






















































Given the need to provide different kinds of tests – unit, integration, and E2E as each one of them has different benefits and costs, the next immediate question is how do we get the right balance?
Each kind of test comes with a benefit and a cost, so it's a matter of finding where we get the best return on investment:
- E2E tests verify the real experience of what the user faces. They are, in theory, the most realistic kind of tests and can detect problems such as incompatibilities with specific platforms (for example, browsers) and exercise our system as a whole. But when something goes wrong, it is hard to spot where the problem lies. They are very slow and tend to be flaky (failing for reasons unrelated to our software, such as network conditions).
- Integration tests usually provide a reasonable guarantee that the software is doing what it is expected to do and are fairly robust to internal implementation changes, requiring less frequent refactoring when the internals of the software change. But they can still get very slow if your system involves writes to database services, the rendering of page templates, routing HTTP requests, and generally slow parts. And when something goes wrong, we might have to go through tens of layers before being able to spot where the problem is.
- Unit tests can be very fast (especially when talking of solitary units) and provide very pinpointed information about where problems are. But they can't always guarantee that the software as a whole does what it's expected to do and can make changing implementation details expensive because a change to internals that don't impact the software behavior might require changing tens of unit tests.
Each of them has its own pros and cons, and the development community has long argued how to get the right balance.
The two primary models that have emerged are the testing pyramid and the testing trophy, named after their shapes.
The testing pyramid
The testing pyramid originates from Mike Cohn's Succeeding with Agile book, where the two rules of thumb are "Write test with different granularities" (so you should have unit, integration, E2E, and so on...) and "the more you get high level, the less you should test" (so you should have tons of unit tests, and a few E2E tests).
While different people will argue about which different layers are contained within it, the testing pyramid can be simplified to look like this:
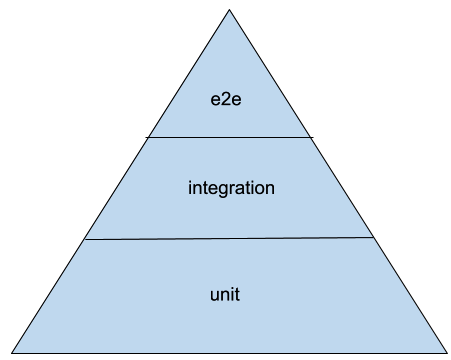
The tip of the pyramid is narrow, thus meaning we have fewer of those tests, while the base is wider, meaning we should mostly cover code with those kinds of tests. So, as we move down through the layers, the lower we get, the more tests we should have.
The idea is that as unit tests are fast to run and expose pinpointed issues early on, you should have a lot of them and shrink the number of tests as they move to higher layers and thus get slower and vaguer about what's broken.
The testing pyramid is probably the most widespread practice for organizing tests and usually pairs well with test-driven development as unit tests are the founding tool for the TDD process.
The other most widespread model is the testing trophy, which instead emphasizes integration tests.
The testing trophy
The testing trophy originates from a phrase by Guillermo Rauch, the author of Socket.io and many other famous JavaScript-based technologies. Guillermo stated that developers should "Write tests. Not too many. Mostly integration."
Like Mike Cohn, he clearly states that tests are the foundation of any effective software development practice, but he argues that they have a diminishing return and thus it's important to find the sweet spot where you get the best return on the time spent writing tests.
That sweet spot is expected to live in integration tests because you usually need fewer of them to spot real problems, they are not too bound to implementation details, and they are still fast enough that you can afford to write a few of them.
So the testing trophy will look like this:
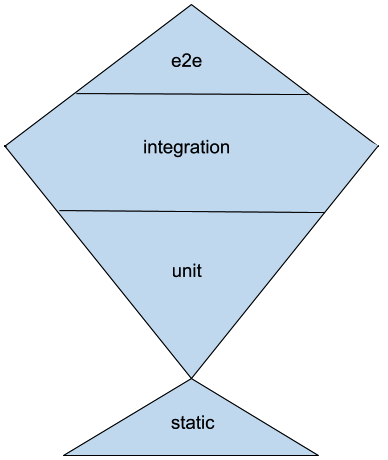
As you probably saw, the testing trophy puts a lot of value on static tests too, because the whole idea of the testing trophy is that what is really of value is the return on investment, and static checks are fairly cheap, up to the point that most development environments run them in real time. Linters, type checkers, and more advanced kinds of type analyzers are cheap enough that it would do no good to ignore them even if they are rarely able to spot bugs in your business logic.
Unit tests instead can cost developers time with the need to adapt them due to internal implementation detail changes that don't impact the final behavior of the software in any way, and thus the effort spent on them should be kept under control.
Those two models are the most common ways to distribute your tests, but more best practices are involved when thinking of testing distribution and coverage.
Testing distribution and coverage
While the importance of testing is widely recognized, there is also general agreement that test suites have a diminishing return.
There is little point in wasting hours on testing plain getters and setters or testing internal/private methods. The sweet spot is said to be around 80% of code coverage, even though I think that really depends on the language in use – the more expressive your language is, the less code you have to write to perform complex actions. And all complex actions should be properly tested, so in the case of Python, the sweet spots probably lies more in the range of 90%. But there are cases, such as porting projects from Python 2 to Python 3, where code coverage of 100% is the only way you can confirm that you haven't changed any behavior at all in the process of porting your code base.
Last but not least, most testing practices related to test-driven development take care of the testing practice up to the release point. It's important to keep in mind that when the software is released, the testing process hasn't finished.
Many teams forget to set up proper system tests and don't have a way to identify and reproduce issues that can only happen in production environments with real concurrent users and large amounts of data. Having staging environments and a suite to simulate incidents or real users' behaviors might be the only way to spot bugs that only happen after days of continuous use of the system. And some companies go as far as testing the production system with tools that inject real problems continuously for the sole purpose of verifying that the system is solid.











