






















































To better explain serverless computing, we will take a trip down memory lane and revisit the various paradigms used to host software, and the impact they have had on software design.
The evolution of serverless computing
On-premise
On-premise servers were one of the earliest paradigms, where the companies producing software had to not only deal with designing, architecting, and writing the code, but also had to execute and create a rainbow of auxiliary activities and elements, as follows:
- Budgeting, purchasing, and arranging for real estate to host servers
- Budgeting and purchasing of bare metal computational and networking hardware
- Installation of computational assets
- Equilibrium of environment
- Authoring code
- Configuration and provisioning of servers
- Deployment strategies
- Designing and implementing strategies for high availability of the applications.
- Backup and restore mechanisms
- Performance and scalability
- Patch management and uptime
The typical makeup of such a company had a less-than-optimal ratio of the development team to the overall headcount, vastly slowing down the delivery of its most valuable proposition, which was designing and shipping software.
It is obvious, looking at the scope of the preceding work, that such a setup and work environment posed a lot of hurdles to the growth of the organizations, and had a direct impact on their bottom-line.
Colocation providers
Next, colocation providers came on the scene, with a business model to take away some of the responsibilities and provide services for a fee. They took away the need for companies to purchase real estate and other peripheral assets, like HVAC, by renting out such services for a fee.
They offered a turnkey solution for customers to house their own computational, networking assets for a charge. The customers still had to budget, purchase assets, and forecast their capacity requirements, even while renting out real estate.
Things got slightly better and the organizations grew leaner, but there were still a lot of activities to be done and elements to be created while supporting software development. These included the following:
- Budgeting and purchasing of bare metal computational and networking hardware
- Configuration and provisioning of servers
- Authoring code
- Deployment strategies
- Designing and implementing strategies for high availability of the applications.
- Backup and restore mechanisms
- Performance and scalability
- Patch management and uptime
Virtualization and IaaS
The colocation model worked well until the early 2000s. Organizations had to deal with managing a bare metal infrastructure, including things like server racks and network switches. Due to the sporadic nature of the internet traffic, most of the assets and bandwidth were not utilized in an optimum fashion.
While all of this was considered business as usual, innovation gifted the world with platform virtualization. This enabled the bare metal racks to host more than one server instance in a shared hardware fashion, without compromising security and performance. This was a primary step toward the inception of cloud computing, spawning the pay-as-you-use paradigm, which was very attractive to organizations looking to bump up their bottom-lines.
Amazon launched Elastic Compute Cloud (EC2), which rented out virtualized computational hardware in the cloud, with bare minimum OS configurations and the flexibility to consume as many hardware and network resources as required. This took away the need for organizations to perform approximated capacity planning, and made sure that the infrastructure costs were a function of traction that a business was breaking. This paradigm is called Infrastructure as a Service (IaaS). It was widely adopted, and at a fast pace. The reduction in operational costs was the biggest driver behind its adoption.
At the same time, there were some activities that the company still had to undertake, as follows:
- Authoring code
- Configuration and provisioning of servers
- Deployment strategies
- Design of high availability
- Backup and restore mechanisms
- Performance and scalability
- Patch management and uptime
PaaS
The adoption of IaaS and cloud computing pushed innovation and churned out a paradigm called PaaS, or Platform as a Service. Leveraging the foundation set by IaaS, cloud providers started to abstract away services like load balancing, continuous integration and deployment, edge and traffic engineering, HA, and failover, into opinionated turnkey offerings. PaaS further reduced the responsibility spectrum of a company producing code to the following responsibilities:
- Architecting and designing systems
- Authoring code
- Maintenance and patch management
BaaS
PaaS enabled companies to focus solely on the backend and client application development. During this phase, applications and systems started to take a common shape. For example, almost every application requires a login, sign up, email, notifications, reporting, and so on.
Cloud providers leveraged this trend and started offering such common services as part of Backend as a Service, or BaaS. This enabled the companies to avoid reinventing the wheel, purchasing off-the-shelf products for common components. The management and uptime of such services are guaranteed as a part of Service Level Agreements (SLAs) by cloud providers.
Such an approach freed BaaS adopters up so that they could deliver rich and engaging user experiences, contributing to faster growth.
SaaS
Software as a Service (SaaS) is a special type of Software as a Service model, where companies purchase entire systems, whitelist them, and offer them as a part of the solution that they provide. For example, Intercom.io provides an in-app messaging solution that drives up customer support.
Adopters and customers offload parts of their systems to specialized providers, who excel at offering such solutions to build it in-house.
FaaS
For all of the benefits that BaaS and SaaS provide, companies still have to incorporate bespoke feedback into products, and they often feel the need to retain control of some of the business logic that comprises the backend.
This control and flexibility doesn't have to be achieved at the cost of the benefits of BaaS, SaaS, and PaaS. Companies, having tasted the benefits of such big strides in infrastructure management don't want to add costs to managing and maintaining hardware, whether bare metal or in the cloud.
This is where a new paradigm, Function as a Service (FaaS), has evolved to fill the gap.
Function as a Service is a paradigm wherein a function is a computation unit and building block of backend services. Formally, a function is a computation that takes some input and produces some output. At times, it produces side effects and modifies state out of its memory, and at times, it doesn't.
What's true in both of the cases is that a function should be called, its temporal execution boundary should be defined (that is, it should run in a time-boxed manner), and it should produce output that is consumable by downstream components, or available for perusal at a later time.
If one was to architect their backend service code along these lines, they would end up with an ephemeral computational unit that gets called or triggered to do its job by an upstream stimulus, performs the computation/processing, and returns or stores the output. In all of this execution, one is not worried about the environment that the function runs in. All one needs, in such a scenario, is code (or a function) that is guaranteed to perform the desired calculation in a determined time.
The runtime for the code, the upstream stimulus, and the downstream chaining, should be taken care of by the entity that provides such an environment. Such an entity is called a serverless computing provider, and the paradigm is called Function as a Service, or Serverless Computing.
The advantages of such an architecture, along with the benefits of BaaS and SaaS, are as follows:
- Flexibility and control
- The ability to deliver the discrete and atomic components of the system
- Faster time to market
Serverless computing
Serverless paradigms started as FaaS, but have grown, and are beginning to encompass BaaS offerings as well. As described previously, this is an ever-changing landscape, and the two concepts of FaaS and BaaS are coalescing into one, called serverless computing. As it stands today, the distinction is blurring, and it's difficult to say that serverless is pure FaaS. This is an important point to note.
To create modern serverless apps, FaaS is necessary, but not sufficient.
For example, a production-grade service that can crunch numbers in isolation can be created by using only FaaS. But a system that has user-facing components requires much more than a simple, ephemeral computational component.
Serverless – the time is now
In the past decade or so, investments in hardware and innovations in the tools that optimize hardware have paid off. Hardware has become a commodity. The era of expensive computational assets is long gone. With the advent and adoption of virtualization, renting hardware is a walk in the park, and is often the only option for companies that do not have the resources or inclination to bootstrap an on-premise infrastructure.
With the sky being the limit for current hardware capabilities, the onus is on software to catch up and leverage this. Serverless is the latest checkpoint in this evolution. Commoditized hardware and rapidly commoditizing allied software tooling enables companies to further reduce their operational costs and make a direct impact on their bottom-line. The question is not really whether companies will adopt the serverless paradigm, but when.
This revolution is happening now, and it is here to stay. The time is now for serverless!
Diving into serverless computing with a use case
In this section, we'll how a real-life serverless application looks. First, we will review what we have seen before, and we will then try to slice and dice a traditional system into one that fits the serverless paradigm.
A review of serverless computing
In the previous sections, we touched upon the basics of the serverless paradigm and saw how systems in production evolved to arrive at this point.
To recap, the serverless architecture started as Function as a Service, but has grown to be much more than just ephemeral computational units.
Serverless abstracts away the humdrum but critical (scalability, maintenance, and so on) and functional but standard (email, notifications, logging, and so on) pieces of your system, into a flexible offering that can be consumed on demand. This is like a case of build versus buy, where a decision to buy is made, but at a fraction of the upfront cost.
Comparing and contrasting traditional and serverless paradigms
It's worthwhile to compare and contrast the traditional and serverless paradigms of building systems using a case study.
The case study of an application
Let's assume that we are a services company that builds software for our clients. We get contracted to build an opinion poll system on the current state of technology. Users can only log in to this system using their Facebook credentials. Users can create polls that other users can participate in. They can also invite people to participate in the polls that they have created. Finally, they can see the outcomes of their polls.
This system has to be audited and monitored, and should be readily scalable. The functionality of the system has to be exposed via a mobile app.
The functional requirements are as follows:
- As a user, I should be able to sign in to the application using my Facebook credentials
- As a user, I should be able to create a poll of my choice
- As a user, I should be able to invite people to participate in my polls
- As a user, I should be able to participate in the polls
- As a user, I should be able to check the results of my polls
The non-functional requirements are as follows:
- As a system, I should be able to keep track of all activities performed by all users
- As a system, I should be able to scale horizontally and transparently
- As a system, I should be able to be monitored, and deviations from standard operations should be reported back
The architecture of the system using traditional methods
The following diagram shows how the system would look if it was created and developed in the traditional way:
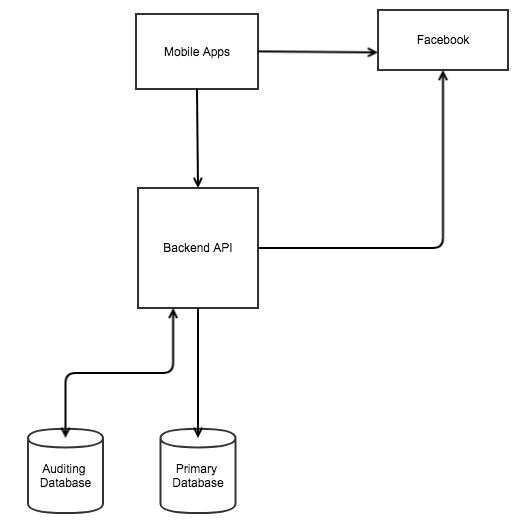
At a high level, the preceding diagram shows the moving parts of the system, as follows:
- Mobile app
- Backend APIs, consisting of the following modules:
- Social sign-in module
- Opinion poll module
- Logging module
- Notification module
- Reporting module
- Facebook as an identity provider (iDP)
- Primary database
- Auditing database
In this setup, we are responsible for the following:
- Development of all of the backend API modules, like polling, notification, logging, auditing, and so on
- Deployment of all backend API modules
- Design and development of the mobile app
- Management of the databases
- Scalability
- High availability
In production, such a topology would almost definitely require two servers each for high availability for the primary database, auditing database, and backend APIs.
In addition to the preceding topology, we would require the following (or equivalent) toolchain, required for all of the preceding non-functional requirements:
- Nagios, for monitoring
- Pagerduty, for notifications
- Jenkins, for CI
- Puppet, for configuration management
This traditional architecture, though proven, has significant drawbacks, as follows:
- Monolithic structure.
- Single point of failure of backend APIs. For example, if the API layer goes down due to a memory leak in the reporting module, the entire system becomes unavailable. It affects the more business-critical portions of the system, like the polling module.
- The reinvention of the wheel, rewriting standard notification services like email, SMS, and log aggregation.
- Dedicated hardware to cater to the SLAs of HA and uptime.
- Dedicated backup and restore mechanisms.
- The overhead of deploying teams for maintenance.
The architecture of the system using the serverless paradigm
The following diagram shows how the system would look if the serverless paradigm was used:

Its salient features are as follows:
- The primary RDBMS has been replaced by an AWS RDS (AWS Relational Database Service). RDS takes care of provisioning, patching, scaling, backing up, and restoring mechanisms for us. All we have to do is design the DB schema.
- The social sign-in module is replaced by AWS Cognito, which helps us to leverage Facebook (or any well-known social network). Using this, we can implement AuthN and AuthZ modules in our system in a matter of minutes.
- The notification modules have been replaced by AWS Simple Email Service (SES) and AWS Simple Notification Service (SNS), which offer turnkey solutions to implement the notification functionality in our system.
- The auditing DB has been replaced with the AWS ElasticSearch service and AWS CloudWatch in order to implement a log aggregation solution.
- The reporting and analysis module can be substituted with AWS Quicksight, which offers analysis and data visualization services.
- The core business logic is extracted into AWS Lambda functions, which can be configured to execute various events in the system.
- The maintenance of the system is managed by AWS, and load scaling is handled transparently.
- Monitoring of the system can be implemented by leveraging AWS CloudWatch and AWS SNS.
This architecture also enables us to develop our system in a micro-service based pattern, where there is an inherent failure tolerance due to highly cohesive and less coupled components, unlike with the traditional monolithic approach. The overhead for management is also reduced, and the costs come down drastically, as we are only charged for the resources we consume. Aside from this, we can focus on our core value proposition, that is, to design, develop, and deliver a cutting edge user experience.
Thus, we can clearly observe that serverless doesn't only mean ephemeral Functions as a Service, but includes mechanisms that deal with the implementation of peripheral (auditing and logging) and mission-critical (social identity management) components as turnkey solutions.
Traditional versus serverless, in a nutshell
The following table compares and contrasts the traditional and serverless ways of developing and deploying applications:
| Parameter | Traditional | Serverless |
| Architectural style | Monolithic, SOA | Microservices-based |
| Time to market | Slower | Quicker time to market |
| Development velocity | Slow | Fast |
| Focus on core value proposition | Diffused | Laser focused |
| Infrastructure management overhead cost | High | Low |
| Deployment of code | Complex tooling | Simple as an upload of .zip or .tar.gz |
| Operational efficiency | Low | High |









