






















































Light me a pixel
Circa 30 years ago, at the nearer end of the wild 90s, the author of these lines spent quite a significant time optimizing code that was supposed to run as fast as possible, consuming the least amount of resources while showing incredible spinning graphics on a screen (there was also scrolling involved, too, and other not relevant calculations).
These applications were called demos (intros, etc.) and showcased some spectacular graphical effects, backed by a strong mathematical background, and had an in-house developed graphical engine; in those days, there was no DirectX to take all those nasty low-level details off your plate, so all had to be done by hand. Methods for pixel color calculation, color palette setting, vertical retrace of the CRT screen, and flipping of back and front buffers were all coded by hand, using C++ of the 90s and some assembly language routines for the time-critical bits.
One of these methods was putting a pixel on the screen, which, in its simplest incarnation of the method, looked like this:
void putpixel(int x, int y, unsigned char color) {
unsigned char far* vid_mem = (unsigned char far*)0xA0000000L;
vid_mem[(y * 320) + x] = color;
} I’ll spare you the very low-level details such as how segment/offset memory worked 30 years ago. Instead, imagine that the following apply:
- You are using DOS (in 1994, in the wild-far-eastern part of Europe, almost everyone who had a PC used DOS – kudos to the 0.1 percent of early Linux adopters)
- You are also using a special graphic mode, 0x13 (almost all the games used this mode because it allowed 256 colors to be drawn on the screen using the mysterious 320 by 200 resolution, whose origins only IBM engineers from 40 years ago know)
In this case, if you put a byte at the 0xA000 segment and a specific offset, the graphic card will light up a pixel at the specific coordinates, which can be obtained from the preceding formula.
Now, after several iterations of the code, the aforementioned programmer observed that the routine was not that optimal, and it could have benefited from some optimizations.
Please bear with me; the code that was generated by the affordable compiler (the one you just copied from the disk that we mentioned in Chapter 2 of the book) is in the following screenshot:
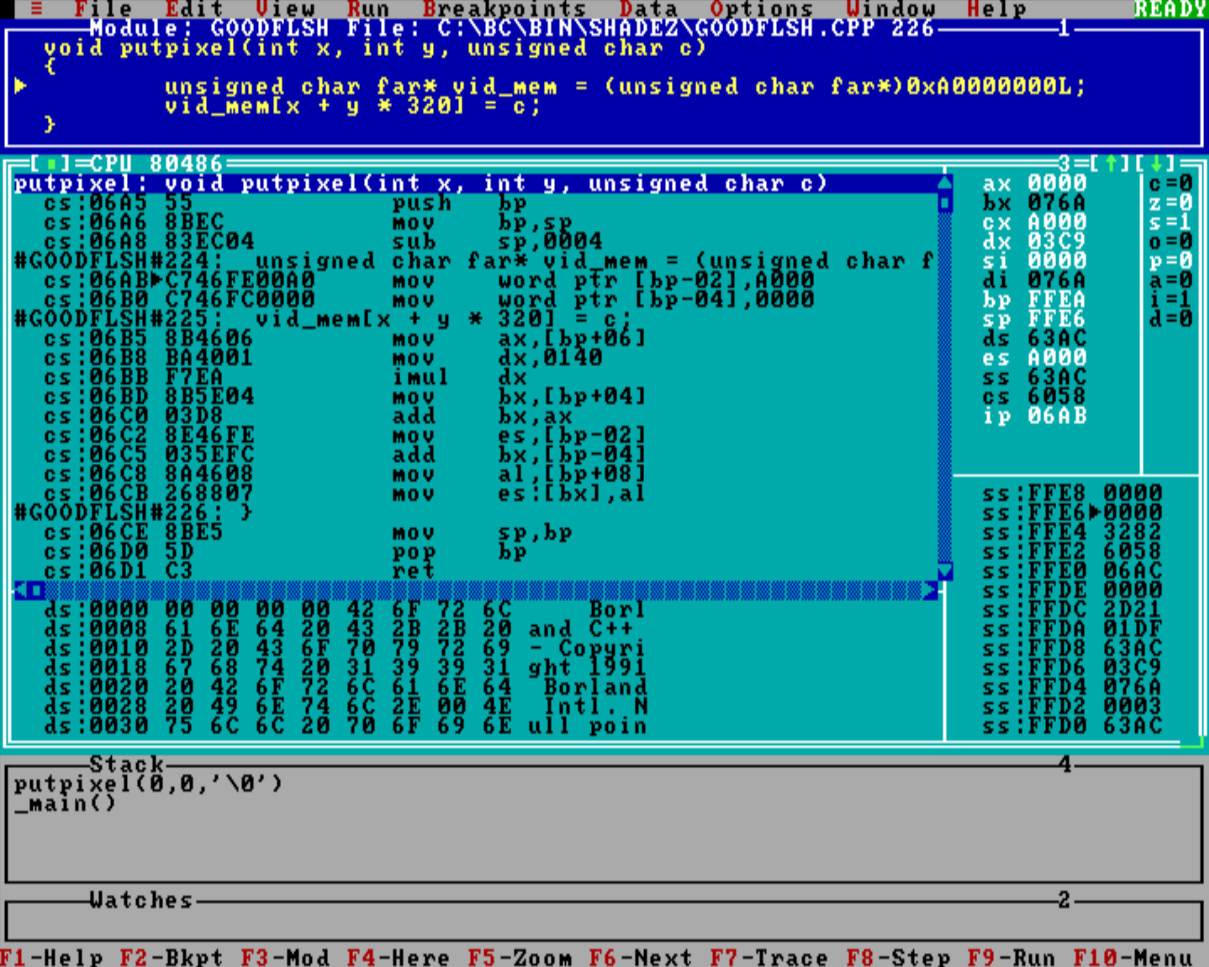
Figure 8.1 – Everyone’s favorite Turbo Debugger from 30 years ago
Now, this looks pretty wild, considering the age of it, but again, we need just a bit of patience, and all the mystery surrounding why it’s here will be revealed. You see, we were discussing how the code generated by the compiler is far from being optimal.
Let’s take a moment to consider this piece of code. After giving it some thought, especially from the perspective of someone familiar with assembly language, which is becoming increasingly rare these days, it might be clear to them that the compiler didn’t struggle as much as we might expect.
The following is the assembly code that the compiler generated for the putpixel routine:
putpixel proc near push bp ; Save the base pointer on the stack mov bp, sp ; Set the BP to the current stack pointer sub sp, 4 ; Reserve 4 bytes for local variables mov word ptr [bp-2], 40960 ; Store 0xA000 at [bp-2] mov word ptr [bp-4], 0 ; Store 0 at [bp-4] mov ax, word ptr [bp+6] ; Load the y-coordinate into AX mov dx, 320 ; Load the screen width into DX imul dx ; Multiply AX (y-coord) by DX (screen width) mov bx, word ptr [bp+4] ; Load the x-coordinate into BX add bx, ax ; Add y*screen width (AX) to BX (x-coord) mov es, word ptr [bp-2] ; Load 0xA000 into ES add bx, word ptr [bp-4] ; Final pixel address in BX mov al, byte ptr [bp+8] ; Load the color value into AL mov byte ptr es:[bx], al ; Light the pixel! mov sp, bp ; Restore the stack pointer pop bp ; Restore the base pointer ret ; Return from the procedure
For those not familiar with the notation, [] represents the data at the address given in the square parentheses, so the parameters are being passed in like this:
- The
xcoordinate of the pixel (from[bp+4]) - The
ycoordinate of the pixel (from[bp+6]) - The color value to set (from
[bp+8])
Indeed, the code as is contains a lot of unnecessary memory access to move data around, when those operations could have been kept in registers, and there is quite a lot of unnecessary access to various memory areas, which can be skipped. The code compiled by the compiler of the day generated code that was easy to debug, but which could have been written much neater. Compilers today generate the same kind of code, having a very similar performance, when compiling in Debug mode but once you switch them to optimized Release mode, they will do magic.
Modern CPUs are highly complex beasts; when running in protected mode, they employ various techniques, such as out-of-order execution, instruction pipelining, and other techniques that make really low-level performance analysis nowadays quite difficult to nail down properly... but old machines were much simpler! Or just use DOS on a modern computer and you will get the same feeling.
Not considering that protected mode was introduced in the early 80286 processors, DOS simply could not handle it (and still can’t), so it stuck to what it knew best: running programs in real mode. While running in real mode, the processor just executed one instruction after the other, and there even was an instruction table explaining how many cycles each instruction would take1.
After spending a significant amount of time consulting those tables, we came to the conclusion that one imul can take longer than two shifts and an add on a processor of those days (the same conclusion was drawn by several other thousands of programmers all around the world after consulting those tables, but we felt that we must be some kind of local heroes for discovering this feature).
Considering that 320 is a very nice number, as it is the sum of 256 and 64, after several rounds of optimizations, we came up with the following slightly more optimized version for the routine:
void putpixel(int x, int y, unsigned char c) {
asm {
mov ax, 0xA000 // Load 0xA000 (VGA mode 13h) into AX
mov es, ax // Set ES to the video segment (0xA000)
mov dx, y // Load the y-coordinate into DX
mov di, x // Load the x-coordinate into DI
mov bx, y // Copy the y-coordinate into BX
shl dx, 8 // Multiply DX by 256 (left shift by 8 bits)
shl bx, 6 // Multiply BX by 64 (left shift by 6 bits)
add dx, bx // Add those, effectively multiplying y by 320
add di, dx // Add the calculated y to DI (pixel offset)
mov al, c // Load the color value into AL
stosb // Light the pixel
} } It is not the most optimal routine that one can come up with for this purpose, but for our specific requirements, it was more than enough.
A significantly reduced amount of direct memory access (which was considered slow even in the old days), the lengthy multiplication by 320 using imul changed to multiplication by 256 (this is the shift to the left by 8 operations: shl dx,8), and 64 (the same by 6), then a sum, which still adds up to fewer cycles than the power-consuming multiplication.
And thus, the foundation was laid for the myth that if you really want fast code, you have to write it yourself at the lowest possible level.
As an interesting mental exercise, let’s jump forward in time 30 years, skipping several generations of compilers. If we feed the C++ routine as it is to a modern compiler (for our purpose, we have used Clang – the latest at the time of writing was version 18.1 – but using GCC will get also a very similar result, just using a different set of registers), we get the following output:
putpixel(int, int, unsigned char): movzx eax, byte ptr [esp + 12] mov ecx, dword ptr [esp + 4] mov edx, dword ptr [esp + 8] lea edx, [edx + 4*edx] shl edx, 6 mov byte ptr [edx + ecx + 40960], al
This is way shorter than the one we concocted for our purpose and considered optimal targeting the processors from 3 decades ago, but processors have evolved a lot in the last 30 years, and a lot more advanced features have come in, with new commands (some more words about new commands a bit late in this chapter, so stay tuned) and we find it extremely satisfying how compilers’ optimization routines have resolved the multiplication with that nice number, 320.
C++ compilers have evolved significantly over the past few decades, from their humble beginnings as Turbo C++ or Watcom C++, becoming incredibly sophisticated and capable of performing a wide range of optimizations that were previously unimaginable due to mostly hardware constraints because, well... 640 KB should be enough for everyone.
Modern compilers are no longer just simple translators from human-readable code to machine code; they have become complex systems that analyze and transform code in ways that can drastically improve performance and memory usage, taking into consideration some aspects that are all meant to help developers bring out the best of their source.
GCC, Clang, and MSVC all employ advanced optimization techniques such as inlining functions, loop unrolling, constant folding, dead code elimination, and aggressive optimizations that span across entire modules or programs, since, at their stage, they have an overview of the entire application, allowing these high-level optimizations.
On a side note, these compilers also leverage modern hardware features, such as vectorization and parallelism, to generate highly efficient machine code that can target a specific processor. We will soon see how these optimizations fall into place when we present the example in the next section, where we take a mundane task and let our compilers churn through it.
But till we reach that stage, just one more use case from 30 years ago. The subtitle of this chapter is Lower than this you should not get. Certainly, we meant coding at a lower level, not something else, and right now, we will proudly contradict ourselves. Again. Here is the contradiction: in certain situations, you really should get to a level lower than assembly.
If you are familiar with graphic programming, then I suppose you are familiar with the concept of double-buffering and back-buffering. The back buffer is an off-screen buffer (memory area, with the same size as the screen) where all the rendering (drawing of graphics) happens first. When the rendering is done, the back buffer is copied onto the screen in order to show the graphics, the back buffer is cleared, and the rendering restarts. At some time in history, Tom Duff, a Canadian programmer, invented a wonderful piece of ingenious code that was meant to accomplish exactly this task; the name of it is Duff’s device and it has been discussed several times in several forums, and we are not going to discuss it now. Instead, we will show you the “highly optimized” code that we used to copy data from the back buffer to the screen:
void flip(unsigned int source, unsigned int dest) {
asm {
push ds // Save the current value of the DS register
mov ax, dest // Load the destination address into AX
mov es, ax // Copy the value from AX into the ES
mov ax, source // Load the source address into AX
mov ds, ax // Copy the value in AX into the DS
xor si, si // Zero out the SI (source index) register
xor di, di // Zero out the DI (destination index)
mov cx, 64000 // Load 64000 into the CX register
// (this is the number of bytes to copy)
rep movsb // Run the`movsb` instruction 64000
// times (movsb copies bytes from DS:SI to ES:DI)
pop ds // Restore the original value of the DS
} } The preceding trick consists of the rep movsb instruction, which will do the actual copying of bytes (movsb), repeated (rep) 64,000 times, as indicated by the CX register (we all know that 64,000 = 320 x 200; that’s why they are magic numbers).
This code works perfectly given the circumstances. However, there is an opportunity for a tiny bit of optimization; you see, we are using a decent processor – at least, an 80386. Unlike its predecessor, the 80286, which was a pure 16-bit processor, the 80386 is a huge step forward, since it is the first 32-bit x86 processor coming from Intel. So, what we can do is the following: instead of copying 64,000 bytes using rep movsd, we can harvest the opportunities given by our high-end processor and put to use the new 32-bit framework, keywords, and registers. What we do is move 16,000 double words (we all know that a byte is measured as 8 bits, two bytes are called a word, measuring 16 bits, and two words are called a double word, totaling 32 bits) because that is exactly what the new processor has support for: operation on 32-bit values. The newly introduced movsd command does exactly this: copies 4 bytes in one step, so that could be a speed-up of 4 times compared to our older code.
Our anecdotical C++ compiler, introduced at the beginning of this book, is Turbo C++ Lite. Unfortunately for us, Turbo C++ cannot compile code for anything other than processors below 80286, so we are stuck with 16-bit registers and some really inefficient register handling.
And here is where the lowest level of hack anyone can see in C++ code comes in – we simply add the bytes of the rep movsd command as hexadecimal values in the code:
xor di,di mov cx,16000 db 0xF3,0x66,0xA5 //rep movsd pop ds
Nothing is simpler and more eye-watering than seeing this in production code, right? Now, regardless that our compiler cannot compile code for 80386 because it’s stuck in the Stone Age (pretty much like half of the chapter you are reading right now), we can still produce code that runs optimally on your processor. Please don’t do this.
A note on the past
Now, you might ask why we even bother mentioning assembly language in 2024, when the major trends exhaust themselves concerning the widespread adoption of AI-driven development tools, the growth of low-code/no-code platforms, and the continued rise of the Nth iteration of various JavaScript modules that have exactly the same output as the previous one, except that the syntax is different.
Regardless that these are the loudest happenings in the IT world nowadays, assembly language is still not obsolete. It might not get as much focus as everyone’s favorite Rust language (Alex will debate Rust in a later chapter if all goes according to plan), but there are still major business branches where the assembly is a must, and still essential in several hardware environments that require precise control, performance optimization, or direct hardware access, such as the following:
- Embedded systems: Microcontrollers and IoT devices often use assembly for efficient, low-level programming. There isn’t too much power on these small devices; every bit counts.
- Operating system (OS) development: Bootloaders and critical parts of OS kernels require assembly for hardware initialization and management. To achieve this feat, either you work for a large corporation or start your own project. Linux is pretty much accounted for.
- High-performance computing (HPC): Assembly is used for optimizing performance-critical code, particularly in scientific computing or custom hardware (e.g., FPGAs). To pursue this, you must find someone wanting to pay you to pursue this.
- Security and reverse engineering: Analyzing and exploiting binaries often involves understanding and writing assembly. This is the most lucrative of all, and the most realistic way of getting into assembly programming, unfortunately.
- Firmware development: BIOS/UEFI and low-level device drivers are commonly written in assembly for direct hardware interaction. Here, again, you must be on the payroll of a large corporation, although there are a few open source projects too (coreboot, libreboot, or just google free bios to get a decent list).
- Legacy systems: Maintaining older systems or working with retro computing often requires assembly. This is the ideal chance to blend both fun and suffering into one experience.
- Specialized hardware: DSPs and custom CPU architectures may need assembly for specialized, efficient processing.
Please don’t dismiss assembly language just yet. It remains relevant and will continue to be as long as computers exist. For those who are interested in the topic, it has its place. Otherwise, you can stick to standard C++.










