






















































A typical preprocessed dataset is formally defined as follows:
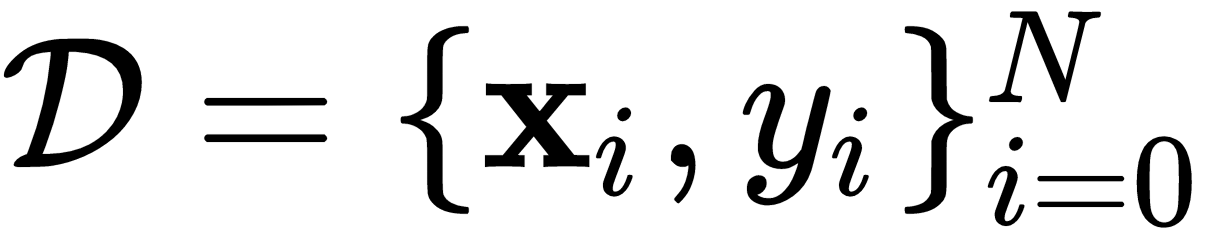
Where y is the desired output corresponding to the input vector x. So, the motivation of ML is to use the data to find linear and non-linear transformations over x using highly complex tensor (vector) multiplications and additions, or to simply find ways to measure similarities or distances among data points, with the ultimate purpose of predicting y given x.
A common way of thinking about this is that we want to approximate some unknown function over x:

Where w is an unknown vector that facilitates the transformation of x along with b. This formulation is very basic, linear, and is simply an illustration of what a simple learning model would look like. In this simple case, the ML algorithms revolve around finding the best w and b that yields the closest (if not perfect) approximation to y, the desired output. Very simple algorithms such as the perceptron (Rosenblatt, F. 1958) try different...




