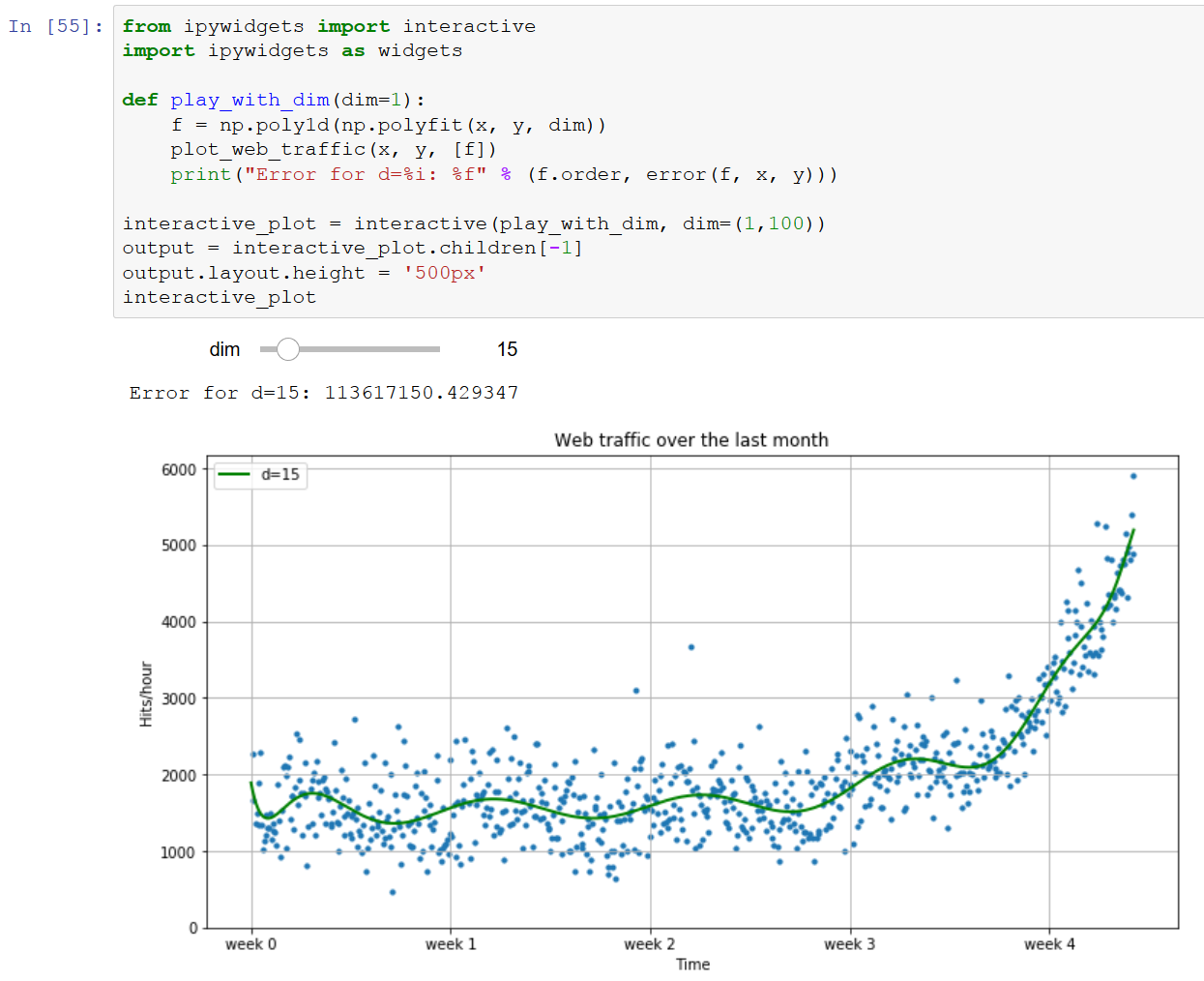
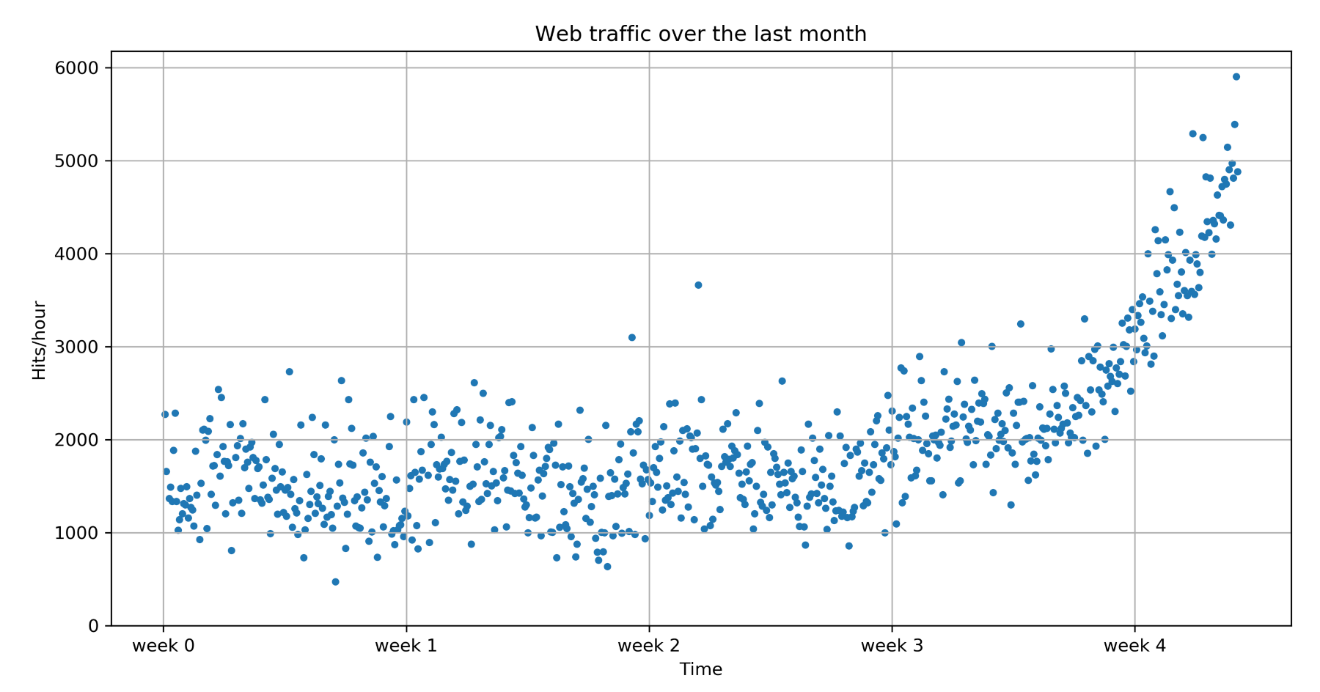
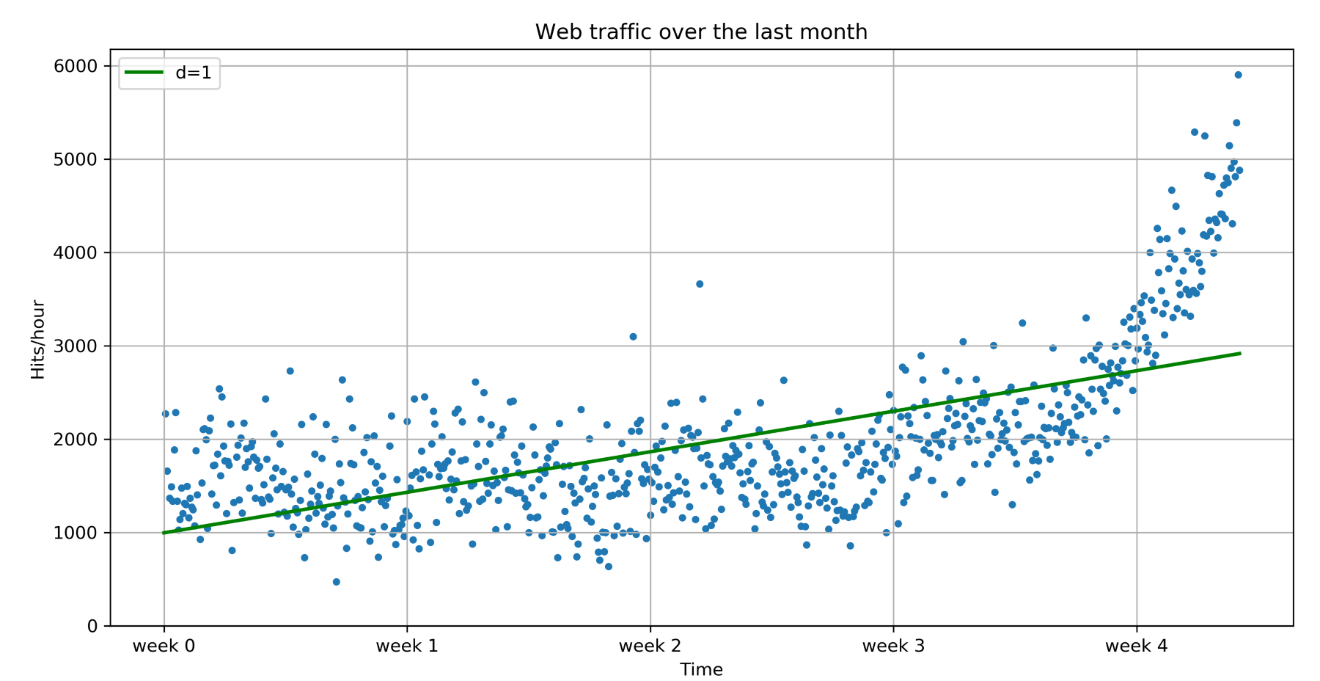
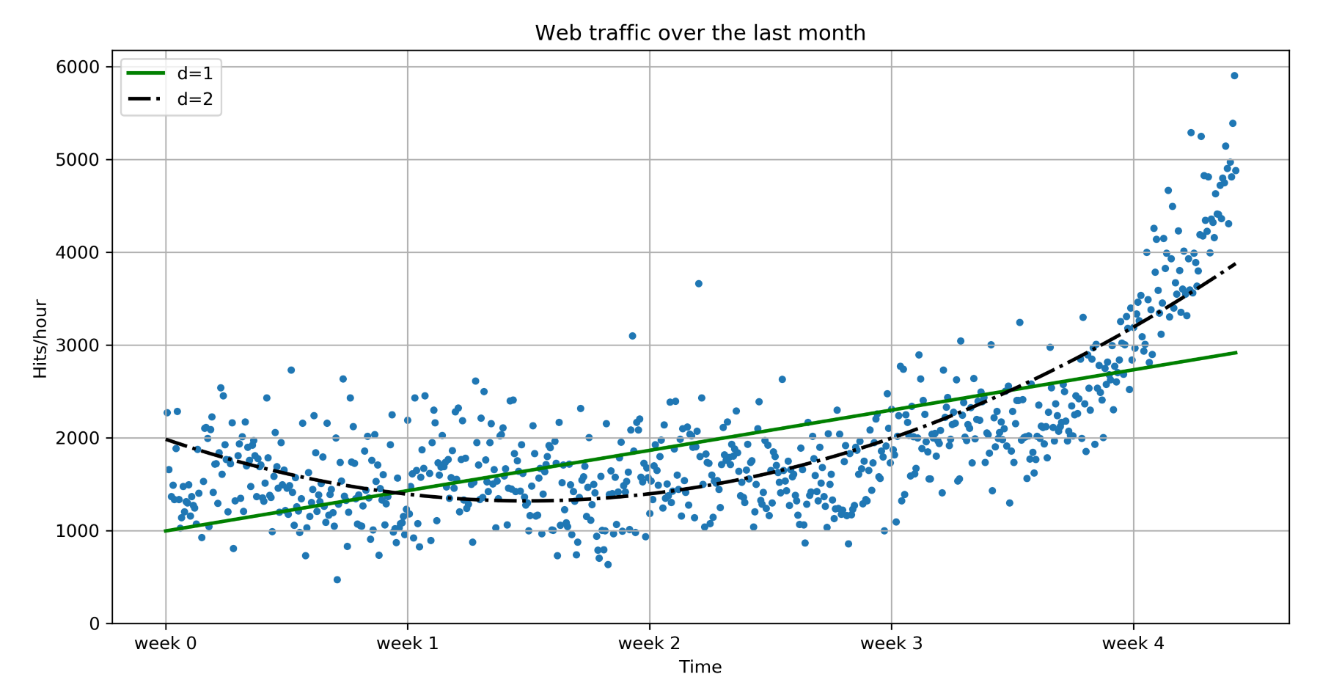
The goal of machine learning is to teach machines (software) to carry out tasks by providing them with a couple of examples (that is, examples of how to do or not do the task). Let's assume that each morning when you turn on your computer, you perform the same task of moving emails around so that only emails belonging to the same topic end up in the same folder. After some time, you might feel bored and think of automating this chore. One way would be to start analyzing your brain and write down all the rules and decisions that your brain processes while you are shuffling your emails. However, this will be quite cumbersome and always imperfect. While you will miss some rules, you will overspecify others. A better and more future-proof way of doing this would be to automate this process by choosing a set of email meta information and body/folder name pairs and letting an algorithm come up with the best rule set. The pairs would be your training data, and the resulting rule set (also called a model) could then be applied to future emails that you have not yet seen. This is machine learning in its simplest form.
Of course, machine learning is not a brand new field in itself. Quite the contrary: its success in recent years can be attributed to the pragmatic way that it uses rock-solid techniques and insights from other successful fields, such as statistics. In these fields, the purpose is for us humans to get insights into the data—for example, by learning more about the underlying patterns and relationships within it. As you read more and more about successful applications of machine learning (you have checked out www.kaggle.com already, haven't you?), you will see that applied statistics is a common field among machine learning experts.
As you will see later, the process of coming up with a decent machine learning approach is never easy. Instead, you will find yourself going back and forth in your analysis, trying out different versions of your input data on diverse sets of machine learning algorithms. It is this exploratory nature that lends itself perfectly to Python. Being an interpreted, high-level programming language, it seems that Python has been designed exactly for this process of trying out different things. What is more, it even does this fast. Sure, it is slower than C or many other natively compiled programming languages. Nevertheless, with the myriad of easy-to-use libraries that are often written in C, you don't have to sacrifice speed for agility.