






















































The JIRA architecture
Installing JIRA is simple and straightforward. However, it is important for you to understand the components that make up the overall architecture of JIRA and the installation options available. This will help you make an informed decision and be better prepared for future maintenance and troubleshooting.
High-level architecture
Atlassian provides a comprehensive overview of the JIRA architecture at https://developer.atlassian.com/jiradev/jira-platform/jira-architecture/jira-technical-overview. However, for the day-to-day administration and usage of JIRA, we do not need to get into details; the information provided can be overwhelming at first glance. For this reason, we have summarized a high-level overview, which highlights the most important components in the architecture, as shown in the following figure:
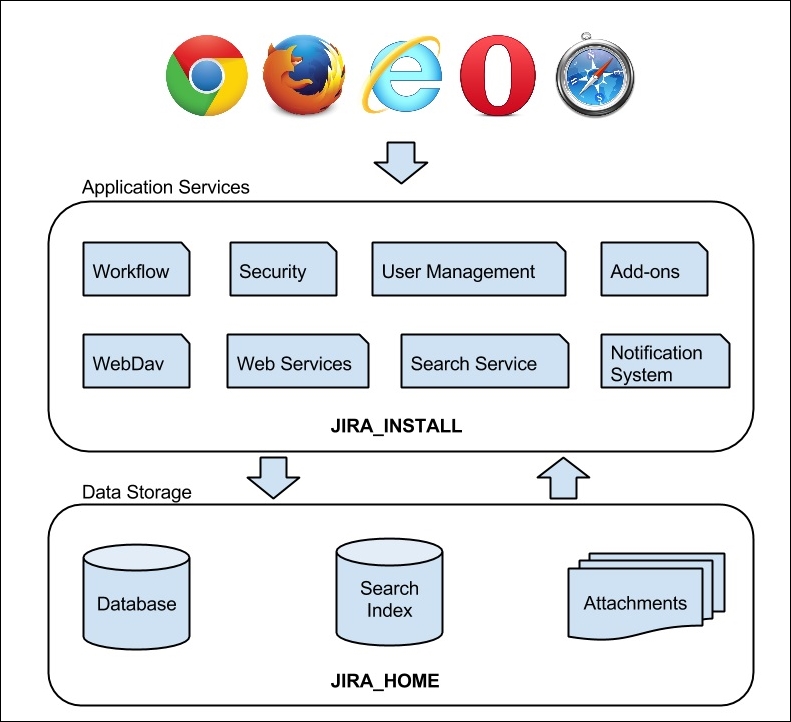
Web browsers
JIRA is a web application, so there is no need for users to install anything on their machines. All they need is a web browser that is compatible with JIRA. The following table summarizes the browser requirements for JIRA:
|
Browsers |
Compatibility |
|
Internet Explorer |
10.0, 11.0 |
|
Mozilla Firefox |
Latest stable versions |
|
Safari |
Latest stable versions on Mac OSX |
|
Google Chrome |
Latest stable versions |
|
Mobile |
Mobile Safari Mobile Chrome |
Application services
The application services layer contains all the functions and services provided by JIRA. These services include various business functions, such as workflow and notification, which will be discussed in depth in Chapter 6, Workflows and Business Processes and Chapter 7, E-mails and Notifications, respectively. Other services such as REST/Web Service provide integration points to other applications The OSGi service provides the base add-on framework to extend JIRA's functionalities.
Data storage
The data storage layer stores persistent data in several places within JIRA. Most business data, such as projects and issues, are stored in a relational database. Content such as uploaded attachments and search indexes are stored in the file system in the JIRA_HOME directory, which we will talk about in the next section. The underlying relational database used is transparent to users, and you can migrate from one database to another with ease, as referenced at https://confluence.atlassian.com/display/JIRA/Switching+Databases.
The JIRA installation directory
The JIRA installation directory is where you install JIRA. It contains all the executable and configuration files of the application. JIRA neither modifies the contents of the files in this directory during runtime, nor does it store any data files inside the directory. The directory is used primarily for execution. For the remainder of the book, we will refer to this directory as JIRA_INSTALL.
The JIRA home directory
The JIRA home directory contains key data and configuration files specific to each JIRA instance, such as JIRA's database connectivity details. As we will see later in this chapter, setting the path to this directory is part of the installation process.
There is a one-to-one relationship between JIRA and this directory. This means each JIRA instance must (and can) have only one home directory, and each directory can serve only one JIRA instance. In the old days, this directory was sometimes called the data directory. It has now been standardized as the JIRA Home. It is for this reason that, for the rest of the book, we will refer to this directory as JIRA_HOME.
The JIRA_HOME directory can be created anywhere on your system or even on a shared drive. It is recommended to use a fast disk drive with low network latency to get the best performance from JIRA.
This separation of data and application makes tasks such as maintenance and future upgrades an easier process. Within JIRA_HOME, there are several subdirectories that contain vital data, as shown in the following table:
|
Directory |
Description |
|
data |
This directory contains data that is not stored in the database, for example, uploaded attachment files. |
|
export |
This directory contains the automated backup archives created by JIRA. This is different from a manual export executed by a user; manual exports require the user to specify where to store the archive. |
|
import |
This directory contains the backups that can be imported. JIRA will only load backup files from this directory. |
|
log |
This directory contains JIRA log files, useful to track down errors. Some of the key log files include:
|
|
plugins |
This directory is where installed add-ons are stored. In the previous versions of JIRA, add-ons were installed by copying add-on files to this directory manually; however, in JIRA 7, you will no longer need to do this, unless specifically instructed to do so. Add-ons will be discussed further in later chapters. |
|
caches |
This directory contains cache data that JIRA uses to improve its performance at runtime. For example, search indexes are stored in this directory. |
|
tmp |
This directory contains temporary files created at runtime, such as file uploads. |
When JIRA is running, the JIRA_HOME directory is locked. When JIRA shuts down, it is unlocked. This locking mechanism prevents multiple JIRA instances from reading/writing to the same JIRA_HOME directory and causing data corruption.
JIRA locks the JIRA_HOME directory by writing a temporary file called jira-home.lock into the root of the directory. During the shutdown, this file will be removed. However, sometimes JIRA may fail to remove this file, such as during an ungraceful shutdown. In this case, you can manually remove this locked file to unlock the directory so that you can start up JIRA again.
Tip
You can manually remove the locked file to unlock the JIRA_HOME directory if JIRA fails to clean it up during the shutdown.










