






















































Trust region policy optimization
TRPO is one of the most popularly used algorithms in deep reinforcement learning. TRPO is a policy gradient algorithm and it acts as an improvement to the policy gradient with baseline method we learned in Chapter 10, Policy Gradient Method. We learned that policy gradient is an on-policy method, meaning that on every iteration, we improve the same policy with which we are generating trajectories. On every iteration, we update the parameter of our network and try to find the improved policy. The update rule for updating the parameter  of our network is given as follows:
of our network is given as follows:

Where 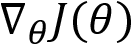 is the gradient and
is the gradient and  is known as the step size or learning rate. If the step size is large then there will be a large policy update, and if it is small then there will be a small update in the policy. How can we find an optimal step size? In the policy gradient method, we keep the step size small and so on every iteration there will be a small improvement in the...
is known as the step size or learning rate. If the step size is large then there will be a large policy update, and if it is small then there will be a small update in the policy. How can we find an optimal step size? In the policy gradient method, we keep the step size small and so on every iteration there will be a small improvement in the...




