Suppose we observe a hundred roulette spins, and we get red 30 times and black 70 times. We can start by assuming that the probability of getting red is 0.5 (and black is obviously 0.5). This is certainly not a very good idea, because if that was the case, we should have seen nearly red 50 times and black 50 times, but we did not. It is thus evident that a more reasonable assumption would have been a probability of 0.3 for red (and thus 0.7 for black).
The principle of maximum likelihood establishes that, given the data, we can formulate a model and tweak its parameters to maximize the probability (likelihood) of having observed what we did observe. Additionally, maximum likelihood allows us to calculate the precision (standard error) of each estimated coefficient easily. They are obtained by finding the curvature of the log-likelihood with respect to each parameter; this is obtained by finding the second-order derivatives of the log-likelihood with respect to each parameter.
The likelihood is essentially a probability composed of the multiplication of several probabilities. Multiplying lots of probabilities is never a good idea, because if the probabilities are small, we would very likely end up with a very small number. If that number is too small, then the computer won't be able to represent it accurately. Therefore, what we end up using is the log-likelihood, which is the sum of the logarithms of those probabilities.
In many situations, we also want to know if the coefficients are statistically different from zero. Imagine we have a sample of growth rates for many companies for a particular year, and we want to use the average as an indicator of whether the economy is growing or not. In other words, we want to test whether the mean is equal to zero or not. We could fit that distribution of growth rates to a Gaussian distribution (which has two parameters, 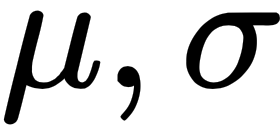 ), and test whether
), and test whether 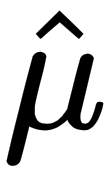 (estimated
(estimated 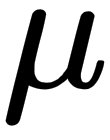 ) is statistically equal to zero. In a Gaussian distribution, the mean is
) is statistically equal to zero. In a Gaussian distribution, the mean is 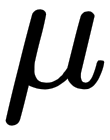 . When doing hypothesis testing, we need to specify a null hypothesis and an alternative one. For this case, the null hypothesis is that this parameter is equal to zero. Intuition would tell us that if an estimated parameter is large, we can reject the null hypothesis. The problem is that we need to define what large is. This is why we don't use the estimated coefficients, but a statistic called the Z value—this is defined as the value that we observed divided by the standard error. It can be proven that these are distributed according to a Gaussian distribution.
. When doing hypothesis testing, we need to specify a null hypothesis and an alternative one. For this case, the null hypothesis is that this parameter is equal to zero. Intuition would tell us that if an estimated parameter is large, we can reject the null hypothesis. The problem is that we need to define what large is. This is why we don't use the estimated coefficients, but a statistic called the Z value—this is defined as the value that we observed divided by the standard error. It can be proven that these are distributed according to a Gaussian distribution.
So, once we have the Z value statistic, how can we reject or not reject the null hypothesis? Assuming that the null hypothesis is true (that the coefficient is equal to zero), we can compute the probability that we get a test statistic as large or larger than the one we got (these are known as p-values). Remember that we assume that the coefficients have fixed values, but we will observe random deviations from them in our samples (we actually have one sample). If the probability of finding them to be as large as the ones that we observed is small, assuming that the true ones are zero, then that implies that luck alone can't explain the coefficients that we got. The final conclusion in that case is to reject the null hypothesis and conclude that the coefficient is different from zero.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand




















