






















































Hash tables
Let's start with the first data structure, which is a hash table, also known as a hash map. It allows mapping keys to particular values, as shown in the following diagram:
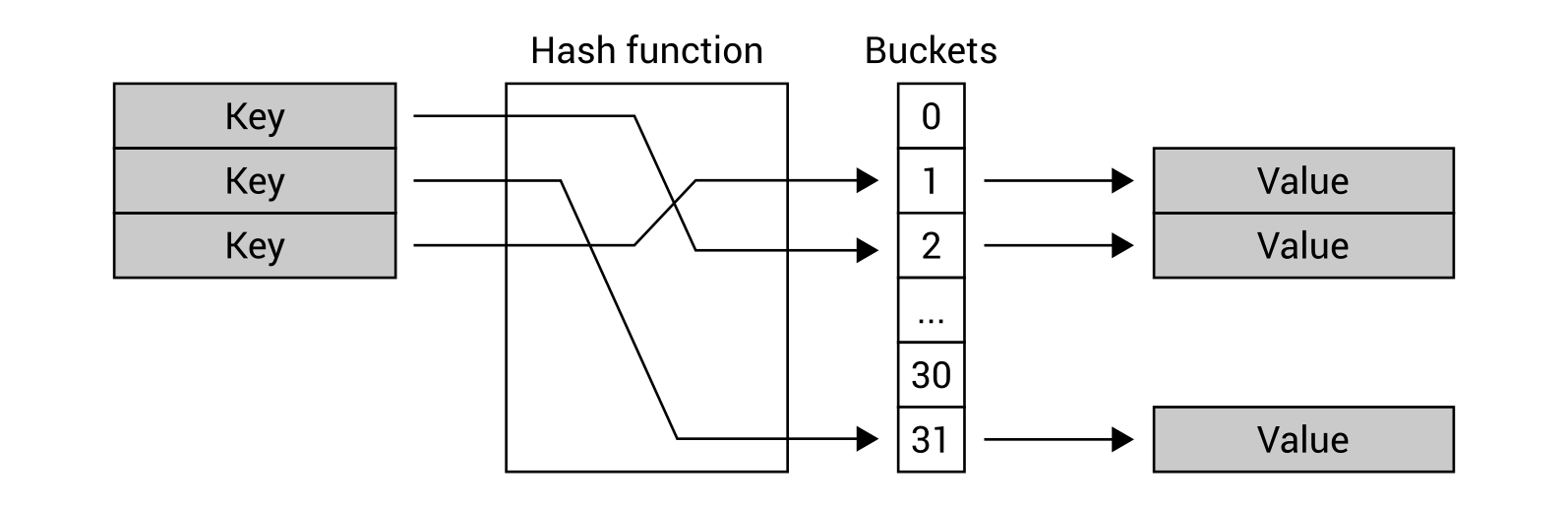
One of the most important assumptions of the hash table is the possibility of very fast lookup for a Value based on the Key, which should be the O(1) operation. To achieve this goal, the Hash function is used. It takes the Key to generate an index of a bucket, where the Value can be found.
For this reason, if you need to find a value of the key, you do not need to iterate through all items in the collection, because you can just use the hash function to easily locate a proper bucket and get the value. Due to the great performance of the hash table, such a data structure is frequently used in many real-world applications, such as for associative arrays, database indices, or cache systems.
As you can see, the role of the hash function is critical and ideally it should generate a unique result for all keys. However...





