























































The reactor pattern
In this section, we will analyze the reactor pattern, which is the heart of the Node.js asynchronous nature. We will go through the main concepts behind the pattern, such as the single-threaded architecture and the non-blocking I/O, and we will see how this creates the foundation for the entire Node.js platform.
I/O is slow
I/O is definitely the slowest among the fundamental operations of a computer. Accessing the RAM is in the order of nanoseconds (10e-9 seconds), while accessing data on the disk or the network is in the order of milliseconds (10e-3 seconds). For the bandwidth, it is the same story; RAM has a transfer rate consistently in the order of GB/s, while disk and network varies from MB/s to, optimistically, GB/s. I/O is usually not expensive in terms of CPU, but it adds a delay between the moment the request is sent and the moment the operation completes. On top of that, we also have to consider the human factor; often, the input of an application comes from a real person, for example, the click of a button or a message sent in a real-time chat application, so the speed and frequency of I/O don't depend only on technical aspects, and they can be many orders of magnitude slower than the disk or network.
Blocking I/O
In traditional blocking I/O programming, the function call corresponding to an I/O request will block the execution of the thread until the operation completes. This can go from a few milliseconds, in case of a disk access, to minutes or even more, in case the data is generated from user actions, such as pressing a key. The following pseudocode shows a typical blocking read performed against a socket:
//blocks the thread until the data is available data = socket.read(); //data is available print(data);
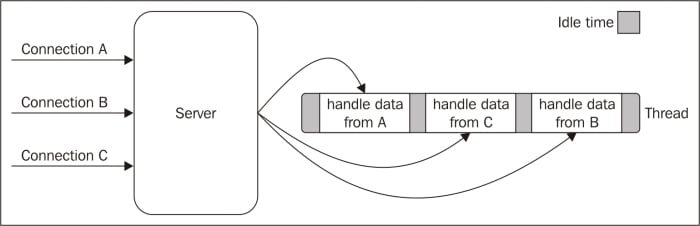
It is trivial to notice that a web server that is implemented using blocking I/O will not be able to handle multiple connections in the same thread; each I/O operation on a socket will block the processing of any other connection. For this reason, the traditional approach to handle concurrency in web servers is to kick off a thread or a process (or to reuse one taken from a pool) for each concurrent connection that needs to be handled. This way, when a thread blocks for an I/O operation it will not impact the availability of the other requests, because they are handled in separate threads.
The following image illustrates this scenario:

The preceding image lays emphasis on the amount of time each thread is idle, waiting for new data to be received from the associated connection. Now, if we also consider that any type of I/O can possibly block a request, for example, while interacting with databases or with the filesystem, we soon realize how many times a thread has to block in order to wait for the result of an I/O operation. Unfortunately, a thread is not cheap in terms of system resources, it consumes memory and causes context switches, so having a long running thread for each connection and not using it for most of the time, is not the best compromise in terms of efficiency.
Non-blocking I/O
In addition to blocking I/O, most modern operating systems support another mechanism to access resources, called non-blocking I/O. In this operating mode, the system call always returns immediately without waiting for the data to be read or written. If no results are available at the moment of the call, the function will simply return a predefined constant, indicating that there is no data available to return at that moment.
For example, in Unix operating systems, the fcntl() function is used to manipulate an existing file descriptor to change its operating mode to non-blocking (with the O_NONBLOCK flag). Once the resource is in non-blocking mode, any read operation will fail with a return code, EAGAIN, in case the resource doesn't have any data ready to be read.
The most basic pattern for accessing this kind of non-blocking I/O is to actively poll the resource within a loop until some actual data is returned; this is called busy-waiting. The following pseudocode shows you how it's possible to read from multiple resources using non-blocking I/O and a polling loop:
resources = [socketA, socketB, pipeA];
while(!resources.isEmpty()) {
for(i = 0; i < resources.length; i++) {
resource = resources[i];
//try to read
var data = resource.read();
if(data === NO_DATA_AVAILABLE)
//there is no data to read at the moment
continue;
if(data === RESOURCE_CLOSED)
//the resource was closed, remove it from the list
resources.remove(i);
else
//some data was received, process it
consumeData(data);
}
}You can see that, with this simple technique, it is already possible to handle different resources in the same thread, but it's still not efficient. In fact, in the preceding example, the loop will consume precious CPU only for iterating over resources that are unavailable most of the time. Polling algorithms usually result in a huge amount of wasted CPU time.
Event demultiplexing
Busy-waiting is definitely not an ideal technique for processing non-blocking resources, but luckily, most modern operating systems provide a native mechanism to handle concurrent, non-blocking resources in an efficient way; this mechanism is called synchronous event demultiplexer or event notification interface. This component collects and queues I/O events that come from a set of watched resources, and block until new events are available to process. The following is the pseudocode of an algorithm that uses a generic synchronous event demultiplexer to read from two different resources:
socketA, pipeB;
watchedList.add(socketA, FOR_READ); //[1]
watchedList.add(pipeB, FOR_READ);
while(events = demultiplexer.watch(watchedList)) { //[2]
//event loop
foreach(event in events) { //[3]
//This read will never block and will always return data
data = event.resource.read();
if(data === RESOURCE_CLOSED)
//the resource was closed, remove it from the watched list
demultiplexer.unwatch(event.resource);
else
//some actual data was received, process it
consumeData(data);
}
}These are the important steps of the preceding pseudocode:
The resources are added to a data structure, associating each one of them with a specific operation, in our example a read.
The event notifier is set up with the group of resources to be watched. This call is synchronous and blocks until any of the watched resources is ready for a read. When this occurs, the event demultiplexer returns from the call and a new set of events is available to be processed.
Each event returned by the event demultiplexer is processed. At this point, the resource associated with each event is guaranteed to be ready to read and to not block during the operation. When all the events are processed, the flow will block again on the event demultiplexer until new events are again available to be processed. This is called the event loop.
It's interesting to see that with this pattern, we can now handle several I/O operations inside a single thread, without using a busy-waiting technique. The following image shows us how a web server would be able to handle multiple connections using a synchronous event demultiplexer and a single thread:
The previous image helps us understand how concurrency works in a single-threaded application using a synchronous event demultiplexer and non-blocking I/O. We can see that using only one thread does not impair our ability to run multiple I/O bound tasks concurrently. The tasks are spread over time, instead of being spread across multiple threads. This has the clear advantage of minimizing the total idle time of the thread, as clearly shown in the image. This is not the only reason for choosing this model. To have only a single thread, in fact, also has a beneficial impact on the way programmers approach concurrency in general. Throughout the book, we will see how the absence of in-process race conditions and multiple threads to synchronize, allows us to use much simpler concurrency strategies.
In the next chapter, we will have the opportunity to talk more about the concurrency model of Node.js.
The reactor pattern
We can now introduce the reactor pattern, which is a specialization of the algorithm presented in the previous section. The main idea behind it is to have a handler (which in Node.js is represented by a callback function) associated with each I/O operation, which will be invoked as soon as an event is produced and processed by the event loop. The structure of the reactor pattern is shown in the following image:

This is what happens in an application using the reactor pattern:
The application generates a new I/O operation by submitting a request to the Event Demultiplexer. The application also specifies a handler, which will be invoked when the operation completes. Submitting a new request to the Event Demultiplexer is a non-blocking call and it immediately returns the control back to the application.
When a set of I/O operations completes, the Event Demultiplexer pushes the new events into the Event Queue.
At this point, the Event Loop iterates over the items of the Event Queue.
For each event, the associated handler is invoked.
The handler, which is part of the application code, will give back the control to the Event Loop when its execution completes (5a). However, new asynchronous operations might be requested during the execution of the handler (5b), causing new operations to be inserted in the Event Demultiplexer (1), before the control is given back to the Event Loop.
When all the items in the Event Queue are processed, the loop will block again on the Event Demultiplexer which will then trigger another cycle.
The asynchronous behavior is now clear: the application expresses the interest to access a resource at one point in time (without blocking) and provides a handler, which will then be invoked at another point in time when the operation completes.
Note
A Node.js application will exit automatically when there are no more pending operations in the Event Demultiplexer, and no more events to be processed inside the Event Queue.
We can now define the pattern at the heart of Node.js.
Note
Pattern (reactor): handles I/O by blocking until new events are available from a set of observed resources, and then reacting by dispatching each event to an associated handler.
The non-blocking I/O engine of Node.js – libuv
Each operating system has its own interface for the Event Demultiplexer: epoll on Linux, kqueue on Mac OS X, and I/O Completion Port API (IOCP) on Windows. Besides that, each I/O operation can behave quite differently depending on the type of the resource, even within the same OS. For example, in Unix, regular filesystem files do not support non-blocking operations, so, in order to simulate a non-blocking behavior, it is necessary to use a separate thread outside the Event Loop. All these inconsistencies across and within the different operating systems required a higher-level abstraction to be built for the Event Demultiplexer. This is exactly why the Node.js core team created a C library called libuv, with the objective to make Node.js compatible with all the major platforms and normalize the non-blocking behavior of the different types of resource; libuv today represents the low-level I/O engine of Node.js.
Besides abstracting the underlying system calls, libuv also implements the reactor pattern, thus providing an API for creating event loops, managing the event queue, running asynchronous I/O operations, and queuing other types of tasks.
Note
A great resource to learn more about libuv is the free online book created by Nikhil Marathe, which is available at http://nikhilm.github.io/uvbook/.
The recipe for Node.js
The reactor pattern and libuv are the basic building blocks of Node.js, but we need the following three other components to build the full platform:
A set of bindings responsible for wrapping and exposing
libuvand other low-level functionality to JavaScript.V8, the JavaScript engine originally developed by Google for the Chrome browser. This is one of the reasons why Node.js is so fast and efficient. V8 is acclaimed for its revolutionary design, its speed, and for its efficient memory management.
A core JavaScript library (called node-core) that implements the high-level Node.js API.
Finally, this is the recipe of Node.js, and the following image represents its final architecture:











