






















































The Markov property is widely used in RL, and it states that the environment's response at time t+1 depends only on the state and action at time t. In other words, the immediate future only depends on the present and not on the past. This is a useful property that simplifies the math considerably, and is widely used in many fields such as RL and robotics.
Consider a system that transitions from state s0 to s1 by taking an action a0 and receiving a reward r1, and thereafter from s1 to s2 taking action a1, and so on until time t. If the probability of being in a state s' at time t+1 can be represented mathematically as in the following function, then the system is said to follow the Markov property:

Note that the probability of being in state st+1 depends only on st and at and not on the past. An environment that satisfies the following state transition property and reward function as follows is said to be a Markov Decision Process (MDP):
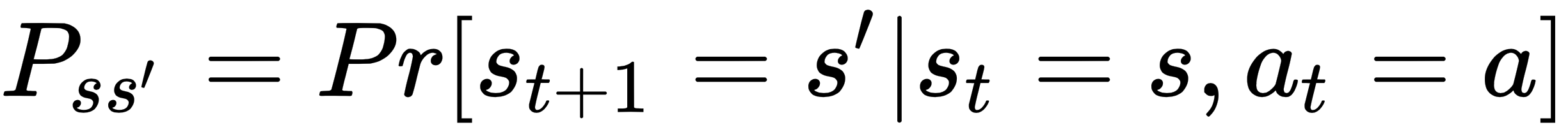
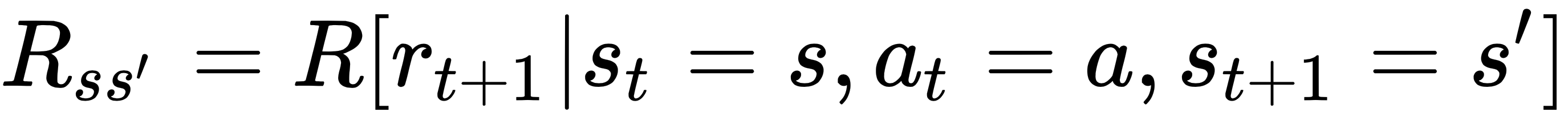
Let's now define the very foundation of RL: the Bellman equation. This equation will help in providing an iterative solution to obtaining value functions.



