






















































When learning Python for the first time, it is useful to use Jupyter notebooks as an interactive developing environment (IDE). This is one of the main reasons why Anaconda is so powerful. It fully integrates all of the dependencies between Python and Jupyter notebooks. The same can be done with PySpark and Jupyter notebooks. While Spark is written in Scala, PySpark allows for the translation of code to occur within Python instead.
Integrating Jupyter notebooks with Spark
Getting ready
Most of the work in this section will just require accessing the .bashrc script from the terminal.
How to do it...
PySpark is not configured to work within Jupyter notebooks by default, but a slight tweak of the .bashrc script can remedy this issue. We will walk through these steps in this section:
- Access the .bashrc script by executing the following command:
$ nano .bashrc
- Scrolling all the way to the end of the script should reveal the last command modified, which should be the PATH set by Anaconda during the installation earlier in the previous section. The PATH should appear as seen in the following:
# added by Anaconda3 4.4.0 installer
export PATH="/home/asherif844/anaconda3/bin:$PATH"
- Underneath, the PATH added by the Anaconda installer can include a custom function that helps communicate the Spark installation with the Jupyter notebook installation from Anaconda3. For the purposes of this chapter and remaining chapters, we will name that function sparknotebook. The configuration should appear as the following for sparknotebook():
function sparknotebook()
{
export SPARK_HOME=/home/asherif844/spark-2.2.0-bin-hadoop2.7
export PYSPARK_PYTHON=python3
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"
$SPARK_HOME/bin/pyspark
}
- The updated .bashrc script should look like the following once saved:
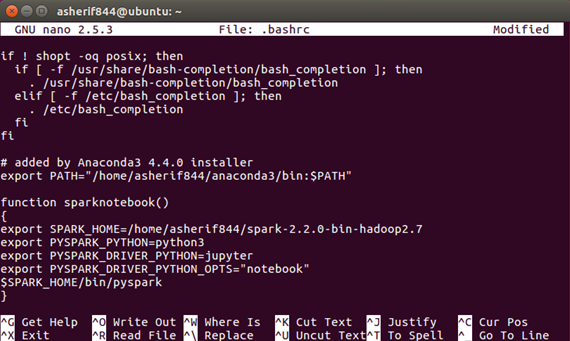
- Save and exit from the .bashrc file. It is recommended to communicate that the .bashrc file has been updated by executing the following command and restarting the terminal application:
$ source .bashrc
How it works...
Our goal in this section is to integrate Spark directly into a Jupyter notebook so that we are not doing our development at the terminal and instead utilizing the benefits of developing within a notebook. This section explains how the Spark integration within a Jupyter notebook takes place.
- We will create a command function, sparknotebook, that we can call from the terminal to open up a Spark session through Jupyter notebooks from the Anaconda installation. This requires two settings to be set in the .bashrc file:
- PySpark Python be set to python 3
- PySpark driver for python to be set to Jupyter
- The sparknotebook function can now be accessed directly from the terminal by executing the following command:
$ sparknotebook
- The function should then initiate a brand new Jupyter notebook session through the default web browser. A new Python script within Jupyter notebooks with a .ipynb extension can be created by clicking on the New button on the right-hand side and by selecting Python 3 under Notebook: as seen in the following screenshot:
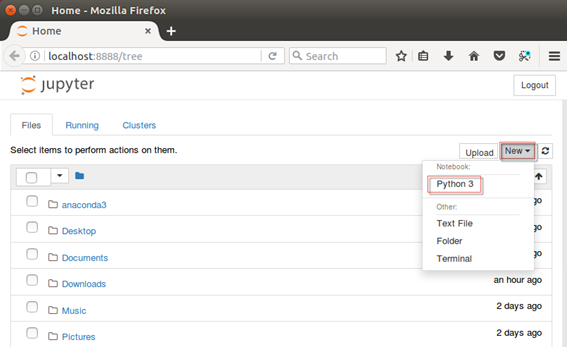
- Once again, just as was done at the terminal level for Spark, a simple script of sc will be executed within the notebook to confirm that Spark is up and running through Jupyter:
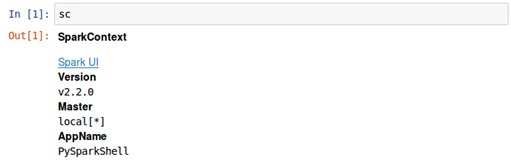
- Ideally, the Version, Master, and AppName should be identical to the earlier output when sc was executed at the terminal. If this is the case, then PySpark has been successfully installed and configured to work with Jupyter notebooks.
There's more...
It is important to note that if we were to call a Jupyter notebook through the terminal without specifying sparknotebook, our Spark session will never be initiated and we will receive an error when executing the SparkContext script.
We can access a traditional Jupyter notebook by executing the following at the terminal:
jupyter-notebook
Once we start the notebook, we can try and execute the same script for sc.master as we did previously, but this time we will receive the following error:
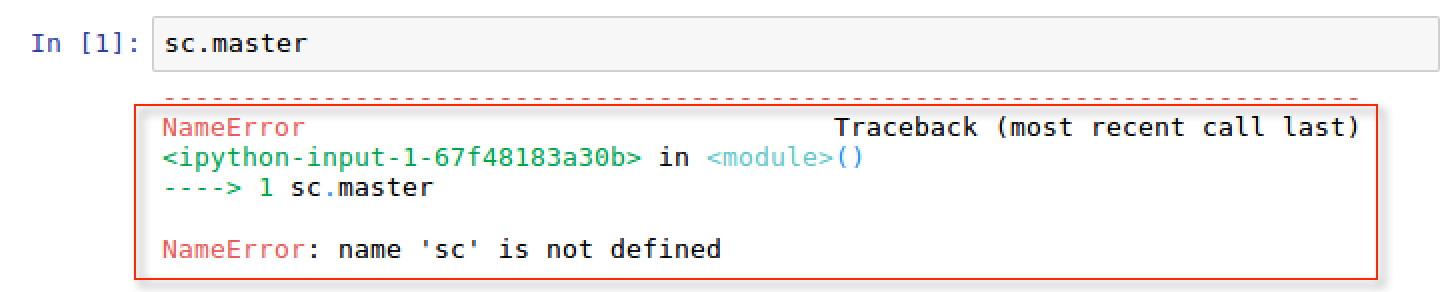
See also
There are many managed offerings online of companies offering Spark through a notebook interface where the installation and configuration of Spark with a notebook have already been managed for you. These are the following:
- Hortonworks (https://hortonworks.com/)
- Cloudera (https://www.cloudera.com/)
- MapR (https://mapr.com/)
- DataBricks (https://databricks.com/)






















