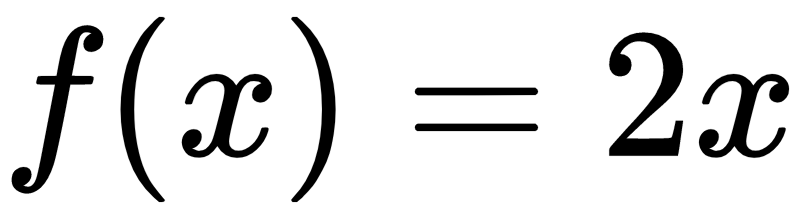Linear regression refers to finding the underlying function with the help of linear combination of input variables. The previous example had an input variable and an output variable. A simple linear regression is easy to understand, but represents the basis of regression techniques. Once these concepts are understood, it will be easier for us to address the other types of regression.
Consider the following diagram:
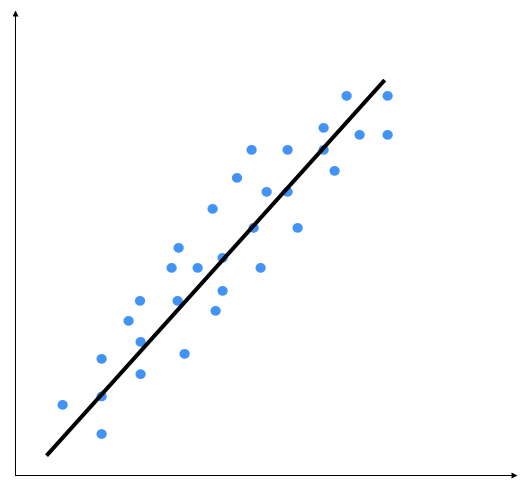
The linear regression method consists of precisely identifying a line that is capable of representing point distribution in a two-dimensional plane, that is, if the points corresponding to the observations are near the line, then the chosen model will be able to describe the link between the variables effectively.
In theory, there are an infinite number of lines that may approximate the observations, while in practice, there is only one mathematical model that optimizes the representation of the data. In the case of a linear mathematical relationship, the observations of the y variable can be obtained by a linear function of the observations of the x variable. For each observation, we will use the following formula:
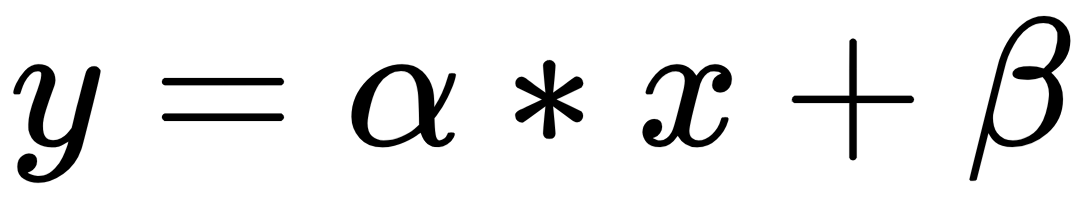
In the preceding formula, x is the explanatory variable and y is the response variable. The α and β parameters, which represent the slope of the line and the intercept with the y-axis respectively, must be estimated based on the observations collected for the two variables included in the model.
The slope, α, is of particular interest, that is, the variation of the mean response for every single increment of the explanatory variable. What about a change in this coefficient? If the slope is positive, the regression line increases from left to right, and if the slope is negative, the line decreases from left to right. When the slope is zero, the explanatory variable has no effect on the value of the response. But it is not just the sign of α that establishes the weight of the relationship between the variables. More generally, its value is also important. In the case of a positive slope, the mean response is higher when the explanatory variable is higher, while in the case of a negative slope, the mean response is lower when the explanatory variable is higher.
The main aim of linear regression is to get the underlying linear model that connects the input variable to the output variable. This in turn reduces the sum of squares of differences between the actual output and the predicted output using a linear function. This method is called ordinary least squares. In this method, the coefficients are estimated by determining numerical values that minimize the sum of the squared deviations between the observed responses and the fitted responses, according to the following equation:
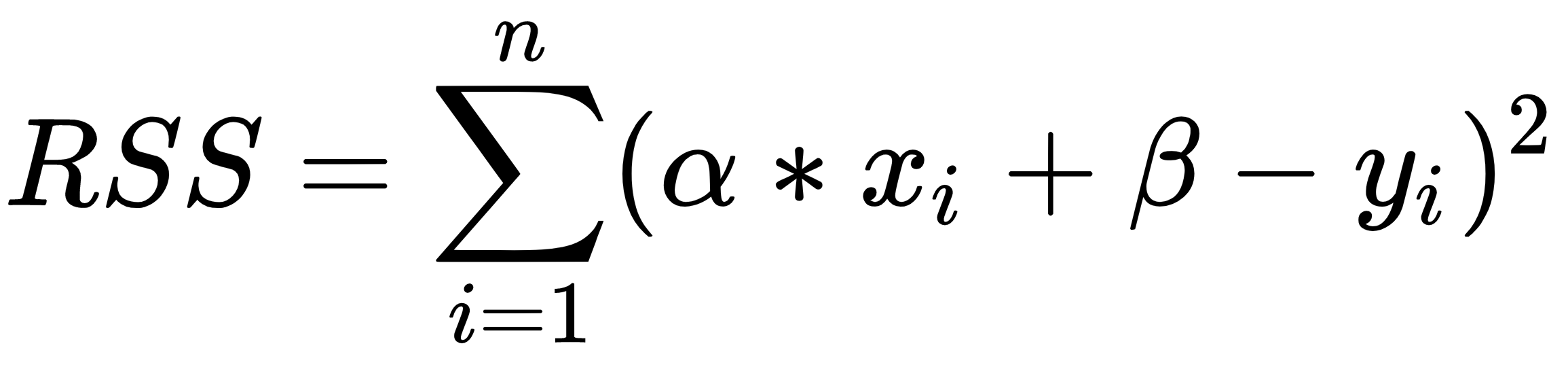
This quantity represents the sum of the squares of the distances to each experimental datum (xi, yi) from the corresponding point on the straight line.
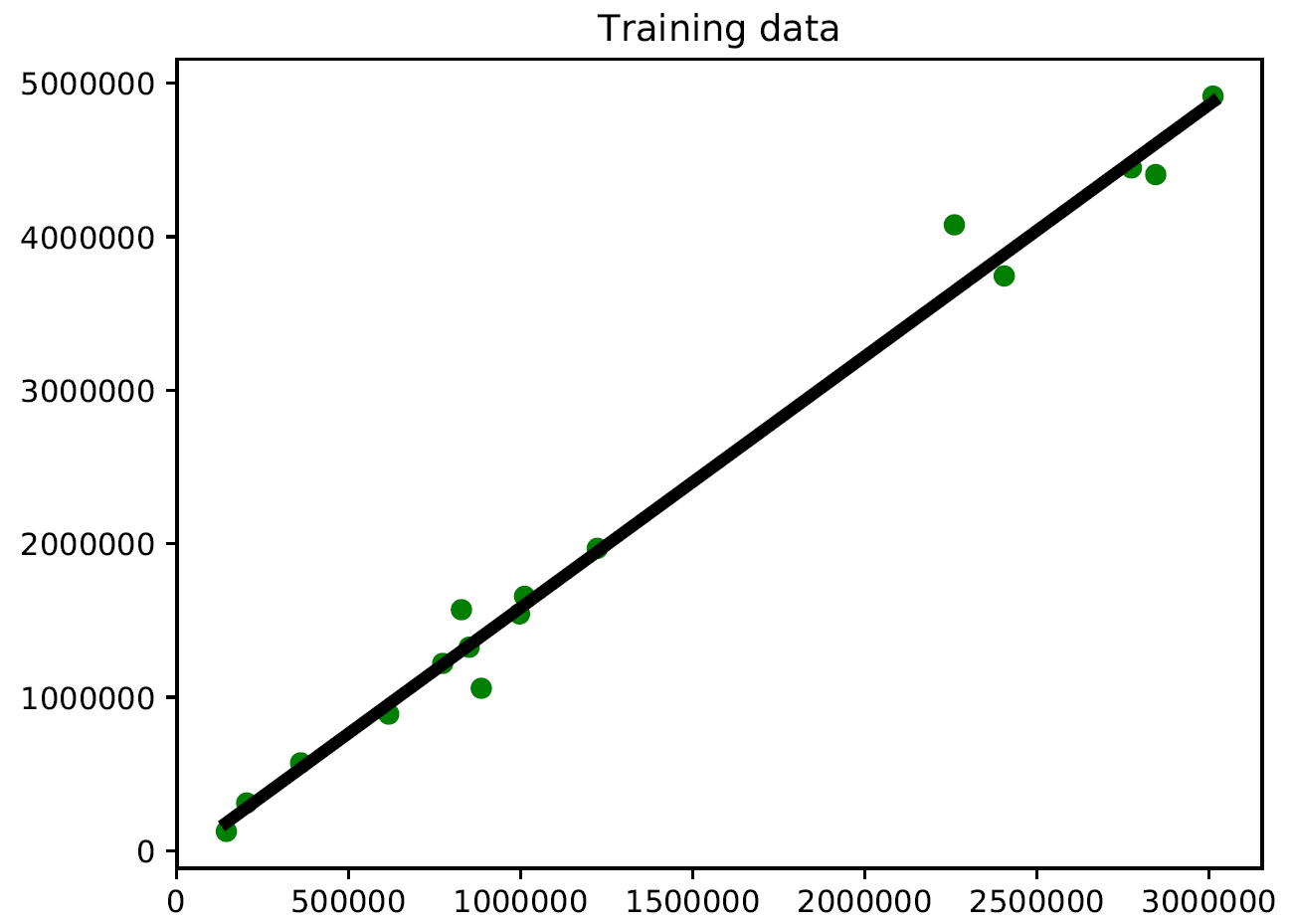
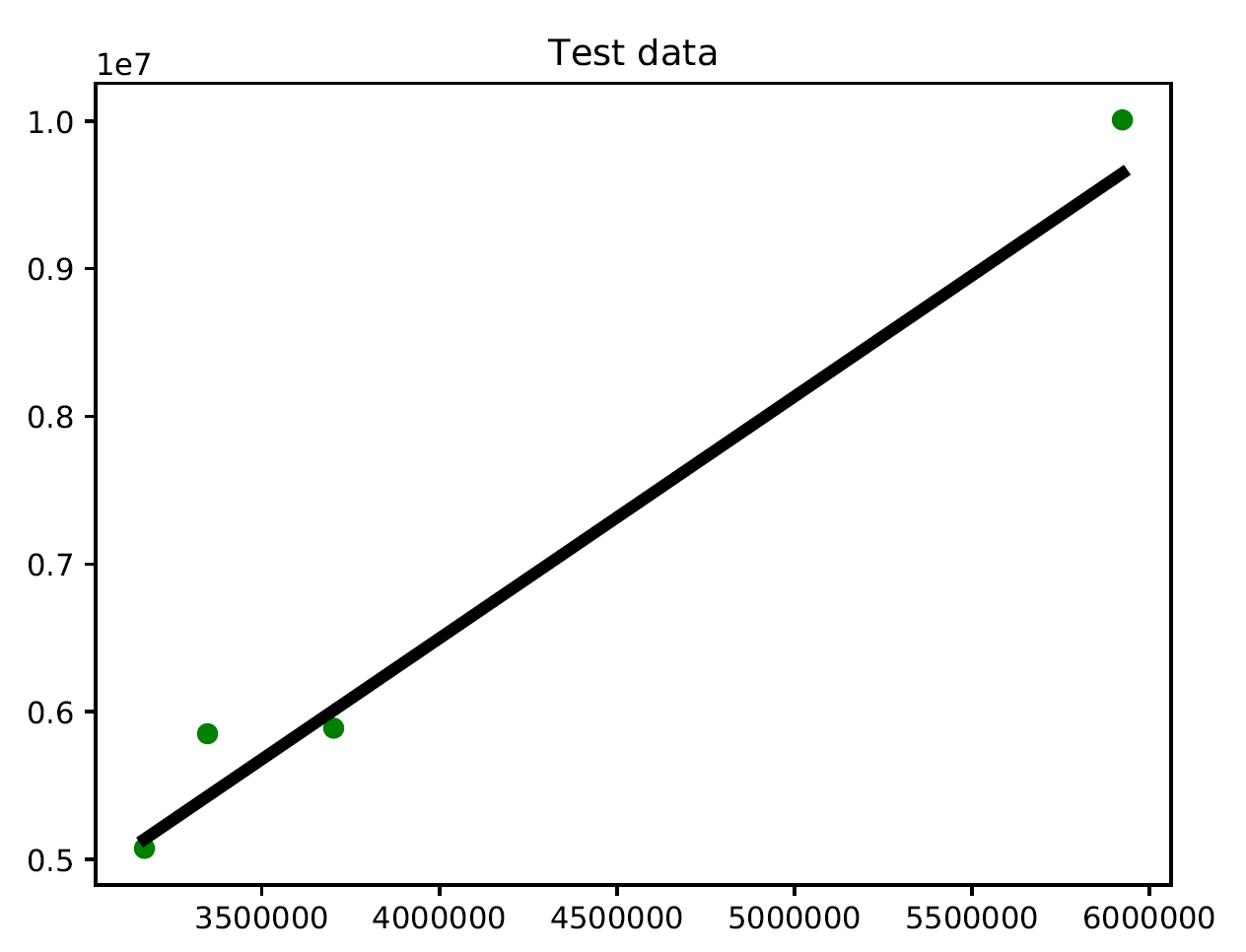
You might say that there might be a curvy line out there that fits these points better, but linear regression doesn't allow this. The main advantage of linear regression is that it's not complex. If you go into non-linear regression, you may get more accurate models, but they will be slower. As shown in the preceding diagram, the model tries to approximate the input data points using a straight line. Let's see how to build a linear regression model in Python.