






















































Updating data in Elasticsearch
In this recipe, we will explore how to update data in Elasticsearch using the Python client.
Getting ready
Ensure that you have installed the Elasticsearch Python client and have successfully set up a connection to your Elasticsearch cluster (refer to the Adding data from the Elasticsearch client recipe). You will also need to have completed the previous recipe, which involves ingesting a document into the movies index.
Note
The following three recipes will use the same set of requirements.
How to do it…
In this recipe, we’re going to update the director field of a particular document within the movies index. The director field will be changed from its current value, D.W. Griffith, to a new value, Clint Eastwood. The following are the steps you’ll need to follow in your Python script to perform this update and confirm that it has been successfully applied. Let’s inspect the Python script that we will use to update the ingested document (https://github.com/PacktPublishing/Elastic-Stack-8.x-Cookbook/blob/main/Chapter2/python-client-sample/sampledata_update.py):
- First, we need to retrieve the document ID of the previously ingested document from the
tmp.txtfile, which we intend to update. The field to update here isdirector; we are going to update the value fromD.W. GriffithtoClint Eastwood:index_name = 'movies' document_id = '' # Read the document_id the ingested document of the previous recipe with open('tmp.txt', 'r') as file: document_id = file.read() document = { 'director': 'Clint Eastwood' } - We can now check
document_id, verify that the document exists in the index, and then perform theupdateoperation:# Update the document in Elasticsearch if document_id is valid if document_id != '': if es.exists(index=index_name, id=document_id): response = es.update(index=index_name, id=document_id, doc=document) print(f"Update status: {response['result']}") - Once the document is updated, to verify that the update is successful, you can retrieve the updated document from Elasticsearch and print the modified fields:
updated_document = es.get(index=index_name, id=document_id) print("Updated document:") print(updated_document) - After inspecting the script, let’s run it with the following command:
$ python sampledata_update.py
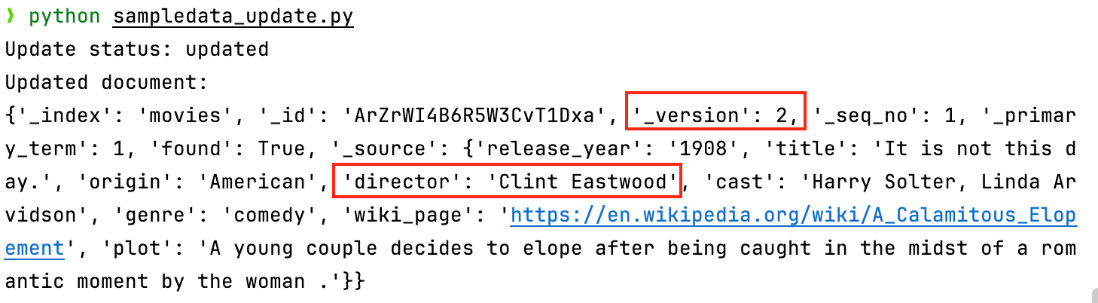
Figure 2.6 – The output of the sampledata_update.py script
You should see that the _version and director fields are updated.
How it works...
Each document includes a _version field in Elasticsearch. Elasticsearch documents cannot be modified directly, as they are immutable. When you update an existing document, a new document is generated with an incremented version, while the previous document is flagged for deletion.
There’s more…
We have just seen how to update a single document in Elasticsearch; in general, this is not optimal from a performance point of view. To update multiple documents that match a specific query, you can use the Update By Query API. This allows you to define a query to select the documents you want to update and specify the changes to be made; here is an example of how to do it via Elasticsearch’s REST API:
q = {
"script": {
"source": "ctx._source.genre = 'comedies'",
"lang": "painless"
},
"query": {
"bool": {
"must": [
{
"term": {
"genre": "comedy"
}
}
]
}
}
}
es.update_by_query(body=q, index=index_name) The full Python script is available here: https://github.com/PacktPublishing/Elastic-Stack-8.x-Cookbook/blob/main/Chapter2/python-client-sample/sampledata_update_by_query.py.
Note
The script used here is based on a painless script; we will see more examples in Chapter 6.
The other way to update multiple documents in a single request is via Elasticsearch’s Bulk API. The Bulk API can be used to insert, update, and delete multiple documents efficiently. We will learn how to use the Bulk API to ingest multiple documents at the end of this chapter. For more detailed information, refer to the following documentation: https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk.html.
To retrieve the ID of the document we want to update, we rely on a tmp.txt file where the ID of a previously created document was saved. Alternatively, you can retrieve the document’s ID by using the Dev Tools in Kibana, perform a search on the movies index, go to Kibana | Dev Tools, and execute the following command:
GET movies/_search
This query should return a list of hits that display all documents in the index, along with their respective IDs, as shown in Figure 2.7. Using these results, locate and record the ID of the document you would like to update:
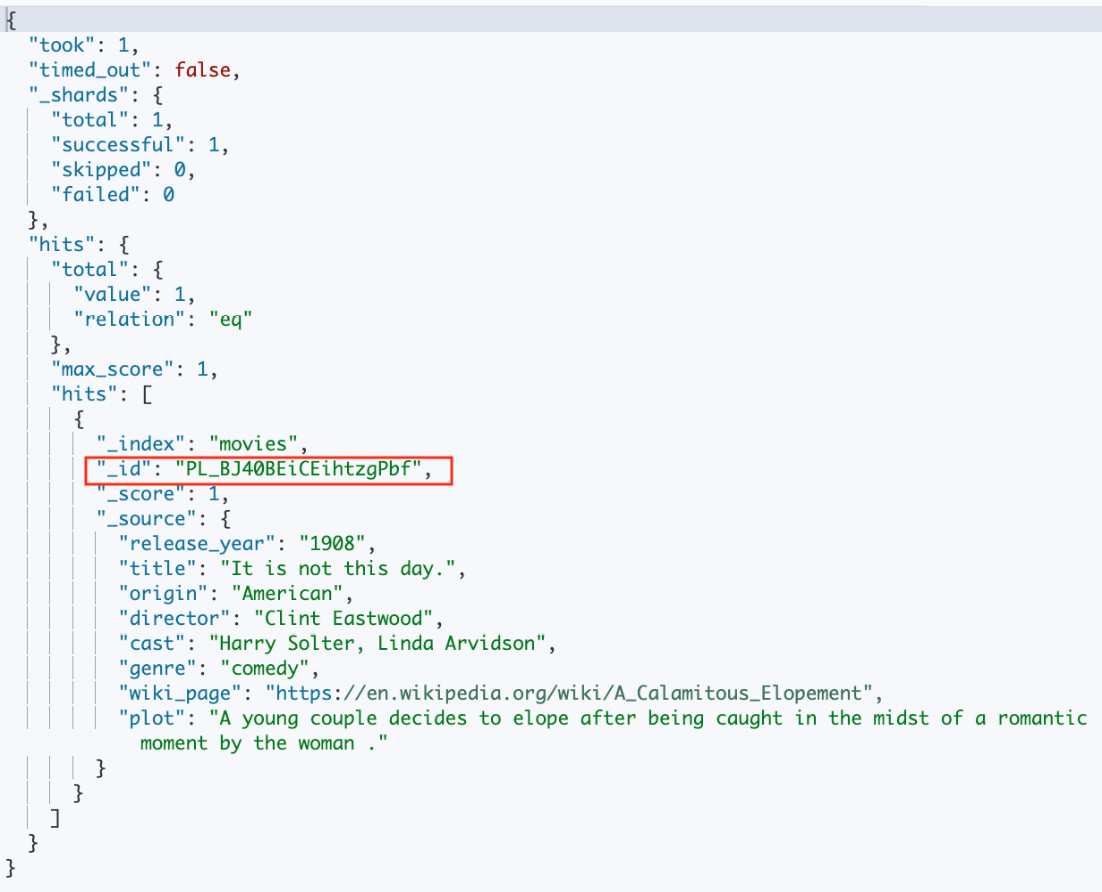
Figure 2.7 – Checking the document ID










