






















































Learning about Delta Lake
Delta Lake was launched by Databricks as an open source project owned by the Linux Foundation that converts a traditional data lake into a lakehouse. The term lakehouse refers to a platform that brings in the best of both data lakes and warehouses. Delta Lake offers the following features:
- ACID transactions: Data readers never see inconsistent data, also called dirty reads.
- Handling metadata: Spark's distributed processing power makes it easy to handle the metadata of tables with terabytes and petabytes of data in a scalable fashion.
- Streaming and batch workloads: Delta Lake helps unify stream and batch processing on data.
- Schema enforcement: The schema is always checked before data gets appended. This helps to prevent the corruption of data.
- Time travel: View and roll back to previous versions of data enabling audit logs.
- Upserts and deletes: Perform transactions such as updates, inserts, and deletes on data lying in the lake.
Next, we'll look at big data file formats.
Big data file formats
Before we dive deeper into Delta Lake, let's first try to understand the file formats used to store big data. Traditional file formats such as CSV and TSV store data in a row-wise format and are not partitioned. CSVs are basically strings without any data types so they always need to be scanned entirely without any scope for filtering. This makes it difficult for processing and querying larger datasets. Instead, file formats such as Parquet, ORC, and Avro help us overcome many such challenges as they can be stored in a distributed fashion.
Note
Row-based file formats store data by row, whereas columnar file formats store data by column. Row-based file formats work best for transactional writes of data, whereas columnar file formats are ideal for data querying and analytical workloads.
Let us look at row-based file formats versus columnar file formats in the following image:
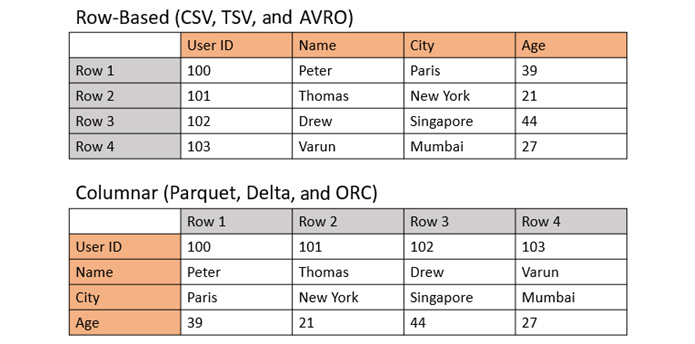
Figure 1.17 – Row-based file formats versus columnar
The similarities between Parquet, ORC, and Avro are as follows:
- All three file formats are machine-readable formats and not human-readable.
- They can be partitioned across a cluster for parallel processing and distribution.
- The formats carry the data schema as well. This helps newer machines or clusters to process the data independently.
The differences between Parquet, ORC, and Avro are as follows:
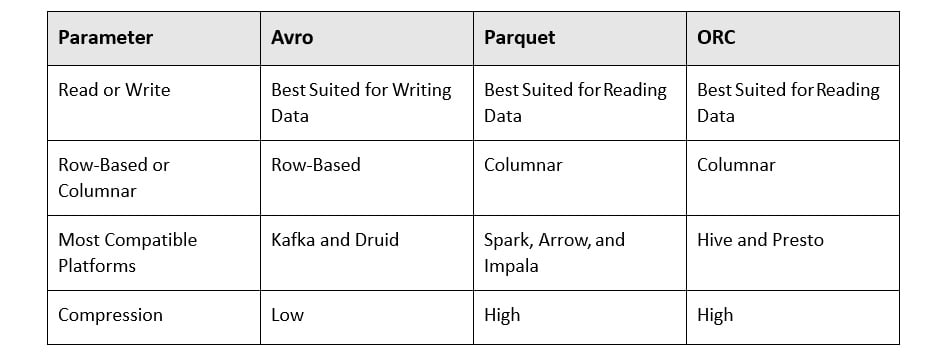
Figure 1.18 – Comparison of Avro, Parquet, and ORC
Coming back to Delta Lake, it can simply be treated as a file format. Tables that are created on top of this delta file format are simply called delta tables. The delta file format is mainly composed of two components:
- Transactional logs: A
_delta_logfolder is created when data is written in the delta file format. This folder stores files that record all the transactions to data. - Versioned Parquet files: This is the actual data that is written out as partitions. These Parquet partition files (
.parquet) can also be compacted later using different functions. For efficient querying purposes, these Parquet partition files can also be distributed based on partition folders.

Figure 1.19 – Data written in delta format as viewed in Azure Blob Storage
It's also important for us to understand the use and value of the transactional log.
Understanding the transactional log
Having an understanding of the transactional log is imperative when working with Delta Lake. Let's take a peek at the contents of the _delta_log folder.

Figure 1.20 – Contents of the _delta_log folder as viewed in Azure Blob Storage
Whenever a transaction is carried out on a delta table, the changes are recorded in the _delta_log folder in the form of JSON files. The naming conventions of these JSON files begin sequentially, starting with 000000.json. Subsequent JSON files are created as changes get committed (000001.json, 000002.json, and so on). Also, with each fresh transaction, a new set of Parquet files may be written. In this process, the new JSON file created in the _delta_log folder keeps a record of which Parquet files to reference and which to omit. This happens because every transaction to a delta table results in a new version of the table.

Figure 1.21 – JSON files in _delta_log
Let's see how this works with an example. Suppose we have a delta table with a _delta_log folder containing 00000.json. Suppose this JSON file references two Parquet files, part-0000.parquet and part-0001.parquet.
Now we have an UPDATE transaction carried out on the delta table. This creates a new JSON file in the _delta_log folder by the name of 00001.json. Also, a new Parquet file is added in the delta table's directory, part-0002.parquet. Upon checking the new JSON file, we find that it references part-0001.parquet and part-0002.parquet but omits part-0000.parquet.
Delta Lake in action
Let's start by creating a Spark DataFrame by reading a CSV file. Create a new Databricks Python notebook and spin up a Spark cluster with one driver, one worker, the standard type, and autoscaling disabled. Every code block in the following section must be executed in a new notebook cell:
- We will be using the
airlinesdataset from thedatabricks-datasetsrepository. Databricks provides many sample datasets in every workspace. These are part of thedatabricks-datasetsdirectory of the DBFS. The following code block creates a new Spark DataFrame by specifying the first row as the header, automatically inferring the schema, and reading from a CSV file. Once the DataFrame is created, we will display the first five rows:airlines = (spark.read .option("header",True) .option("inferSchema",True) .option("delimiter",",") .csv("dbfs:/databricks-datasets/airlines/part-00000") # View the dataframe display(airlines.limit(5)) - Next, we will write the DataFrame as a delta file in the DBFS. Once the writing process is complete, we can look at the contents of the delta file. It contains four Parquet files and a
_delta_logfolder:airlines.write.mode("overwrite").format("delta").save("dbfs:/airlines/")We can view the location where the data is written in delta format:
display(dbutils.fs.ls("dbfs:/airlines/")) - Inside the
_delta_logfolder, we can find one JSON file:display(dbutils.fs.ls("dbfs:/airlines/_delta_log/")) - Now, we will create a delta table using the delta file that is written to Azure Blob Storage. Here, we will switch from PySpark to Spark SQL syntax using the
%sqlmagic command. The name of the delta table created isairlines_delta_table. A count operation on the newly created delta table returns the number of records in the table:%sql DROP TABLE IF EXISTS airlines_delta_table; CREATE TABLE airlines_delta_table USING DELTA LOCATION "dbfs:/airlines/"; %sql SELECT COUNT(*) as count FROM airlines_delta_table
- Let's perform a
DELETEoperation on the delta table. This will delete all the rows where theMonthcolumn equals10. This deletes 448,620 rows from the delta table:%sql DELETE FROM airlines_delta_table WHERE Month = '10'
- Next, we will perform an
UPDATEoperation on the delta table. This transaction will update theDestcolumn and replace all theSFOvalues withSan Francisco. We can also see that 7,575 rows received updates in the table:%sql UPDATE airlines_delta_table SET Dest = 'San Francisco' WHERE Dest = 'SFO'
- Before we move forward, let's look at the Parquet files and transactional logs folder once again. Inside the delta file, we can see that more Parquet files have been added after two transactions (
DELETEandUPDATE) were carried out:display(dbutils.fs.ls("dbfs:/airlines/")) - Also, the
_delta_logfolder now contains two more JSON files, one for each transaction:display(dbutils.fs.ls("dbfs:/airlines/_delta_log/")) - Finally, it is time for time travel! Running the
DESCRIBE HISTORYcommand on the delta table returns a list of all the versions of the table:%sql -- Time travel DESCRIBE HISTORY airlines_delta_table
- Switching to a previous version is as easy as adding
VERSION AS OFto the delta table. First, we'll try to query the data based on the condition that got updated. For instance, after the update operation, no record should have theSFOvalue. Hence, we get a count of 0:%sql -- Return count of rows where Dest = 'SFO' in current version that is version 2 SELECT COUNT(*) FROM airlines_delta_table WHERE Dest = 'SFO'
- But when the same query is run on the previous version of the delta table (version 1), we get a count of 7,575. This is because this SQL query is querying on the data that existed before the update operation:
%sql -- Return count of rows where Dest = 'SFO' in version 1 SELECT COUNT(*) FROM airlines_delta_table VERSION AS OF 1 WHERE Dest = 'SFO'
Let's recap what we've covered in this first chapter.


