






















































Case study: targeted e-mail campaigns
In our next example, our same marketing department wants to promote new items on their website to users who are mostly likely to be interested in purchasing them. Using a predictive model that includes features from both users and these new items, customers are sent e-mails containing a list of their most probable purchase. Unlike the real-time sentiment-monitoring example, e-mails are sent in batches and use data accumulated over a customer's whole transaction history as inputs to the model, which is a better fit for batch processing.
An overview of the processes used in this example is shown in Figure 7.
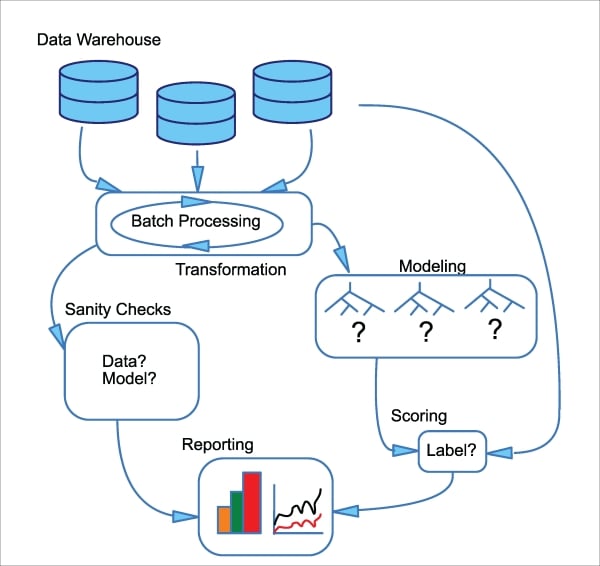
Figure 7: Diagram of e-mail targeting case study
Data input and transformation
During the initial data ingestion step, customer records stored in a company's data warehouse (a relational database system) are aggregated to generate features such as the average amount spent per week, frequency with which a customer visits the company's website, and the number of items purchased in a number of categories, such as furniture, electronics, clothing, and media. This is combined with a set of features for the set of items that are potentially promoted in the e-mail campaign, such as price, brand, and the average rating of similar items on the site. These features are constructed through a batch process that runs once per week, before e-mails are sent, on Mondays, to customers.
Sanity checking
The inputs to the model are checked for reasonable values: are the average purchase behaviors or transactions volume of a customer far outside the expected range? These could indicate errors in the data warehouse processing, or bot traffic on the website. Because the transformation logic involved in constructing features for the model is complex and may change over time as the model evolves, its outputs are also checked. For example, the purchase numbers and average prices should never be less than zero, and no category of merchandise should have zero records.
Following scoring of potential items prior to e-mail messaging, the top-scoring items per customer are sanity checked by comparing them to either the customer's historical transactions (to determine if they are sensible), or if no history is available, to the purchases of customers most similar in demographics.
Model development
In this example, the model is a random forest regression Chapter 4, Connecting the Dots with Models – Regression Methods that divides historical items – customer pairs into purchases (labeled 1) and non-purchases (labeled 0) and produces a scored probability that customer A purchases item X. One complexity in this model is that items which haven't been purchased might simply not have been seen by the customer yet, so a restriction is imposed in which the negative examples must be drawn from items already available for a month or more on the website. The hyperparameters of this model (the number and size of each tree) are calibrated during weekly retraining, along with the influence of individual variables on the resulting predictions.
Scoring
After the model is retrained each week using historical data, the set of new items on the website are scored using this model for each customer, and the top three are sent in the e-mail campaign.
Visualization and reporting
Either class of sanity checking (of either input data or model performance) can be part of a regular diagnostics report on the model. Because the random forest model is more complex than other approaches, it is particularly important to monitor changes in feature importance and model accuracy as problems may require more time to debug and resolve.
Because the predictions are used in a production system rather than delivering insights themselves, this reporting is primarily used by the analyst who developed the pipeline rather than the other members of the marketing department.
The success of these promotional e-mails will typically be monitored over the next month, and updates on the accuracy (for example, how many e-mails led to purchases above expected levels) can form the basis of a longer-term report that can help guide both the structure of the campaign itself (for example, varying the number of items in the messages) and the model (perhaps training should be performed more frequently if the predictions seem to become significantly worse between weeks).
Tip
Downloading the example code
You can download the example code files for this book from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
You can download the code files by following these steps:
- Log in or register to our website using your e-mail address and password.
- Hover the mouse pointer on the SUPPORT tab at the top.
- Click on Code Downloads & Errata.
- Enter the name of the book in the Search box.
- Select the book for which you're looking to download the code files.
- Choose from the drop-down menu where you purchased this book from.
- Click on Code Download.
Once the file is downloaded, please make sure that you unzip or extract the folder using the latest version of:
WinRAR / 7-Zip for Windows
- Zipeg / iZip / UnRarX for Mac
- 7-Zip / PeaZip for Linux


