























































Implementing the revised approach
In this section, we will see the actual implementation of our revised approach, and this revised approach will use K-fold cross-validation and hyperparameter optimization. I have divided the implementation part into two sections so you can connect the dots when you see the code. The two implementation parts are as follows:
Implementing a cross-validation based approach
Implementing hyperparameter tuning
Implementing a cross-validation based approach
In this section, we will see the actual implementation of K-fold CV. Here, we are using the scikit-learn cross-validation score module. So, we need to choose the value of K-fold. By default, the value is 3. I'm using the value of K = 5. You can refer to the code snippet given in the following figure:
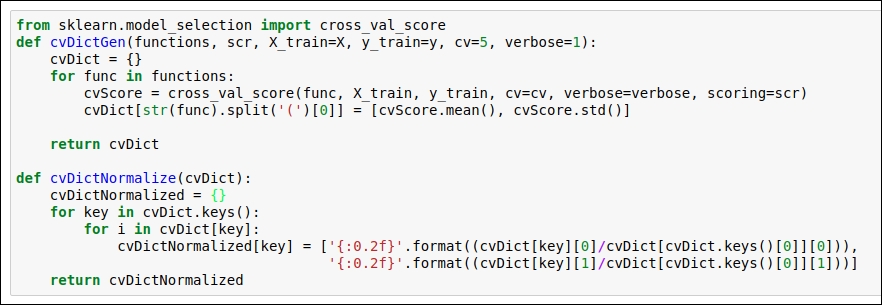
Figure 1.57: Code snippet for the implementation of K-fold cross validation
As you can see in the preceding figure, we obtain cvScore.mean() and cvScore.std() scores to evaluate our model performance. Note that we have taken the whole training dataset into consideration. So, the values for these parameters are X_train = X and y_train = y. Here, we define the cvDictGen function , which will track the mean value and the standard deviation of the accuracy. We have also implemented the cvDictNormalize function, which we can use if we want to obtain a normalized mean and a standard deviation (std) score. For the time being, we are not going to use the cvDictNormalize function.
Now it's time to run the cvDictGen method. You can see the output in the following figure:
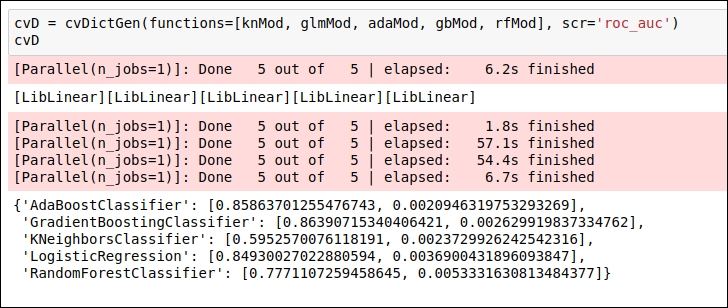
Figure 1.58: Code snippet for the output of K-fold cross validation
We have performed cross-validation for five different ML algorithms to check which ML algorithm works well. As we can see, in our output given in the preceding figure, GradietBoosting and Adaboot classifier work well. We have used the cross-validation score in order to decide which ML algorithm we should select and which ones we should not go with. Apart from that, based on the mean value and the std value, we can conclude that our ROC-AUC score does not deviate much, so we are not suffering from the overfitting issue.
Now it's time to see the implementation of hyperparameter tuning.
Implementing hyperparameter tuning
In this section, we will look at how we can obtain optimal values for hyperparameters. Here, we are using the RandomizedSearchCV hyperparameter tuning method. We have implemented this method for the AdaBoost and GradientBossting algorithms. You can see the implementation of hyperparameter tuning for the Adaboost algorithm in the following figure:
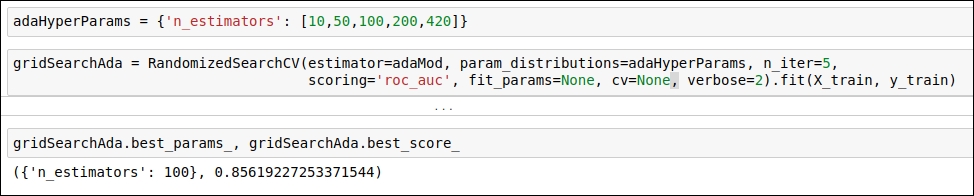
Figure 1.59: Code snippet of hyperparameter tuning for the Adaboost algorithm
After running the RandomizedSearchCV method on the given values of parameters, it will generate the optimal parameter value. As you can see in the preceding figure, we want the optimal value for the parameter; n_estimators.RandomizedSearchCV obtains the optimal value for n_estimators, which is 100.
You can see the implementation of hyperparameter tuning for the GradientBoosting algorithm in the following figure:
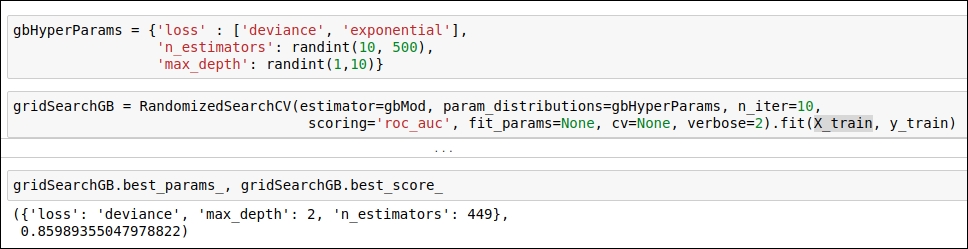
Figure 1.60: Code snippet of hyperparameter tuning for the GradientBoosting algorithm
As you can see in the preceding figure, the RandomizedSearchCV method obtains the optimal value for the following hyperparameters:
'loss': 'deviance'
'max_depth': 2
'n_estimators': 449
Now it's time to test our revised approach. Let's see how we will test the model and what the outcome of the testing will be.
Implementing and testing the revised approach
Here, we need to plug the optimal values of the hyperparameters, and then we will see the ROC-AUC score on the validation dataset so that we know whether there will be any improvement in the accuracy of the classifier or not.
You can see the implementation and how we have performed training using the best hyperparameters by referring to the following figure:

Figure 1.61: Code snippet for performing training by using optimal hyperparameter values
Once we are done with the training, we can use the trained model to predict the target labels for the validation dataset. After that, we can obtain the ROC-AUC score, which gives us an idea of how much we are able to optimize the accuracy of our classifier. This score also helps validate our direction, so if we aren't able to improve our classifier accuracy, then we can identify the problem and improve accuracy in the next iteration. You can see the ROC-AUC score in the following figure:
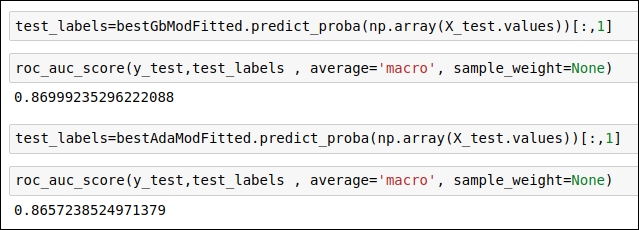
Figure 1.62: Code snippet of the ROC-AUC score for the revised approach
As you can see in the output, after hyperparameter tuning, we have an improvement in the ROC-AUC score compared to our baseline approach. In our baseline approach, the ROC-AUC score for AdaBoost is 0.85348539, whereas after hyperparameter tuning, it is 0.86572352. In our baseline approach, the ROC-AUC score for GradientBoosting is 0.85994964, whereas after hyperparameter tuning, it is 0.86999235. These scores indicate that we are heading in the right direction.
The question remains: can we further improve the accuracy of the classifiers? Sure, there is always room for improvement, so we will follow the same approach. We list all the possible problems or areas we haven't touched upon yet. We try to explore them and generate the best possible approach that can give us good accuracy on the validation dataset as well as the testing dataset.
So let's see what our untouched areas in this revised approach will be.
Understanding problems with the revised approach
Up until the revised approach, we did not spend a lot of time on feature engineering. So in our best possible approach, we spent time on the transformation of features engineering. We need to implement a voting mechanism in order to generate the final probability of the prediction on the actual test dataset so that we can get the best accuracy score.
These are the two techniques that we need to apply:
Feature transformation
An ensemble ML model with a voting mechanism
Once we implement these techniques, we will check our ROC-AUC score on the validation dataset. After that, we will generate a probability score for each of the records present in the real test dataset. Let's start with the implementation.
















