























































The OpenAI Gym API
The Python library called Gym was developed and has been maintained by OpenAI (www.openai.com). The main goal of Gym is to provide a rich collection of environments for RL experiments using a unified interface. So, it is not surprising that the central class in the library is an environment, which is called Env. Instances of this class expose several methods and fields that provide the required information about its capabilities. At a high level, every environment provides these pieces of information and functionality:
- A set of actions that is allowed to be executed in the environment. Gym supports both discrete and continuous actions, as well as their combination
- The shape and boundaries of the observations that the environment provides the agent with
- A method called
stepto execute an action, which returns the current observation, the reward, and the indication that the episode is over - A method called
reset, which returns the environment to its initial state and obtains the first observation
Let's now talk about these components of the environment in detail.
The action space
As mentioned, the actions that an agent can execute can be discrete, continuous, or a combination of the two. Discrete actions are a fixed set of things that an agent can do, for example, directions in a grid like left, right, up, or down. Another example is a push button, which could be either pressed or released. Both states are mutually exclusive, because a main characteristic of a discrete action space is that only one action from a finite set of actions is possible.
A continuous action has a value attached to it, for example, a steering wheel, which can be turned at a specific angle, or an accelerator pedal, which can be pressed with different levels of force. A description of a continuous action includes the boundaries of the value that the action could have. In the case of a steering wheel, it could be from −720 degrees to 720 degrees. For an accelerator pedal, it's usually from 0 to 1.
Of course, we are not limited to a single action; the environment could take multiple actions, such as pushing multiple buttons simultaneously or steering the wheel and pressing two pedals (the brake and the accelerator). To support such cases, Gym defines a special container class that allows the nesting of several action spaces into one unified action.
The observation space
As mentioned in Chapter 1, What Is Reinforcement Learning?, observations are pieces of information that an environment provides the agent with, on every timestamp, besides the reward. Observations can be as simple as a bunch of numbers or as complex as several multidimensional tensors containing color images from several cameras. An observation can even be discrete, much like action spaces. An example of a discrete observation space is a lightbulb, which could be in two states – on or off, given to us as a Boolean value.
So, you can see the similarity between actions and observations, and how they have found their representation in Gym's classes. Let's look at a class diagram:
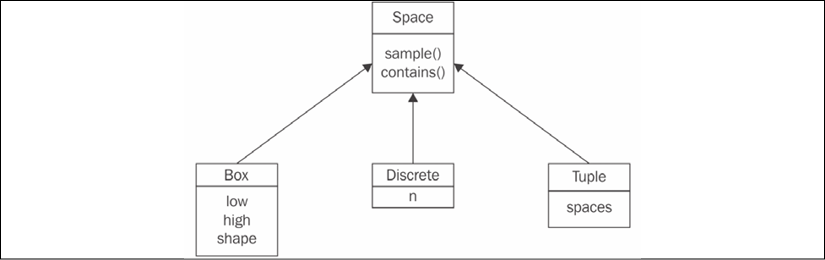
Figure 2.1: The hierarchy of the Space class in Gym
The basic abstract class Space includes two methods that are relevant to us:
sample(): This returns a random sample from the spacecontains(x): This checks whether the argument,x, belongs to the space's domain
Both of these methods are abstract and reimplemented in each of the Space subclasses:
- The
Discreteclass represents a mutually exclusive set of items, numbered from 0 to n – 1. Its only field, n, is a count of the items it describes. For example,Discrete(n=4)can be used for an action space of four directions to move in [left, right, up, or down]. - The
Boxclass represents an n-dimensional tensor of rational numbers with intervals [low, high]. For instance, this could be an accelerator pedal with one single value between0.0and1.0, which could be encoded byBox(low=0.0, high=1.0, shape=(1,), dtype=np.float32)(theshapeargument is assigned a tuple of length1with a single value of1, which gives us a one-dimensional tensor with a single value). Thedtypeparameter specifies the space's value type and here we specify it as aNumPy 32-bit float. Another example ofBoxcould be an Atari screen observation (we will cover lots of Atari environments later), which is an RGB (red, green, and blue) image of size 210×160:Box(low=0, high=255, shape=(210, 160, 3), dtype=np.uint8). In this case, theshapeargument is a tuple of three elements: the first dimension is the height of the image, the second is the width, and the third equals3, which all correspond to three color planes for red, green, and blue, respectively. So, in total, every observation is a three-dimensional tensor with 100,800 bytes. - The final child of
Spaceis aTupleclass, which allows us to combine severalSpaceclass instances together. This enables us to create action and observation spaces of any complexity that we want. For example, imagine we want to create an action space specification for a car. The car has several controls that can be changed at every timestamp, including the steering wheel angle, brake pedal position, and accelerator pedal position. These three controls can be specified by three float values in one singleBoxinstance. Besides these essential controls, the car has extra discrete controls, like a turn signal (which could be off, right, or left) or horn (on or off). To combine all of this into one action space specification class, we can createTuple(spaces=(Box(low=-1.0, high=1.0, shape=(3,), dtype=np.float32), Discrete(n=3),Discrete(n=2))). This flexibility is rarely used; for example, in this book, you will see only theBoxandDiscreteactions and observation spaces, but theTupleclass can be useful in some cases.
There are other Space subclasses defined in Gym, but the preceding three are the most useful ones. All subclasses implement the sample() and contains() methods. The sample() function performs a random sample corresponding to the Space class and parameters. This is mostly useful for action spaces, when we need to choose the random action. The contains() method verifies that the given arguments comply with the Space parameters, and it is used in the internals of Gym to check an agent's actions for sanity. For example, Discrete.sample() returns a random element from a discrete range, and Box.sample() will be a random tensor with proper dimensions and values lying inside the given range.
Every environment has two members of type Space: the action_space and observation_space. This allows us to create generic code that could work with any environment. Of course, dealing with the pixels of the screen is different from handling discrete observations (as in the former case, we may want to preprocess images with convolutional layers or with other methods from the computer vision toolbox); so, most of the time, this means optimizing the code for a particular environment or group of environments, but Gym doesn't prevent us from writing generic code.
The environment
The environment is represented in Gym by the Env class, as mentioned earlier, which has the following members:
action_space: This is the field of theSpaceclass and provides a specification for allowed actions in the environment.observation_space: This field has the sameSpaceclass, but specifies the observations provided by the environment.reset(): This resets the environment to its initial state, returning the initial observation vector.step(): This method allows the agent to take the action and returns information about the outcome of the action – the next observation, the local reward, and the end-of-episode flag. This method is a bit complicated and we we will look at it in detail later in this section.
There are extra utility methods in the Env class, such as render(), which allows us to obtain the observation in a human-friendly form, but we won't use them. You can find the full list in Gym's documentation, but let's focus on the core Env methods: reset() and step().
So far, you have seen how our code can get information about the environment's actions and observations, so now you need to get familiar with actioning itself. Communications with the environment are performed via step and reset.
As reset is much simpler, we will start with it. The reset() method has no arguments; it instructs an environment to reset into its initial state and obtain the initial observation. Note that you have to call reset() after the creation of the environment. As you may remember from Chapter 1, What Is Reinforcement Learning?, the agent's communication with the environment may have an end (like a "Game Over" screen). Such sessions are called episodes, and after the end of the episode, an agent needs to start over. The value returned by this method is the first observation of the environment.
The step() method is the central piece in the environment's functionality. It does several things in one call, which are as follows:
- Telling the environment which action we will execute on the next step
- Getting the new observation from the environment after this action
- Getting the reward the agent gained with this step
- Getting the indication that the episode is over
The first item (action) is passed as the only argument to this method, and the rest are returned by the step() method. Precisely, this is a tuple (Python tuple and not the Tuple class we discussed in the previous section) of four elements (observation, reward, done, and info). They have these types and meanings:
observation: This is a NumPy vector or a matrix with observation data.reward: This is the float value of the reward.done: This is a Boolean indicator, which isTruewhen the episode is over.info: This could be anything environment-specific with extra information about the environment. The usual practice is to ignore this value in general RL methods (not taking into account the specific details of the particular environment).
You may have already got the idea of environment usage in an agent's code – in a loop, we call the step() method with an action to perform until this method's done flag becomes True. Then we can call reset() to start over. There is only one piece missing – how we create Env objects in the first place.
Creating an environment
Every environment has a unique name of the EnvironmentName-vN form, where N is the number used to distinguish between different versions of the same environment (when, for example, some bugs get fixed or some other major changes are made). To create an environment, the gym package provides the make(env_name) function, whose only argument is the environment's name in string form.
At the time of writing, Gym version 0.13.1 contains 859 environments with different names. Of course, all of those are not unique environments, as this list includes all versions of an environment. Additionally, the same environment can have different variations in the settings and observations spaces. For example, the Atari game Breakout has these environment names:
- Breakout-v0, Breakout-v4: The original Breakout with a random initial position and direction of the ball
- BreakoutDeterministic-v0, BreakoutDeterministic-v4: Breakout with the same initial placement and speed vector of the ball
- BreakoutNoFrameskip-v0, BreakoutNoFrameskip-v4: Breakout with every frame displayed to the agent
- Breakout-ram-v0, Breakout-ram-v4: Breakout with the observation of the full Atari emulation memory (128 bytes) instead of screen pixels
- Breakout-ramDeterministic-v0, Breakout-ramDeterministic-v4
- Breakout-ramNoFrameskip-v0, Breakout-ramNoFrameskip-v4
In total, there are 12 environments for good old Breakout. In case you've never seen it before, here is a screenshot of its gameplay:
Figure 2.2: The gameplay of Breakout
Even after the removal of such duplicates, Gym 0.13.1 comes with an impressive list of 154 unique environments, which can be divided into several groups:
- Classic control problems: These are toy tasks that are used in optimal control theory and RL papers as benchmarks or demonstrations. They are usually simple, with low-dimension observation and action spaces, but they are useful as quick checks when implementing algorithms. Think about them as the "MNIST for RL" (MNIST is a handwriting digit recognition dataset from Yann LeCun, which you can find at http://yann.lecun.com/exdb/mnist/).
- Atari 2600: These are games from the classic game platform from the 1970s. There are 63 unique games.
- Algorithmic: These are problems that aim to perform small computation tasks, such as copying the observed sequence or adding numbers.
- Board games: These are the games of Go and Hex.
- Box2D: These are environments that use the Box2D physics simulator to learn walking or car control.
- MuJoCo: This is another physics simulator used for several continuous control problems.
- Parameter tuning: This is RL being used to optimize NN parameters.
- Toy text: These are simple grid world text environments.
- PyGame: These are several environments implemented using the PyGame engine.
- Doom: These are nine mini-games implemented on top of ViZDoom.
The full list of environments can be found at https://gym.openai.com/envs or on the wiki page in the project's GitHub repository. An even larger set of environments is available in OpenAI Universe (currently discontinued by OpenAI), which provides general connectors to virtual machines while running Flash and native games, web browsers, and other real-world applications. OpenAI Universe extends the Gym API, but it follows the same design principles and paradigm. You can check it out at https://github.com/openai/universe. We will deal with Universe more closely in Chapter 13, Asynchronous Advantage Actor-Critic, in terms of MiniWoB and browser automation.
Enough theory! Let's now look at a Python session working with one of Gym's environments.
The CartPole session
Let's apply our knowledge and explore one of the simplest RL environments that Gym provides.
$ python
Python 3.7.5 |Anaconda, Inc.| (default, Mar 29 2018, 18:21:58)
[GCC 7.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import gym
>>> e = gym.make('CartPole-v0')
Here, we have imported the gym package and created an environment called CartPole. This environment is from the classic control group and its gist is to control the platform with a stick attached by its bottom part (see the following figure).
The trickiness is that this stick tends to fall right or left and you need to balance it by moving the platform to the right or left on every step.
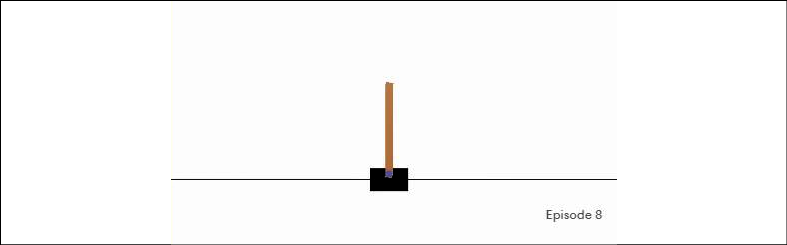
Figure 2.3: The CartPole environment
The observation of this environment is four floating-point numbers containing information about the x coordinate of the stick's center of mass, its speed, its angle to the platform, and its angular speed. Of course, by applying some math and physics knowledge, it won't be complicated to convert these numbers into actions when we need to balance the stick, but our problem is this – how do we learn to balance this system without knowing the exact meaning of the observed numbers and only by getting the reward? The reward in this environment is 1, and it is given on every time step. The episode continues until the stick falls, so to get a more accumulated reward, we need to balance the platform in a way to avoid the stick falling.
This problem may look difficult, but in just two chapters, we will write the algorithm that will easily solve CartPole in minutes, without any idea about what the observed numbers mean. We will do it only by trial and error and using a bit of RL magic.
Let's continue with our session.
>>> obs = e.reset()
>>> obs
array([-0.04937814, -0.0266909 , -0.03681807, -0.00468688])
Here, we reset the environment and obtained the first observation (we always need to reset the newly created environment). As I said, the observation is four numbers, so let's check how we can know this in advance.
>>> e.action_space
Discrete(2)
>>> e.observation_space
Box(4,)
The action_space field is of the Discrete type, so our actions will be just 0 or 1, where 0 means pushing the platform to the left and 1 means to the right. The observation space is of Box(4,), which means a vector of size 4 with values inside the [−inf, inf] interval.
>>> e.step(0)
(array([-0.04991196, -0.22126602, -0.03691181, 0.27615592]), 1.0,
False, {})
Here, we pushed our platform to the left by executing the action 0 and got the tuple of four elements:
- A new observation, which is a new vector of four numbers
- A reward of
1.0 - The
doneflag with valueFalse, which means that the episode is not over yet and we are more or less okay - Extra information about the environment, which is an empty dictionary
Next, we will use the sample() method of the Space class on the action_space and observation_space.
>>> e.action_space.sample()
0
>>> e.action_space.sample()
1
>>> e.observation_space.sample()
array([2.06581792e+00, 6.99371255e+37, 3.76012475e-02,
-5.19578481e+37])
>>> e.observation_space.sample()
array([4.6860966e-01, 1.4645028e+38, 8.6090848e-02, 3.0545910e+37])
This method returned a random sample from the underlying space, which in the case of our Discrete action space means a random number of 0 or 1, and for the observation space means a random vector of four numbers. The random sample of the observation space may not look useful, and this is true, but the sample from the action space could be used when we are not sure how to perform an action. This feature is especially handy because you don't know any RL methods yet, but we still want to play around with the Gym environment. Now that you know enough to implement your first randomly behaving agent for CartPole, let's do it.






















