






















































Chapter 8. Web Patterns
The rise of Node.js has proven that JavaScript has a place on web servers, even on very high throughput servers. There is no denying that JavaScript's pedigree remains in the browser for client-side programming.
In this chapter, we're going to look at a number of patterns to improve the performance and usefulness of JavaScript on the client. I'm not sure that all of these can be thought of as patterns in the strictest sense. They are, however, important and worth mentioning.
The concepts we'll examine in this chapter are:
- Sending JavaScript
- Plugins
- Multithreading
- Circuit breaker pattern
- Back-off
- Promises
Sending JavaScript
Communicating JavaScript to the client seems to be a simple proposition: so long as you can get the code to the client, it doesn't matter how that happens, right? Well, not exactly. There are actually a number of things that need to be considered when sending JavaScript to the browser.
Combining files
Way back in Chapter 2, Organizing Code, we looked at how to build objects using JavaScript. Although opinions on this vary, I consider it to be good form to have a one class to one file organization of my JavaScript or really any of my object-oriented code. Doing this makes finding code easy. Nobody needs to hunt through a 9,000-line-long JavaScript file to locate one method. It also allows for a hierarchy to be established, again allowing for good code organization. However, good organization for a developer is not necessarily good organization for a computer. In our case, having a lot of small files is actually highly detrimental. To understand why, you need to know a little bit about how browsers ask for and receive content.
When you type a URL into the address bar of a browser and hit Enter, a cascading series of events happens. The first thing is that the browser will ask the operating system to resolve the website name to an IP address. In both Windows and Linux (and Mac OS X), the standard C library function, gethostbyname, is used. This function will check the local DNS cache to see if the mapping from name to address is already known. If it is, then that information is returned. If not, then the computer makes a request to the DNS server one step up from it. Typically, this is the DNS server provided by the ISP but on a larger network; it could also be a local DNS server. A typical DNS query is shown here:
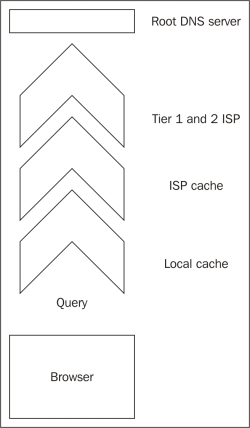
If a record doesn't exist on that server, then the request is propagated up a chain of DNS servers in an attempt to find one that knows about the domain. Eventually, the propagation stops at the root servers. These root servers are the stopping point for queries—if they don't know who is responsible for DNS information for a domain, then the lookup is deemed to have failed.
Once the browser has an address for the site, it opens up a connection and sends a request for the document. If no document is provided, then a / character is sent. Should the connection be a secure one, then negotiation of SSL/TSL is performed at this time. There is some computational expense to setting up an encrypted connection but this is slowly being fixed.
The server will respond with a blob of HTML. As the browser receives this HTML, it starts to process it; the browser does not wait for the entire HTML document to be downloaded before it goes to work. If the browser encounters a resource that is external to HTML, it will kick off a new request to open another connection to the web server and download that resource. The maximum number of connections to a single domain is limited so that the web server isn't flooded. It should also be mentioned that setting up a new connection to the web server carries overhead. The following diagram explains this process:
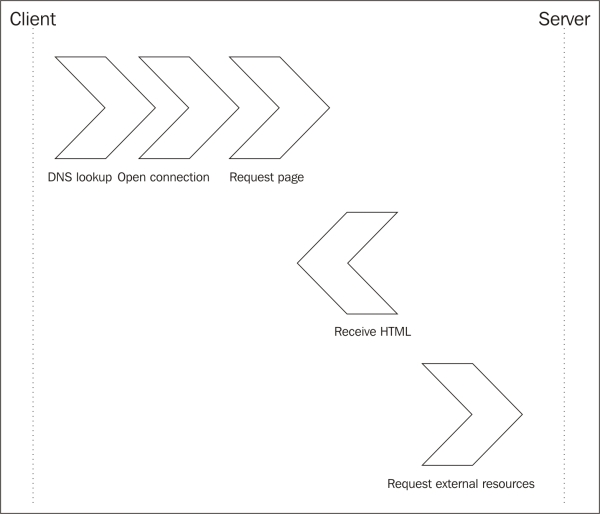
Connections to the web server should be limited to avoid paying the connection setup costs repeatedly. This brings us to our first concept: combining files.
If you've followed the advice to leverage namespaces and classes in your JavaScript, then putting all of your JavaScript together in a single file is a trivial step. One need only concatenate the files together and everything should continue to work as normal. Some minor care and attention may need to be paid to the order of inclusion but not typically.
The previous code we've written has been pretty much one file per pattern. If there is a need for multiple patterns to be used, then we could simply concatenate the files together. For instance, the combined builder and factory method patterns might look like this:
var Westeros;
(function (Westeros) {
(function (Religion) {
…
})(Westeros.Religion || (Westeros.Religion = {}));
var Religion = Westeros.Religion;
})(Westeros || (Westeros = {}));
(function (Westeros) {
var Tournament = (function () {
function Tournament() {
}
return Tournament;
})();
Westeros.Tournament = Tournament;
…
})();
Westeros.Attendee = Attendee;
})(Westeros || (Westeros = {}));The question may arise as to how much of your JavaScript should be combined and loaded at once. It is a surprisingly difficult question to answer. On one hand, it is desirable to front load all the JavaScript for the entire site when users first arrive at the site. This means that users will pay a price initially but will not have to download any additional JavaScript as they travel about the site. This is because the browser will cache the script and reuse it instead of downloading it from the server again. However, if users only visit a small subset of the pages on the site, then they would have loaded a great deal of JavaScript that was not needed.
On the other hand, splitting up the JavaScript means that additional page visits incur a penalty to retrieve additional JavaScript files. There is a sweet spot somewhere in the middle of these two approaches. Script can be organized into blocks that map to different sections of the website. This can be a place where using proper namespacing will come in handy once again. Each namespace can be combined into a single file and then loaded as users visit that part of the site.
In the end, the only approach that makes sense is to maintain statistics about how users move about the site. Based on this information, an optimal strategy to find the sweet spot can be established.
Minification
Combining JavaScript into a single file solves the problem of limiting the number of requests. However, each request may still be large. Again, we come to a schism between what makes code fast and readable by humans and what makes it fast and readable by computers.
We humans like descriptive variable names, bountiful whitespace, and proper indentation. Computers don't care about descriptive names, whitespace, or proper indentation. In fact, these things increase the size of the file and thus decrease the speed at which the code can be read.
Minification is a compile step that transforms the human readable code into smaller but equivalent code. External variables remain named the same as the minifier has no way to know what other code may be relying on the variable names remaining unchanged.
As an example, if we start with the composite code from Chapter 4, Structural Patterns, the minified code looks like this:
var Westros;(function(Westros){(function(Food){var SimpleIngredient=(function(){function SimpleIngredient(name,calories,ironContent,vitaminCContent){this.name=name;this.calories=calories;this.ironContent=ironContent;this.vitaminCContent=vitaminCContent}SimpleIngredient.prototype.GetName=function(){return this.name};SimpleIngredient.prototype.GetCalories=function(){return this.calories};SimpleIngredient.prototype.GetIronContent=function(){return this.ironContent};SimpleIngredient.prototype.GetVitaminCContent=function(){return this.vitaminCContent};return SimpleIngredient})();Food.SimpleIngredient=SimpleIngredient;var CompoundIngredient=(function(){function CompoundIngredient(name){this.name=name;this.ingredients=new Array()}CompoundIngredient.prototype.AddIngredient=function(ingredient){this.ingredients.push(ingredient)};CompoundIngredient.prototype.GetName=function(){return this.name};CompoundIngredient.prototype.GetCalories=function(){var total=0;for(var i=0;i<this.ingredients.length;i++){total+=this.ingredients[i].GetCalories()}return total};CompoundIngredient.prototype.GetIronContent=function(){var total=0;for(var i=0;i<this.ingredients.length;i++){total+=this.ingredients[i].GetIronContent()}return total};CompoundIngredient.prototype.GetVitaminCContent=function(){var total=0;for(var i=0;i<this.ingredients.length;i++){total+=this.ingredients[i].GetVitaminCContent()}return total};return CompoundIngredient})();Food.CompoundIngredient=CompoundIngredient})(Westros.Food||(Westros.Food={}));var Food=Westros.Food})(Westros||(Westros={}));You'll notice that all the spacing has been removed and that all the internal variables have been replaced with smaller versions. At the same time, you can spot that some well-known variable names have remained unchanged.
Minification shortened this particular piece of code by 40 percent. Compressing the content stream from the server using gzip, a popular approach, is lossless compression. That means that there is a perfect bijection between compressed and uncompressed. Minification, on the other hand, is a lossy compression. There is no way to get back to the unminified code from just the minified code once it has been minified.
Note
You can read more about gzip compression at http://betterexplained.com/articles/how-to-optimize-your-site-with-gzip-compression/.
If there is need to return to the original code, then source maps can be used. A source map is a file that provides a translation from one format of code to another. It can be loaded by the debugging tools in modern browsers to allow you to debug the original code instead of unintelligible minified code. Multiple source maps can be combined to allow for translation from, say, minified code to unminified JavaScript to TypeScript.
Content delivery networks
The final delivery trick is to make use of content delivery networks (CDNs). CDNs are distributed networks of hosts whose only purpose is to serve out static content. In much the same way that the browser will cache JavaScript between pages on the site, it will also cache JavaScript that is shared between multiple web servers. Thus, if your site makes use of jQuery, then pulling jQuery from a well-known CDN such as https://code.jquery.com or Microsoft's ASP.NET CDN may be faster as it is already cached. Pulling from a CDN also means that the content is coming from a different domain and doesn't count against the limited connections to your server. Referencing a CDN is as simple as setting the source of the script tag to point at the CDN.
Once again, some metrics will need to be gathered to see whether it is better to use a CDN or simply roll libraries into the JavaScript bundle. Examples of such metrics may include the added time to perform additional DNS lookup and the difference in the download sizes. The best approach is to use the timing APIs in the browser.
The long and short of distributing JavaScript to the browser is that experimentation is required. Testing a number of approaches and measuring the results will give the best result for end users.
Plugins
There are a great number of really impressively good JavaScript libraries in the wild. For me, the library that changed how I look at JavaScript was jQuery. For others, it may have been one of the other popular libraries such as MooTools, Dojo, Prototype, or YUI. However, jQuery has exploded in popularity and has, at the time of writing, won the JavaScript library wars. 78.5 percent of the top 10,000 websites by traffic on the Internet make use of some version of jQuery. None of the rest of the libraries even break 1 percent.
Many developers have seen fit to implement their own libraries on top of these foundational libraries in the form of plugins. A plugin typically modifies the prototype exposed by the library and adds additional functionality. The syntax is such that, to the end developer, it appears to be part of the core library.
How plugins are built vary depending on the library you're trying to extend. Nonetheless, let's take a look at how we can build a plugin for jQuery and then for one of my favorite libraries, d3. We'll see if we can extract some commonalities.
jQuery
At jQuery's core is the CSS selector library called Sizzle.js. It is Sizzle.js that is responsible for all the really nifty ways jQuery can select items on a page using CSS3 selectors. jQuery can be used to select elements on a page like this:
$(":input").css("background-color", "blue");What is returned is a jQuery object. The jQuery object acts a lot like, although not completely like, an array. This is achieved by creating a series of keys on the jQuery object numbered 0 to n - 1, where n is the number of elements matched by the selector. This is actually pretty smart, as it enables array like accessors, while also providing a bunch of additional functions:
$($(":input")[2]).css("background-color", "blue");The items at the indices are plain HTML elements and not wrapped with jQuery, hence the use of the second $() parameter.
For jQuery plugins, we typically want to make our plugins extend this jQuery object. Because it is dynamically created every time the selector is fired, we actually extend an object called $.fn. This object is used as the basis to create all jQuery objects. Thus creating a plugin that transforms all the text in inputs on the page into uppercase is nominally as simple as this:
$.fn.yeller = function(){
this.each(function(_, item){
$(item).val($(item).val().toUpperCase());
return this;
});
};This plugin is particularly useful to post to bulletin boards and for whenever my boss fills in a form. The plugin iterates over all the objects selected by the selector and converts their content to uppercase. It also returns this. By doing so, we allow chaining additional functions. You can use the function like this:
$(function(){$("input").yeller();});It does rather depend on the $ variable being assigned to jQuery. This isn't always the case, as $ is a popular variable in JavaScript libraries, likely because it is the only character that isn't a letter or a number and doesn't really have a special meaning.
To combat this, we can use an immediately evaluated function in much the same way we did way back in Chapter 2, Organizing Code:
(function($){
$.fn.yeller2 = function(){
this.each(function(_, item){
$(item).val($(item).val().toUpperCase());
return this;
});
};
})(jQuery);The added advantage here is that, should our code require helper functions or private variables, they can be set inside the same function. You can also pass in any options required. jQuery provides a very helpful $.extend function that copies properties between objects, making it ideal to extend a set of default options with those passed in. We looked at it in some detail in a previous chapter.
The jQuery plugin documentation recommends that the jQuery object be polluted as little as possible with plugins. This is to avoid conflicts between multiple plugins that want to use the same names. Their solution is to have a single function that has different behaviors depending on the parameters passed in. For instance, the jQuery UI plugin uses this approach for dialog:
$(".dialog").dialog("open");
$(".dialog").dialog("close");I would much rather call these like this:
$(".dialog").dialog().open();
$(".dialog").dialog().close();With dynamic languages, there really isn't a great deal of difference but I would much rather have well-named functions that can be discovered by tooling than magic strings.
d3
d3 is a great JavaScript library that is used to create and manipulate visualizations. For the most part, people use d3 in conjunction with scalable vector graphics to produce graphics such as the following hexbin graph by Mike Bostock:
d3 attempts to be unopinionated about the sorts of visualizations it creates. Thus, there is no built-in support to create bar charts. There is, however, a collection of plugins that can be added to d3 to enable a wide variety of graphs including the hexbin one shown in the preceding graph.
jQuery d3 places emphasis on creating chainable functions. For example, the following code is a snippet that creates a column chart. You can see that all the attributes are being set through chaining:
var svg = d3.select(containerId).append("svg")
var bar = svg.selectAll("g").data(data).enter().append("g");
bar.append("rect")
.attr("height", yScale.rangeBand()).attr("fill", function (d, _)
{
return colorScale.getColor(d);
})
.attr("stroke", function (d, _){
return colorScale.getColor(d);
})
.attr("y", function (d, i) {
return yScale(d.Id) + margins.height;
})The core of d3 is the d3 object. The d3 object contains a number of namespaces for layouts, scales geometry, and numerous others. As well as whole namespaces, there are functions to carry out array manipulation and loading data from external sources.
Creating a plugin for d3 starts with deciding where we're going to plug into the code. Let's build a plugin that creates a new color scale. A color scale is used to map a domain of values to a range of colors. For instance, we might wish to map the domain of four values below onto a range of four colors, as shown in the following diagram:
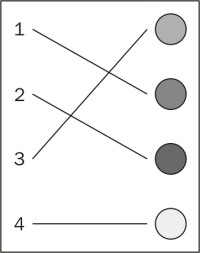
Let's plug in a function to provide a new color scale, in this case one that supports grouping elements. A scale is a function that maps a domain to a range; for a color scale, the range is a set of colors. An example might be a function that maps all even numbers to red and all odd to white. Using the following scale on a table would result in zebra striping:
d3.scale.groupedColorScale = function () {
var domain, range;
function scale(x) {
var rangeIndex = 0;
domain.forEach(function (item, index) {
if (item.indexOf(x) > 0)
rangeIndex = index;
});
return range[rangeIndex];
}
scale.domain = function (x) {
if (!arguments.length)
return domain;
domain = x;
return scale;
};
scale.range = function (x) {
if (!arguments.length)
return range;
range = x;
return scale;
};
return scale;
};We simply attach this plugin to the existing d3.scale object. This can be used by simply giving an array of arrays as a domain and an array as a range:
var s = d3.scale.groupedColorScale().domain([[1, 2, 3], [4, 5]]).range(["#111111", "#222222"]); s(3); //#111111 s(4); //#222222
This simple plugin extends the functionality of d3's scale. We could have replaced the existing functionality or even wrapped it such that calls to the existing functionality would be proxied through our plugin.
Plugins are generally not that difficult to build but they do vary from library to library. It is important to keep an eye on the existing variable names in libraries so we don't end up clobbering them or even clobbering the functionality provided by other plugins. Some suggest prefixing functions with a string to avoid clobbering.
If the library has been designed with plugins in mind, there may be additional places to which we can hook. A popular approach is to provide an options object that contains optional fields to hook in our own functions as event handlers. If nothing is provided, the function continues as normal.
jQuery
At jQuery's core is the CSS selector library called Sizzle.js. It is Sizzle.js that is responsible for all the really nifty ways jQuery can select items on a page using CSS3 selectors. jQuery can be used to select elements on a page like this:
$(":input").css("background-color", "blue");What is returned is a jQuery object. The jQuery object acts a lot like, although not completely like, an array. This is achieved by creating a series of keys on the jQuery object numbered 0 to n - 1, where n is the number of elements matched by the selector. This is actually pretty smart, as it enables array like accessors, while also providing a bunch of additional functions:
$($(":input")[2]).css("background-color", "blue");The items at the indices are plain HTML elements and not wrapped with jQuery, hence the use of the second $() parameter.
For jQuery plugins, we typically want to make our plugins extend this jQuery object. Because it is dynamically created every time the selector is fired, we actually extend an object called $.fn. This object is used as the basis to create all jQuery objects. Thus creating a plugin that transforms all the text in inputs on the page into uppercase is nominally as simple as this:
$.fn.yeller = function(){
this.each(function(_, item){
$(item).val($(item).val().toUpperCase());
return this;
});
};This plugin is particularly useful to post to bulletin boards and for whenever my boss fills in a form. The plugin iterates over all the objects selected by the selector and converts their content to uppercase. It also returns this. By doing so, we allow chaining additional functions. You can use the function like this:
$(function(){$("input").yeller();});It does rather depend on the $ variable being assigned to jQuery. This isn't always the case, as $ is a popular variable in JavaScript libraries, likely because it is the only character that isn't a letter or a number and doesn't really have a special meaning.
To combat this, we can use an immediately evaluated function in much the same way we did way back in Chapter 2, Organizing Code:
(function($){
$.fn.yeller2 = function(){
this.each(function(_, item){
$(item).val($(item).val().toUpperCase());
return this;
});
};
})(jQuery);The added advantage here is that, should our code require helper functions or private variables, they can be set inside the same function. You can also pass in any options required. jQuery provides a very helpful $.extend function that copies properties between objects, making it ideal to extend a set of default options with those passed in. We looked at it in some detail in a previous chapter.
The jQuery plugin documentation recommends that the jQuery object be polluted as little as possible with plugins. This is to avoid conflicts between multiple plugins that want to use the same names. Their solution is to have a single function that has different behaviors depending on the parameters passed in. For instance, the jQuery UI plugin uses this approach for dialog:
$(".dialog").dialog("open");
$(".dialog").dialog("close");I would much rather call these like this:
$(".dialog").dialog().open();
$(".dialog").dialog().close();With dynamic languages, there really isn't a great deal of difference but I would much rather have well-named functions that can be discovered by tooling than magic strings.
d3
d3 is a great JavaScript library that is used to create and manipulate visualizations. For the most part, people use d3 in conjunction with scalable vector graphics to produce graphics such as the following hexbin graph by Mike Bostock:
d3 attempts to be unopinionated about the sorts of visualizations it creates. Thus, there is no built-in support to create bar charts. There is, however, a collection of plugins that can be added to d3 to enable a wide variety of graphs including the hexbin one shown in the preceding graph.
jQuery d3 places emphasis on creating chainable functions. For example, the following code is a snippet that creates a column chart. You can see that all the attributes are being set through chaining:
var svg = d3.select(containerId).append("svg")
var bar = svg.selectAll("g").data(data).enter().append("g");
bar.append("rect")
.attr("height", yScale.rangeBand()).attr("fill", function (d, _)
{
return colorScale.getColor(d);
})
.attr("stroke", function (d, _){
return colorScale.getColor(d);
})
.attr("y", function (d, i) {
return yScale(d.Id) + margins.height;
})The core of d3 is the d3 object. The d3 object contains a number of namespaces for layouts, scales geometry, and numerous others. As well as whole namespaces, there are functions to carry out array manipulation and loading data from external sources.
Creating a plugin for d3 starts with deciding where we're going to plug into the code. Let's build a plugin that creates a new color scale. A color scale is used to map a domain of values to a range of colors. For instance, we might wish to map the domain of four values below onto a range of four colors, as shown in the following diagram:
Let's plug in a function to provide a new color scale, in this case one that supports grouping elements. A scale is a function that maps a domain to a range; for a color scale, the range is a set of colors. An example might be a function that maps all even numbers to red and all odd to white. Using the following scale on a table would result in zebra striping:
d3.scale.groupedColorScale = function () {
var domain, range;
function scale(x) {
var rangeIndex = 0;
domain.forEach(function (item, index) {
if (item.indexOf(x) > 0)
rangeIndex = index;
});
return range[rangeIndex];
}
scale.domain = function (x) {
if (!arguments.length)
return domain;
domain = x;
return scale;
};
scale.range = function (x) {
if (!arguments.length)
return range;
range = x;
return scale;
};
return scale;
};We simply attach this plugin to the existing d3.scale object. This can be used by simply giving an array of arrays as a domain and an array as a range:
var s = d3.scale.groupedColorScale().domain([[1, 2, 3], [4, 5]]).range(["#111111", "#222222"]); s(3); //#111111 s(4); //#222222
This simple plugin extends the functionality of d3's scale. We could have replaced the existing functionality or even wrapped it such that calls to the existing functionality would be proxied through our plugin.
Plugins are generally not that difficult to build but they do vary from library to library. It is important to keep an eye on the existing variable names in libraries so we don't end up clobbering them or even clobbering the functionality provided by other plugins. Some suggest prefixing functions with a string to avoid clobbering.
If the library has been designed with plugins in mind, there may be additional places to which we can hook. A popular approach is to provide an options object that contains optional fields to hook in our own functions as event handlers. If nothing is provided, the function continues as normal.
d3
d3 is a great JavaScript library that is used to create and manipulate visualizations. For the most part, people use d3 in conjunction with scalable vector graphics to produce graphics such as the following hexbin graph by Mike Bostock:
d3 attempts to be unopinionated about the sorts of visualizations it creates. Thus, there is no built-in support to create bar charts. There is, however, a collection of plugins that can be added to d3 to enable a wide variety of graphs including the hexbin one shown in the preceding graph.
jQuery d3 places emphasis on creating chainable functions. For example, the following code is a snippet that creates a column chart. You can see that all the attributes are being set through chaining:
var svg = d3.select(containerId).append("svg")
var bar = svg.selectAll("g").data(data).enter().append("g");
bar.append("rect")
.attr("height", yScale.rangeBand()).attr("fill", function (d, _)
{
return colorScale.getColor(d);
})
.attr("stroke", function (d, _){
return colorScale.getColor(d);
})
.attr("y", function (d, i) {
return yScale(d.Id) + margins.height;
})The core of d3 is the d3 object. The d3 object contains a number of namespaces for layouts, scales geometry, and numerous others. As well as whole namespaces, there are functions to carry out array manipulation and loading data from external sources.
Creating a plugin for d3 starts with deciding where we're going to plug into the code. Let's build a plugin that creates a new color scale. A color scale is used to map a domain of values to a range of colors. For instance, we might wish to map the domain of four values below onto a range of four colors, as shown in the following diagram:
Let's plug in a function to provide a new color scale, in this case one that supports grouping elements. A scale is a function that maps a domain to a range; for a color scale, the range is a set of colors. An example might be a function that maps all even numbers to red and all odd to white. Using the following scale on a table would result in zebra striping:
d3.scale.groupedColorScale = function () {
var domain, range;
function scale(x) {
var rangeIndex = 0;
domain.forEach(function (item, index) {
if (item.indexOf(x) > 0)
rangeIndex = index;
});
return range[rangeIndex];
}
scale.domain = function (x) {
if (!arguments.length)
return domain;
domain = x;
return scale;
};
scale.range = function (x) {
if (!arguments.length)
return range;
range = x;
return scale;
};
return scale;
};We simply attach this plugin to the existing d3.scale object. This can be used by simply giving an array of arrays as a domain and an array as a range:
var s = d3.scale.groupedColorScale().domain([[1, 2, 3], [4, 5]]).range(["#111111", "#222222"]); s(3); //#111111 s(4); //#222222
This simple plugin extends the functionality of d3's scale. We could have replaced the existing functionality or even wrapped it such that calls to the existing functionality would be proxied through our plugin.
Plugins are generally not that difficult to build but they do vary from library to library. It is important to keep an eye on the existing variable names in libraries so we don't end up clobbering them or even clobbering the functionality provided by other plugins. Some suggest prefixing functions with a string to avoid clobbering.
If the library has been designed with plugins in mind, there may be additional places to which we can hook. A popular approach is to provide an options object that contains optional fields to hook in our own functions as event handlers. If nothing is provided, the function continues as normal.
Doing two things at once – multithreading
Doing two things at once is hard. For many years, the solution in the computer world was to use either multiple processes or multiple threads. The difference between the two is fuzzy due to implementation differences on different operating systems but threads are typically lighter weight versions of processes. JavaScript on the browser supports neither of these approaches.
Historically, there has been no real need for multithreading on the browser. JavaScript was used to manipulate the user interface. When manipulating a UI, even in other languages and windowing environments, only one thread is permitted to act at a time. This avoids race conditions that would be very obvious to users.
However, as JavaScript grows in popularity, more and more complicated software is being written to run inside the browser. Sometimes, that software could really benefit from performing complex calculations in the background.
Web workers provide a mechanism to do two things at once in a browser. Although a fairly recent innovation, web workers now have good support in mainstream browsers. In effect, a worker is a background thread that can communicate with the main thread using messages. Web workers must be self-contained in a single JavaScript file.
To make use of web workers is fairly easy. We'll revisit our example from a few chapters ago when we looked at the Fibonacci sequence. The worker process listens for messages like this:
self.addEventListener('message', function(e) {
var data = e.data;
if(data.cmd == 'startCalculation'){
self.postMessage({event: 'calculationStarted'});
var result = fib(data.parameters.number);
self.postMessage({event: 'calculationComplete', result: result});
};
}, false);Here we start a new instance of fib any time we get a startCalculation message. fib is simply the naive implementation from earlier.
The main thread loads the worker process from its external file and attaches a number of listeners:
function startThread(){
worker = new Worker("worker.js");
worker.addEventListener('message', function(message) {
logEvent(message.data.event);
if(message.data.event == "calculationComplete"){
writeResult(message.data.result);
}
if(message.data.event == "calculationStarted"){
document.getElementById("result").innerHTML = "working";
}
});
};In order to start the calculation, all that is needed is to send a command:
worker.postMessage({cmd: 'startCalculation', parameters: { number: 40}});Here we pass the number of the term in the sequence we want to calculate. While the calculation is running in the background, the main thread is free to do whatever it likes. When the message is received back from the worker, it is placed in the normal event loop to be processed, as shown in the following diagram:
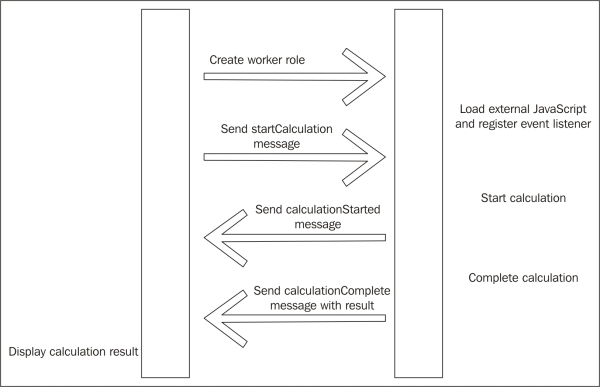
Web workers may be useful to you if you have to do any time-consuming calculations in JavaScript.
If you're making use of server-side JavaScript through the use of Node.js, then there is a different approach to doing more than one thing at a time. Node.js offers the ability to fork child processes and provides an interface not dissimilar to the web worker one to communicate between the child and parent processes. This method forks an entire process, though, which is much more resource intensive than using lightweight threads.
Some other tools exist that create lighter weight background workers in Node.js. These are probably a closer parallel to what exists on the client side than forking a child process.
The circuit breaker pattern
Systems, even the best designed systems, fail. The larger and more distributed a system, the higher the probability of failure. Many large systems such as Netflix or Google have extensive built-in redundancies. The redundancies don't decrease the chance of a failure of a component, but they do provide a backup. Switching to the backup is frequently transparent to the end user.
The circuit breaker pattern is a common component of a system that provides this sort of redundancy. Let's say that your application queries an external data source every five seconds; perhaps you're polling for some data that you're expecting to change. What happens when this polling fails? In many cases, the failure is simply ignored and the polling continues. This is actually a pretty good behavior on the client side as data updates are not always crucial. In some cases, a failure will cause the application to retry the request immediately. Retrying server requests in a tight loop can be problematic for both the client and the server. The client may become unresponsive as it spends more time in a loop requesting data.
On the server side, a system that is attempting to recover from a failure is being slammed every five seconds by, what could be, thousands of clients. If the failure is due to the system being overloaded, then continuing to query it will only make matters worse.
The circuit breaker pattern stops attempting to communicate with a system that is failing once a certain number of failures have been reached. Basically, repeated failures result in the circuit being broken and the application ceasing to query, as shown in the following diagram:
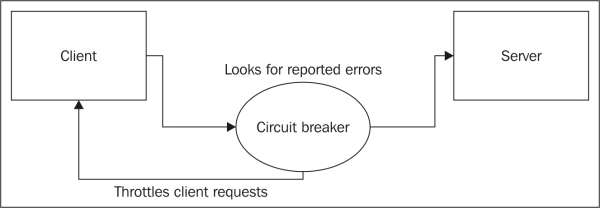
For the server, having the number of clients drop off as failures pile up allows for some breathing room to recover. The chances of a storm of requests coming in and keeping the system down is minimized.
Of course, we would like the circuit breaker to reset at some point so that the service can be restored. The two approaches for this are that either the client polls periodically (less frequently than before) and resets the breaker or that the external system communicates back to its clients that the service has been restored.
Back-off
A variation on the circuit breaker pattern is to use some form of back-off instead of cutting out communication to the server completely. This is an approach that is suggested by many database vendors and cloud providers. If our original polling was a 5-second interval, then when a failure is detected, change the interval to every 10 seconds. Repeat this process using longer and longer intervals.
When requests start to work again, then the pattern of changing the time interval is reversed. Requests are sent closer and closer together until the original polling interval is resumed.
Monitoring the status of the external resource availability is a perfect place to use background worker roles. The work is not complex but it is totally detached from the main event loop.
Again, this reduces the load on the external resource, giving it more breathing room. It also keeps the clients unburdened by too much polling.
An example using jQuery's ajax function looks like the following code:
$.ajax({
url : 'someurl',
type : 'POST',
data : ....,
tryCount : 0,
retryLimit : 3,
success : function(json) {
//do something
},
error : function(xhr, textStatus, errorThrown ) {
if (textStatus == 'timeout') {
this.tryCount++;
if (this.tryCount <= this.retryLimit) {
//try again
$.ajax(this);
return;
}
return;
}
if (xhr.status == 500) {
//handle error
} else {
//handle error
}
}
});You can see that the highlighted section retries the query.
This style of back-off is actually used in Ethernet to avoid repeated packet collisions.
Degraded application behavior
There is likely a very good reason that your application is calling out to external resources. Backing off and not querying the data source is perfectly reasonable but it is still desirable that users have some ability to interact with the site. One solution to this problem is to degrade the behavior of the application.
For instance, if your application shows real-time stock quote information but the system to deliver stock information is broken, then a less than real-time service could be swapped in. Modern browsers have a whole raft of different technologies that allow storing small quantities of data on the client computer. This storage space is ideal to cache old versions of some data should the latest versions be unavailable.
Even in cases where the application is sending data to the server, it is possible to degrade behavior. Saving the data updates locally and then sending them en masse when the service is restored is generally acceptable. Of course, once a user leaves a page, then any background works will terminate. If the user never returns to the site, then whatever updates they had queued to send to the server will be lost.
Note
A word of warning: If this is an approach you take, it might be best to warn users that their data is old—especially if your application is a stock trading application.
Back-off
A variation on the circuit breaker pattern is to use some form of back-off instead of cutting out communication to the server completely. This is an approach that is suggested by many database vendors and cloud providers. If our original polling was a 5-second interval, then when a failure is detected, change the interval to every 10 seconds. Repeat this process using longer and longer intervals.
When requests start to work again, then the pattern of changing the time interval is reversed. Requests are sent closer and closer together until the original polling interval is resumed.
Monitoring the status of the external resource availability is a perfect place to use background worker roles. The work is not complex but it is totally detached from the main event loop.
Again, this reduces the load on the external resource, giving it more breathing room. It also keeps the clients unburdened by too much polling.
An example using jQuery's ajax function looks like the following code:
$.ajax({
url : 'someurl',
type : 'POST',
data : ....,
tryCount : 0,
retryLimit : 3,
success : function(json) {
//do something
},
error : function(xhr, textStatus, errorThrown ) {
if (textStatus == 'timeout') {
this.tryCount++;
if (this.tryCount <= this.retryLimit) {
//try again
$.ajax(this);
return;
}
return;
}
if (xhr.status == 500) {
//handle error
} else {
//handle error
}
}
});You can see that the highlighted section retries the query.
This style of back-off is actually used in Ethernet to avoid repeated packet collisions.
Degraded application behavior
There is likely a very good reason that your application is calling out to external resources. Backing off and not querying the data source is perfectly reasonable but it is still desirable that users have some ability to interact with the site. One solution to this problem is to degrade the behavior of the application.
For instance, if your application shows real-time stock quote information but the system to deliver stock information is broken, then a less than real-time service could be swapped in. Modern browsers have a whole raft of different technologies that allow storing small quantities of data on the client computer. This storage space is ideal to cache old versions of some data should the latest versions be unavailable.
Even in cases where the application is sending data to the server, it is possible to degrade behavior. Saving the data updates locally and then sending them en masse when the service is restored is generally acceptable. Of course, once a user leaves a page, then any background works will terminate. If the user never returns to the site, then whatever updates they had queued to send to the server will be lost.
Note
A word of warning: If this is an approach you take, it might be best to warn users that their data is old—especially if your application is a stock trading application.
Degraded application behavior
There is likely a very good reason that your application is calling out to external resources. Backing off and not querying the data source is perfectly reasonable but it is still desirable that users have some ability to interact with the site. One solution to this problem is to degrade the behavior of the application.
For instance, if your application shows real-time stock quote information but the system to deliver stock information is broken, then a less than real-time service could be swapped in. Modern browsers have a whole raft of different technologies that allow storing small quantities of data on the client computer. This storage space is ideal to cache old versions of some data should the latest versions be unavailable.
Even in cases where the application is sending data to the server, it is possible to degrade behavior. Saving the data updates locally and then sending them en masse when the service is restored is generally acceptable. Of course, once a user leaves a page, then any background works will terminate. If the user never returns to the site, then whatever updates they had queued to send to the server will be lost.
Note
A word of warning: If this is an approach you take, it might be best to warn users that their data is old—especially if your application is a stock trading application.
The promise pattern
I said earlier that JavaScript is single threaded. This is not entirely accurate. There is a single event loop in JavaScript. Blocking this event loop with a long running process is considered to be bad form. Nothing else can happen while your greedy algorithm is taking up all the CPU cycles.
When you launch an asynchronous function in JavaScript, such as fetching data from a remote server, then much of this activity happens in a different thread. The success or failure handler functions are executed in the main event thread. This is part of the reason that success handlers are written as functions: it allows them to be easily passed back and forth between contexts.
Thus, there are activities that truly do happen in an asynchronous, parallel fashion. When the async method has completed, then the result is passed into the handler we provided and the handler is put into the event queue to be picked up next time the event loop repeats. Typically, the event loop runs many hundreds or thousands of times a second, depending on how much work there is to do on each iteration.
Syntactically, we write the message handlers as functions and hook them up:
var xmlhttp = new XMLHttpRequest();
xmlhttp.onreadystatechange = function() {
if (xmlhttp.readyState === 4){
alert(xmlhttp.readyState);
}
;};This is reasonable if the situation is simple. However, if you would like to perform some additional asynchronous actions with the results of the callback, then you end up with nested callbacks. If you need to add error handling, that too is done using callbacks. The complexity of waiting for multiple callbacks to return and orchestrating your response rises quickly.
The promise pattern provides some syntactic help to clean up the asynchronous difficulties. If we take a common asynchronous operation such as retrieving data over XMLHttpRequest using jQuery, then the code takes both an error and a success function. It might look something like this:
$.ajax("/some/url",
{ success: function(data, status){},
error: function(jqXHR, status){}
});Using a promise instead would transform the code to look more like this:
$.ajax("/some/url").then(successFunction, errorFunction);In this case, the $.ajax method returns a promise object that contains a value and a state. The value is populated when the async call completes. The status provides some information about the current state of the request: has it completed, was it successful?
The promise also has a number of functions called on it. The then() function takes a success and an error function; it returns an additional promise. Should the success function run synchronously, then the promise is returned as already fulfilled. Otherwise, it remains in a working state, known as pending, until the asynchronous success has fired.
In my mind, the method in which jQuery implements promises is not ideal. Their error handing doesn't properly distinguish between a promise that has failed to be fulfilled and a promise that has failed but has been handled. This renders jQuery promises incompatible with the general idea of promises. For instance, it is not possible to use the following code:
$.ajax("/some/url").then(
function(data, status){},
function(jqXHR, status){
//handle the error here and return a new promise
}
).then(/*continue*/);Even though the error has been handled and a new promise has been returned, processing will discontinue. It would be much better if the function could be written as:
$.ajax("/some/url").then(function(data, status){})
.catch(function(jqXHR, status){
//handle the error here and return a new promise
})
.then(/*continue*/);There has been much discussion about the implementation of promises in jQuery and other libraries. As a result of this discussion, the current proposed promise specification is different from jQuery's promises and is incompatible. Promises/A+ is the certification that is met by numerous promise libraries such as When.js and Q, which also form the foundation of the specification of the promises that will be fulfilled by ECMAScript 6.
Promises provide a bridge between synchronous and asynchronous functions, in effect turning the asynchronous functions into something that can be manipulated as if it were synchronous.
If promises sound a lot like the lazy evaluation pattern we saw some chapters ago, then you're exactly correct. Promises are constructed using lazy evaluation; the actions called on them are queued inside the object rather than being evaluated at once. This is a wonderful application of a functional pattern and even enables scenarios like this:
when(function(){return 2+2;})
.delay(1000)
.then(function(promise){ console.log(promise());})Promises greatly simplify asynchronous programming in JavaScript and should certainly be considered for any project that is heavily asynchronous in nature.
Hints and tips
ECMAScript 6 promises are not, at the time of this writing, available on all browsers or JavaScript environments. There are some great shims out there that can add the functionality with a minimum of overhead.
When examining the performance of retrieving JavaScript from a remote server, there are tools provided in most modern browsers to view a timeline of resource loading. This timeline will show when the browser is waiting for scripts to be downloaded and when it is parsing the scripts. Using this timeline allows us to experiment and find the best way to load a script or series of scripts.
Summary
In this chapter, we've looked at a number of patterns or approaches that improve the experience of developing JavaScript. We looked at a number of concerns around delivery to the browser. We also looked at how to implement plugins against a couple of libraries and extrapolated general practices. Next, we took a look at how to work with background processes in JavaScript. Circuit breakers were suggested as a method of keeping remote resource fetching sane. Finally, we examined how promises can improve the writing of asynchronous code.
In the next chapter, we'll spend quite a bit more time looking at messaging patterns. We saw a little about messing with web workers, but we'll expand quite heavily on them in the next section.



