Let's imagine that a client approaches you, wanting you to design a solution for them. They need some kind of banking application that has to guarantee data consistency within the whole system. Our client had been using an Oracle database until now and has also purchased support from their side. Without thinking too much, we decide to design a monolithic application based on a relational data model. You can see a simplified diagram of the system's design here:

There are four entities that are mapped into the tables in the database:
- The first of them, Customer, stores and retrieves the list of active clients
- Every customer could have one or more accounts, which are operated by the Account entity
- The Transfer entity is responsible for performing all transfers of funds between accounts within the system
- There is also the Product entity that is created to store information such as the deposits and credits assigned to the clients
Without going into further details, the application exposes the API that provides all the necessary operations for realizing actions on the designed database. Of course, the implementation is in compliance with the three-layer model.
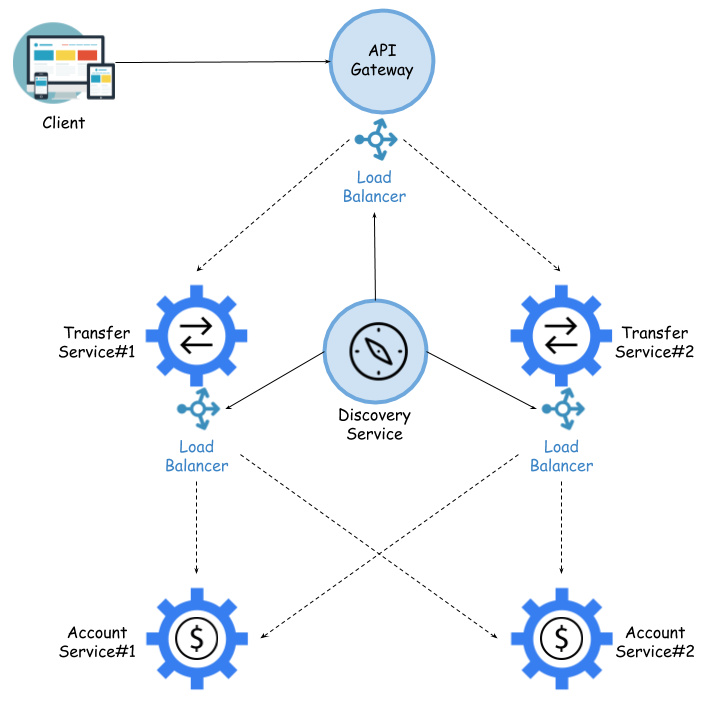
Consistency is not the most important requirement anymore; it is not even obligatory. The client expects a solution, but does not want the development to require the redeployment of the whole application. It should be scalable and should easily be able to extend new modules and functionalities. Additionally, the client does not put pressure on the developer to use Oracle or another relational database—not only that, but he would be happy to avoid using it. Are these sufficient reasons to decide on migrating to microservices? Let's just assume that they are. We divide our monolithic application into four independent microservices, each one of them with a dedicated database. In some cases, it can still be a relational database, while in others it can be a NoSQL database. Now, our system consists of many services that are independently built and run in our environment. Along with an increase in the number of microservices, there is a rising level of system complexity. We would like to hide that complexity from the external API client, which should not be aware that it talks to service X but not Y. The gateway is responsible for dynamically routing all requests to different endpoints. For example, the word dynamically means that it should be based on entries in the service discovery, which I'll talk about later in the section Understanding the need for service discovery.
Hiding invocations of specific services or dynamic routing is not the only function of an API gateway. Since it is the entry point to our system, it can be a great place to track important data, collect metrics of requests, and count other statistics. It can enrich requests or response headers in order to include some additional information that is usable by the applications inside the system. It should perform some security actions, such as authentication and authorization, and should be able to detect the requirements for each resource and reject requests that do not satisfy them. Here's a diagram that illustrates the sample system, consisting of four independent microservices, which is hidden from an external client behind an API gateway: