% chance that the expected output is indeed C.
Essentially, the softmax accepts a weighted signal that indicates the confidence of some class prediction and outputs a probability score between 0 to 1 for all of those classes.
Great! We have made it through the essential high-level theory that's required to get us hands on with our projects. Next up, we will summarize our understanding of these concepts by exploring the TensorFlow Playground.
























































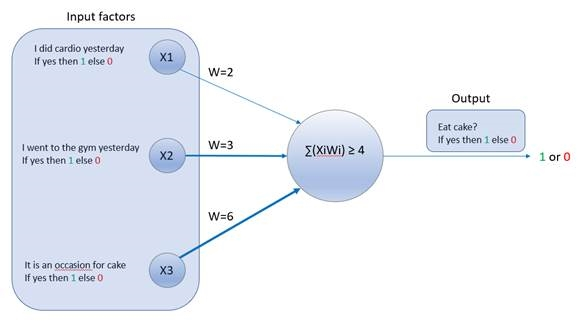
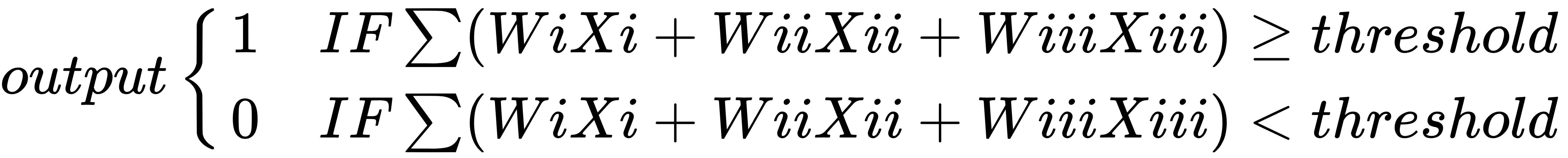
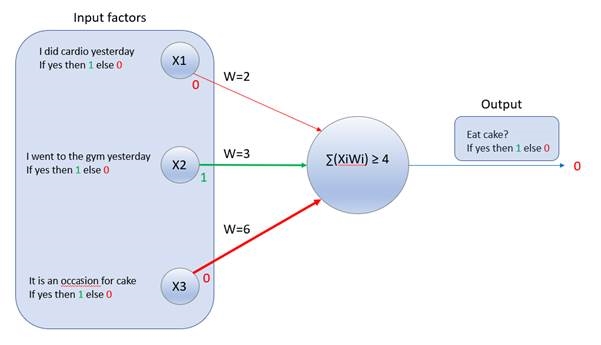
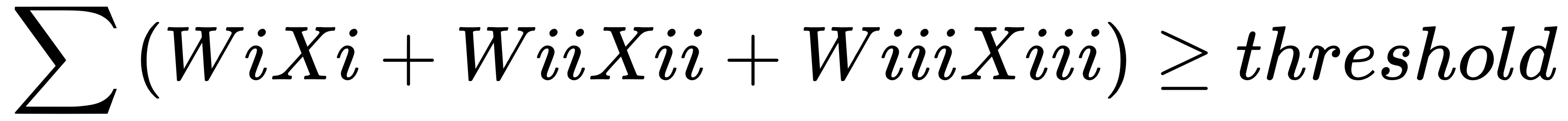
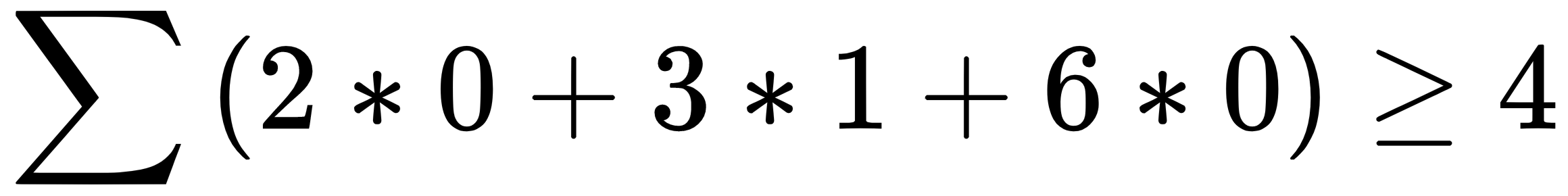
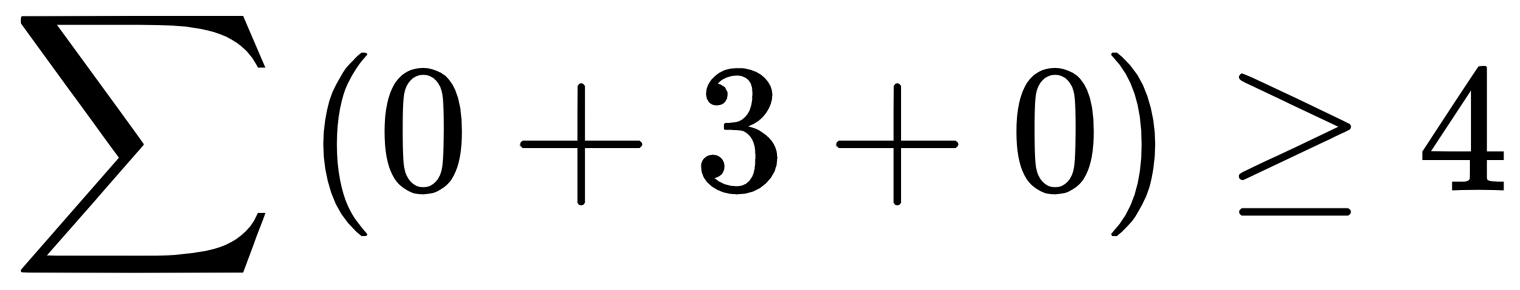
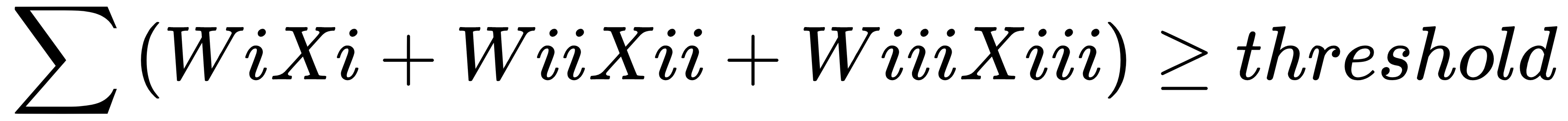
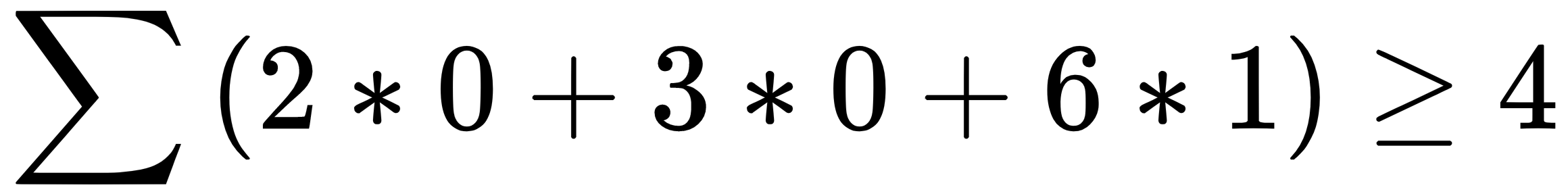
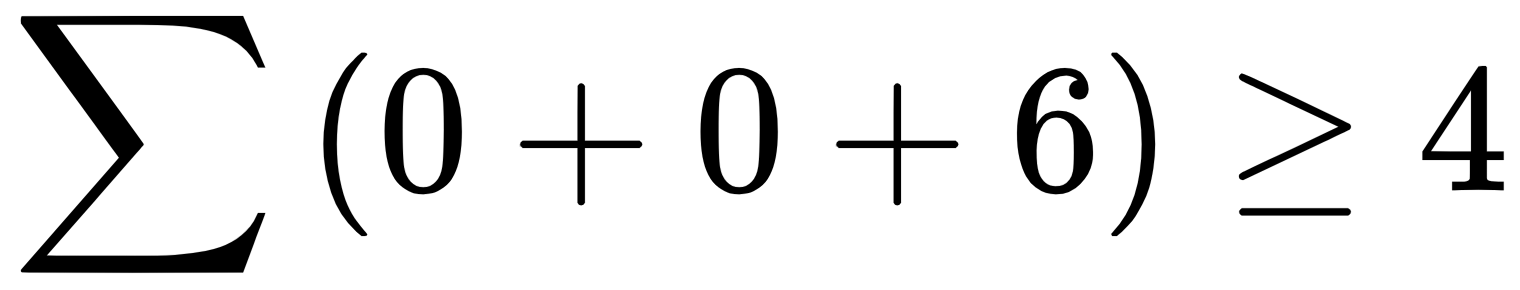
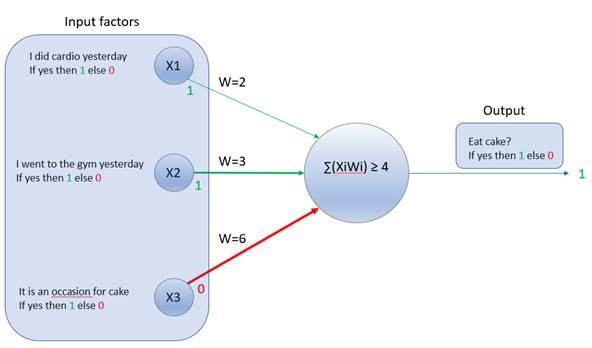
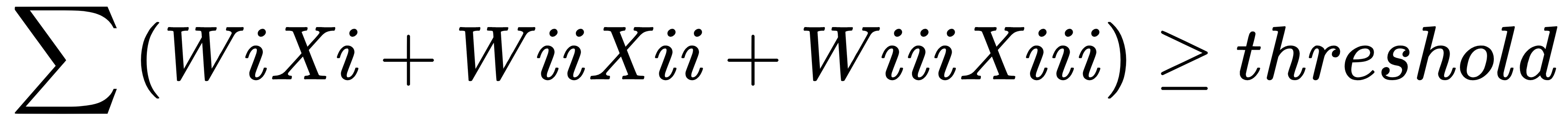
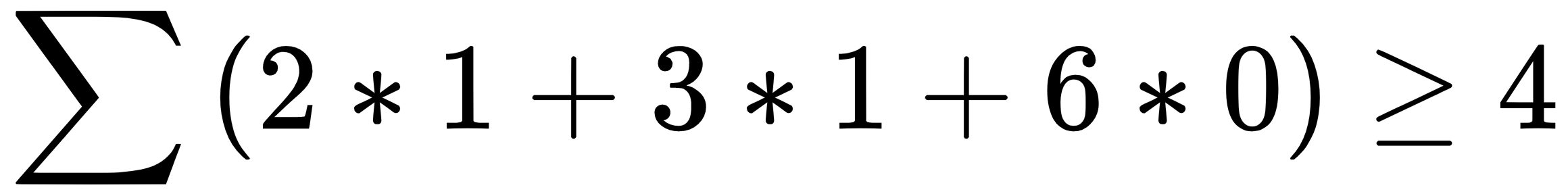
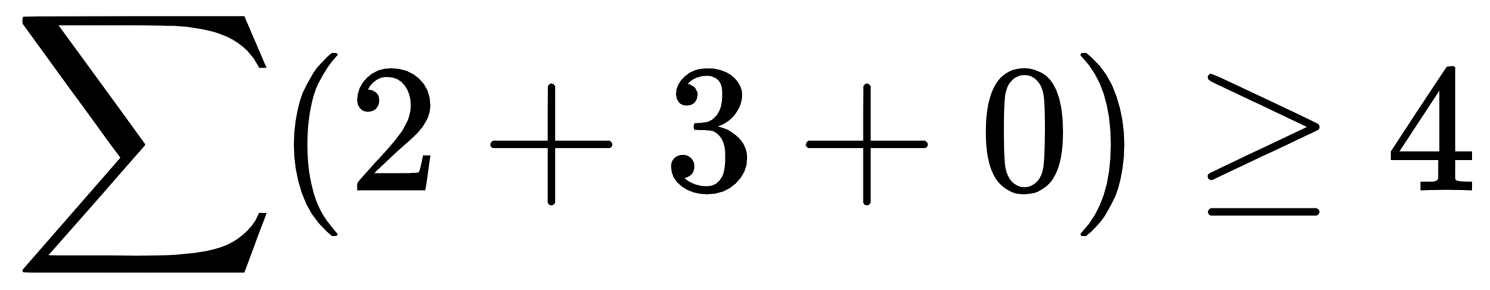
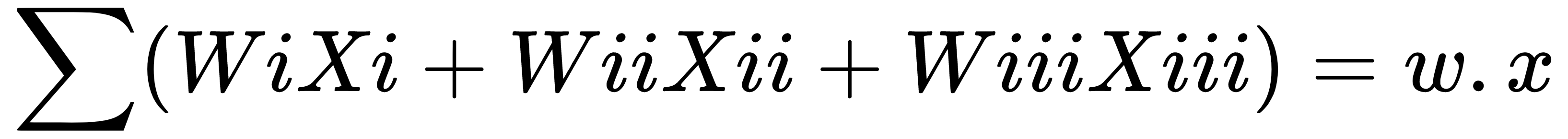
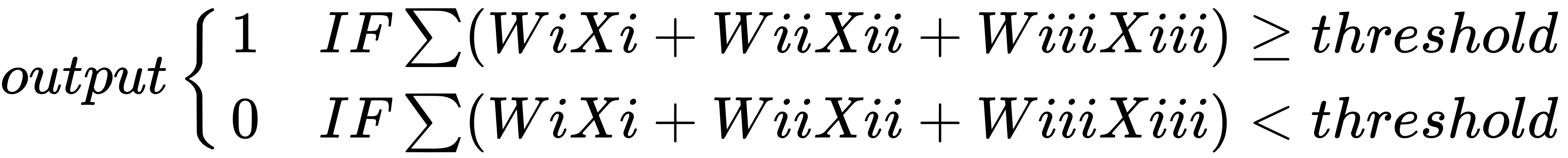
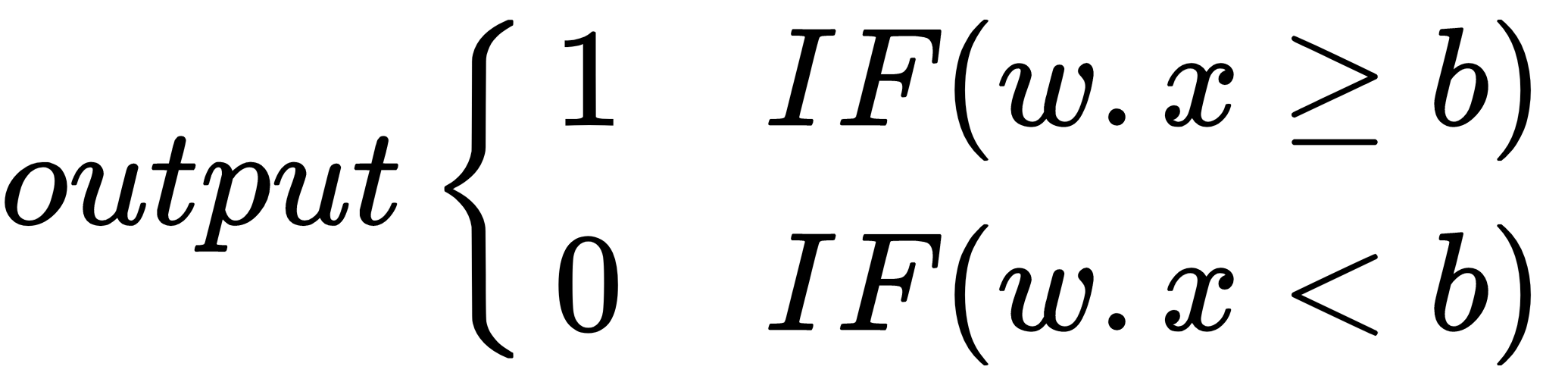
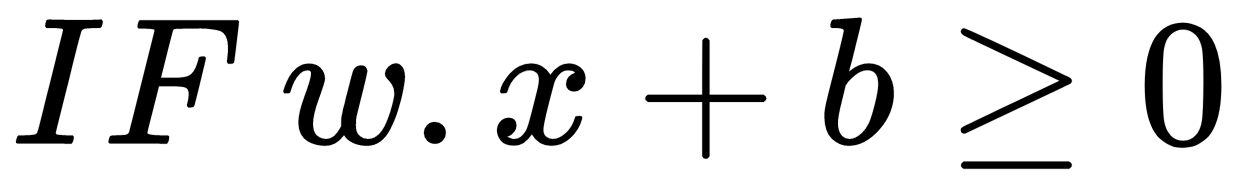 , then output
, then output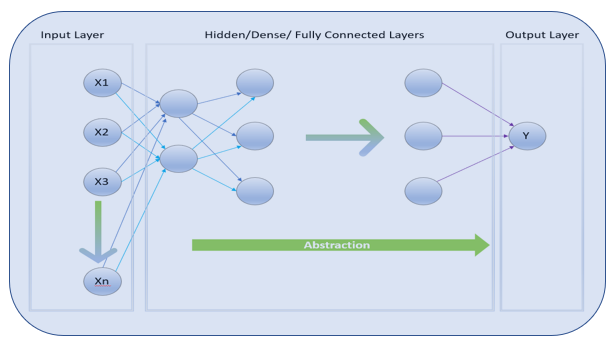
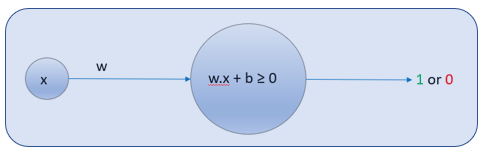
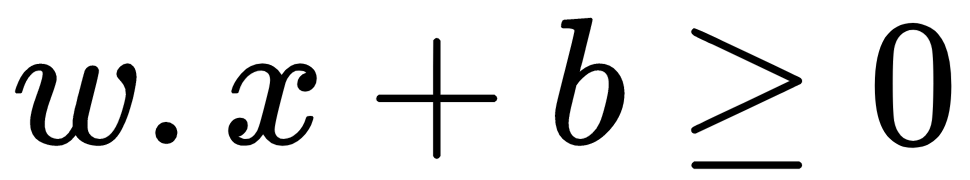 .
.
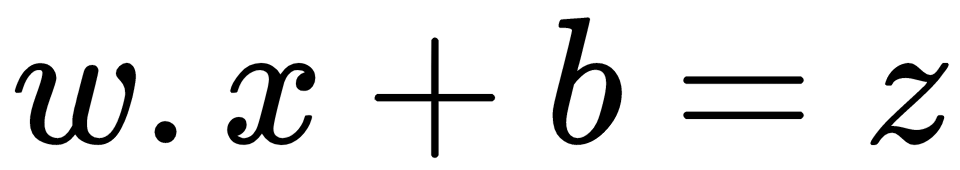
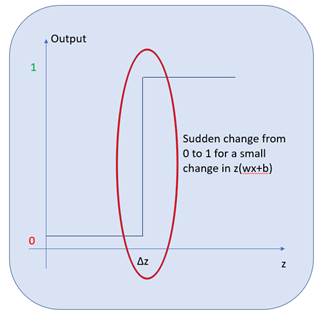
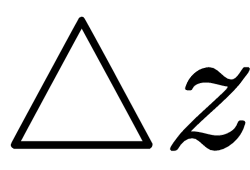 , we get a dramatic change in the output, a. This is not particularly helpful if the perceptron is part of a network, because if each perceptron has such drastic change, it makes the network unstable and hence the network fails to learn.
, we get a dramatic change in the output, a. This is not particularly helpful if the perceptron is part of a network, because if each perceptron has such drastic change, it makes the network unstable and hence the network fails to learn.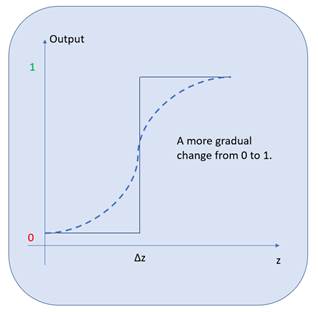
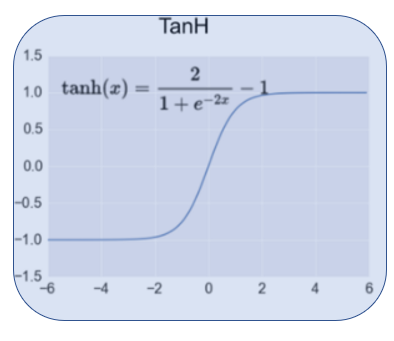
 . Activation functions can be looked at as transformation functions that are used to transform binary values in to a sequence of smaller values between a given minimum and maximum.
. Activation functions can be looked at as transformation functions that are used to transform binary values in to a sequence of smaller values between a given minimum and maximum.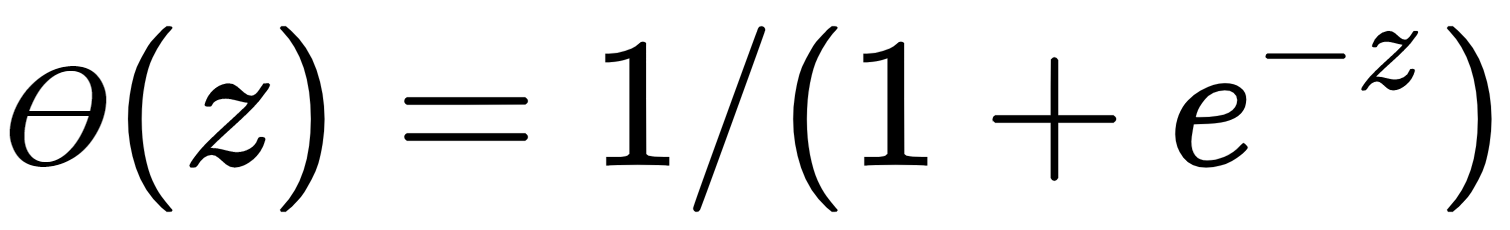
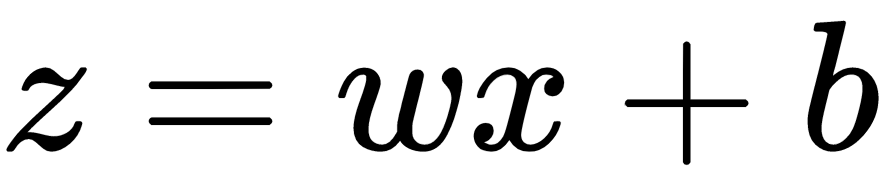 and
and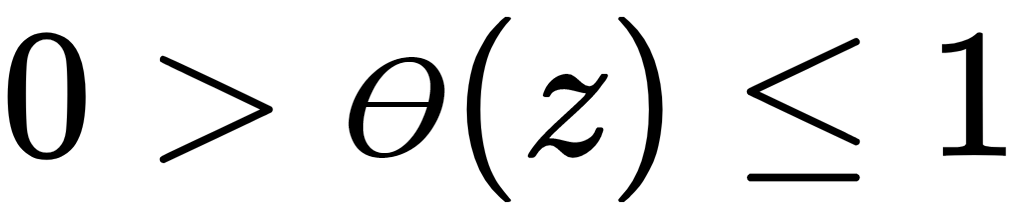 .
.
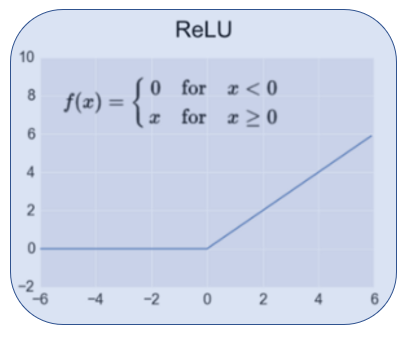
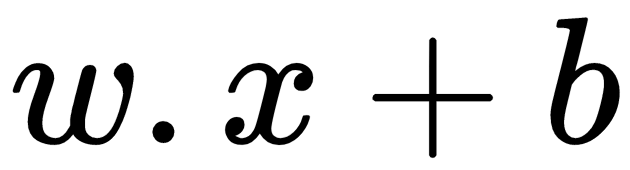 . Let's sum up these activation functions:
. Let's sum up these activation functions: