























































Cost function
To fit the weights in a neural net for a given training set, we first need to define a cost function:
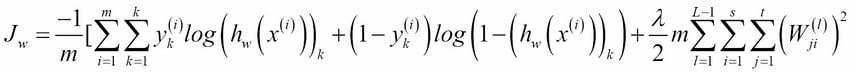
This is very similar to the cost function we used for logistic regression, except that now we are also summing over k output units. The triple summation used in the regularization term looks a bit complicated, but all it is really doing is summing over each of the terms in the parameter matrix, and using this to calculate the regularization. Note that the summation, i, l, and j start at 1, rather than 0; this is to reflect the fact that we do not apply regularization to the bias unit.
Minimizing the cost function
Now that we have cost function, we need to work out a way to minimize it. As with gradient descent, we need to compute the partial derivatives to calculate the slope of the cost function. This is done using the back propagation algorithm. It is called back propagation because we begin by calculating the error at the output layer, then calculating the error for each previous...










