






















































Cluster architecture and components
Kubernetes is a portable, highly extensible, open source orchestration that facilitates managing containerized workloads and services and orchestrates your containers to achieve the desired status across different worker nodes. It is worth mentioning that official documentation states that Kubernetes means pilot in Greek where its name originates from, which is appropriate for its function.
It supports a variety of workloads, such as stateless, stateful, and data-processing workloads. Theoretically, any application that can be containerized can be up and running on Kubernetes.
A Kubernetes cluster consists of a set of worker nodes; those worker machines run the actual workloads that are the containerized applications. A Kubernetes cluster can have from 1 up to 5,000 nodes (as of writing this chapter, we’re on the Kubernetes 1.23 version).
We usually spin up one node for quick testing, whereas, in production environments, a cluster has multiple worker nodes for high availability and fault torrent.
Kubernetes adopts a master/worker architecture, which is a mechanism where one process acts as the master component to control one or more other components called slaves, or in our case, worker nodes. A general Kubernetes cluster architecture would look like the following:
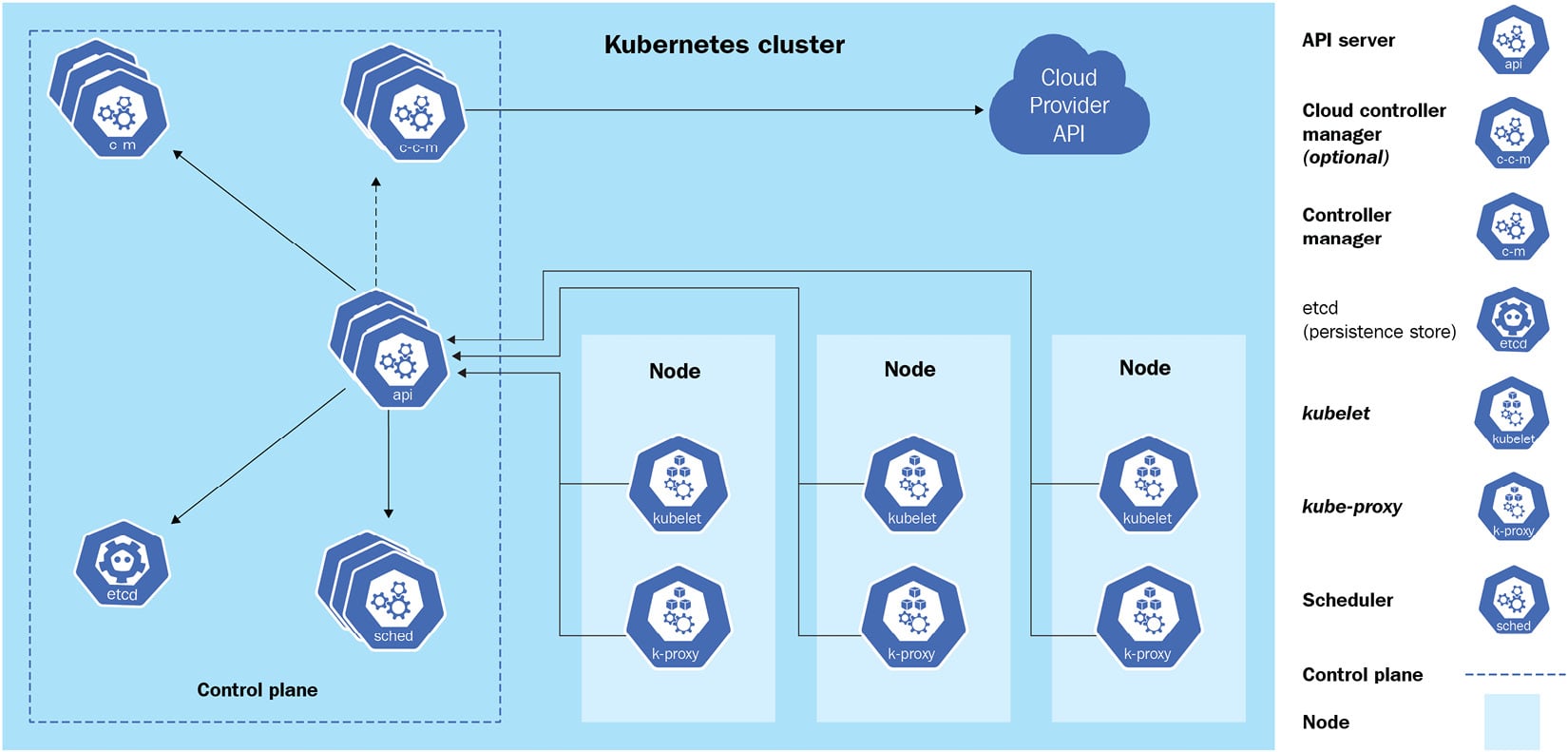
Figure 1.1 – Kubernetes cluster architecture
The Kubernetes master node, or the control plane, is in charge of responding to the cluster events, and it contains the following components:
- API server: This is the core of the Kubernetes control plane. The main implementation of the API server, also known as
kube-apiserver, is to expose the Kubernetes REST API. You can see it as a communication manager between different Kubernetes components across the Kubernetes cluster. - etcd: This is a distributed key-value store that stores information regarding the cluster information and all states of objects running on the Kubernetes cluster, such as Kubernetes cluster nodes, Pods, config maps, secrets, service accounts, roles, and bindings.
- Kubernetes scheduler: A Kubernetes scheduler is a part of the control plane. It is responsible for scheduling Pods to the nodes.
kube-scheduleris the default scheduler for Kubernetes. You can imagine it as a postal officer who sends the Pod’s information to each node and when it arrives at the target node, thekubeletagent on that node will provide the actual containerized workloads with the received specification. - Controllers: Controllers are responsible for running Kubernetes toward the desired states. A set of built-in controllers runs inside
kube-controller-managerin Kubernetes. Examples of those controllers are replication controllers, endpoint controllers, and namespace controllers.
Besides the control plane, every worker node in a Kubernetes cluster running the actual workloads has the following components:
- kubelet: A kubelet is an agent that runs on each worker node. It accepts pod specifications sent from the API server or locally (for static pod) and provisions the containerized workloads such as the Pod, StatefulSet, and ReplicaSet on the respective nodes.
- Container runtime: This is the software virtualization layer that helps run containers within the Pods on each node. Docker, CRI-O, and containerd are examples of common container runtimes working with Kubernetes.
- kube-proxy: This runs on each worker node and implements the network rules and traffic forwarding when a service object is deployed in the Kubernetes cluster.
Knowing about those components and how they work will help you understand the core Kubernetes core concepts.










