






















































Naive Bayes
Naive Bayes is a classification algorithm based on Bayes' probability theorem and conditional independence hypothesis on the features. Given a set of m features, 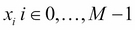 , and a set of labels (classes)
, and a set of labels (classes) 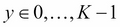 , the probability of having label c (also given the feature set xi) is expressed by Bayes' theorem:
, the probability of having label c (also given the feature set xi) is expressed by Bayes' theorem:

Here:
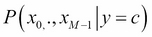 is called the likelihood distribution
is called the likelihood distribution
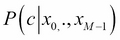 is the posteriori distribution
is the posteriori distribution
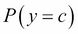 is the prior distribution
is the prior distribution
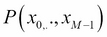 is called the evidence
is called the evidence
The predicted class associated with the set of features will be the value p such that the probability is maximized:

However, the equation cannot be computed. So, an assumption is needed.
Using the rule on conditional probability 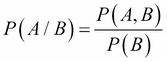 , we can write the numerator of the previous formula as follows:
, we can write the numerator of the previous formula as follows:



We now use the assumption that each feature xi is conditionally independent given c (for example, to calculate the probability of x1 given c, the knowledge of the label c makes the knowledge of the other feature x0 redundant, 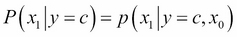 ):
):

Under this assumption, the probability...


