






















































Introducing distributed tracing
Distributed tracing is a technique that brings structure, correlation and causation to collected telemetry. It defines a special event called span and specifies causal relationships between spans. Spans follow common conventions that are used to visualize and analyze traces.
Span
A span describes an operation such as an incoming or outgoing HTTP request, a database call, an expensive I/O call, or any other interesting call. It has just enough structure to represent anything and still be useful. Here are the most important span properties:
- The span’s name should describe the operation type in human-readable format, have low cardinality, and be human-readable.
- The span’s start time and duration.
- The status indicates success, failure, or no status.
- The span kind distinguishes the client, server, and internal calls, or the producer and consumer for async scenarios.
- Attributes (also known as tags or annotations) describe specific operations.
- Span context identifies spans and is propagated everywhere, enabling correlation. A parent span identifier is also included on child spans for causation.
- Events provide additional information about operations within a span.
- Links connect traces and spans when parent-child relationships don’t work – for example, for batching scenarios.
Note
In .NET, the tracing span is represented by System.Diagnostics.Activity. The System.Span class is not related to distributed tracing.
Relationships between spans
A span is a unit of tracing, and to trace more complex operations, we need multiple spans.
For example, a user may attempt to get an image and send a request to the service. The image is not cached, and the service requests it from the cold storage (as shown in Figure 1.1):
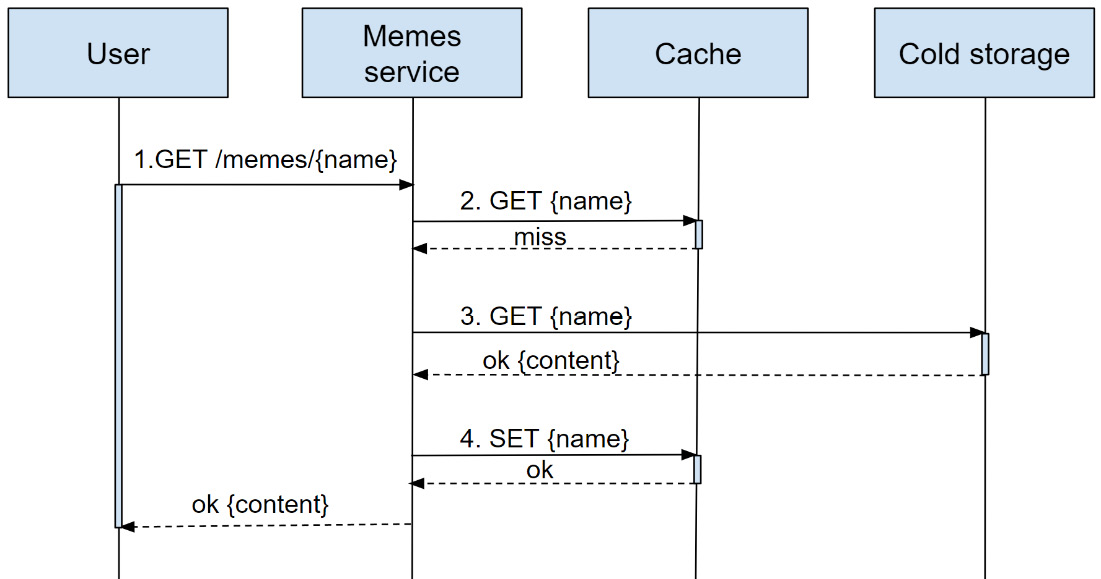
Figure 1.1 – A GET image request flow
To make this operation debuggable, we should report multiple spans:
- The incoming request
- The attempt to get the image from the cache
- Image retrieval from the cold storage
- Caching the image
These spans form a trace – a set of related spans fully describing a logical end-to-end operation sharing the same trace-id. Within the trace, each span is identified by span-id. Spans include a pointer to a parent span – it’s just their parent’s span-id.
trace-id, span-id, and parent-span-id allow us to not only correlate spans but also record relationships between them. For example, in Figure 1.2, we can see that Redis GET, SETEX, and HTTP GET spans are siblings and the incoming request is their parent:

Figure 1.2 – Trace visualization showing relationships between spans
Spans can have more complicated relationships, which we’ll talk about later in Chapter 6, Tracing Your Code.
Span context (aka trace-id and span-id) enables even more interesting cross-signal scenarios. For example, you can stamp parent span context on logs (spoiler: just configure ILogger to do it) and you can correlate logs to traces. For example, if you use ConsoleProvider, you will see something like this:

Figure 1.3 – Logs include span context and can be correlated to other signals
You could also link metrics to traces using exemplars – metric metadata containing the trace context of operations that contributed to a recorded measurement. For instance, you can check examples of spans that correspond to the long tail of your latency distribution.
Attributes
Span attributes are a property bag that contains details about the operation.
Span attributes should describe this specific operation well enough to understand what happened. OpenTelemetry semantic conventions specify attributes for popular technologies to help with this, which we’ll talk about in the Ensuring consistency and structure section later in this chapter.
For example, an incoming HTTP request is identified with at least the following attributes: the HTTP method, path, query, API route, and status code:
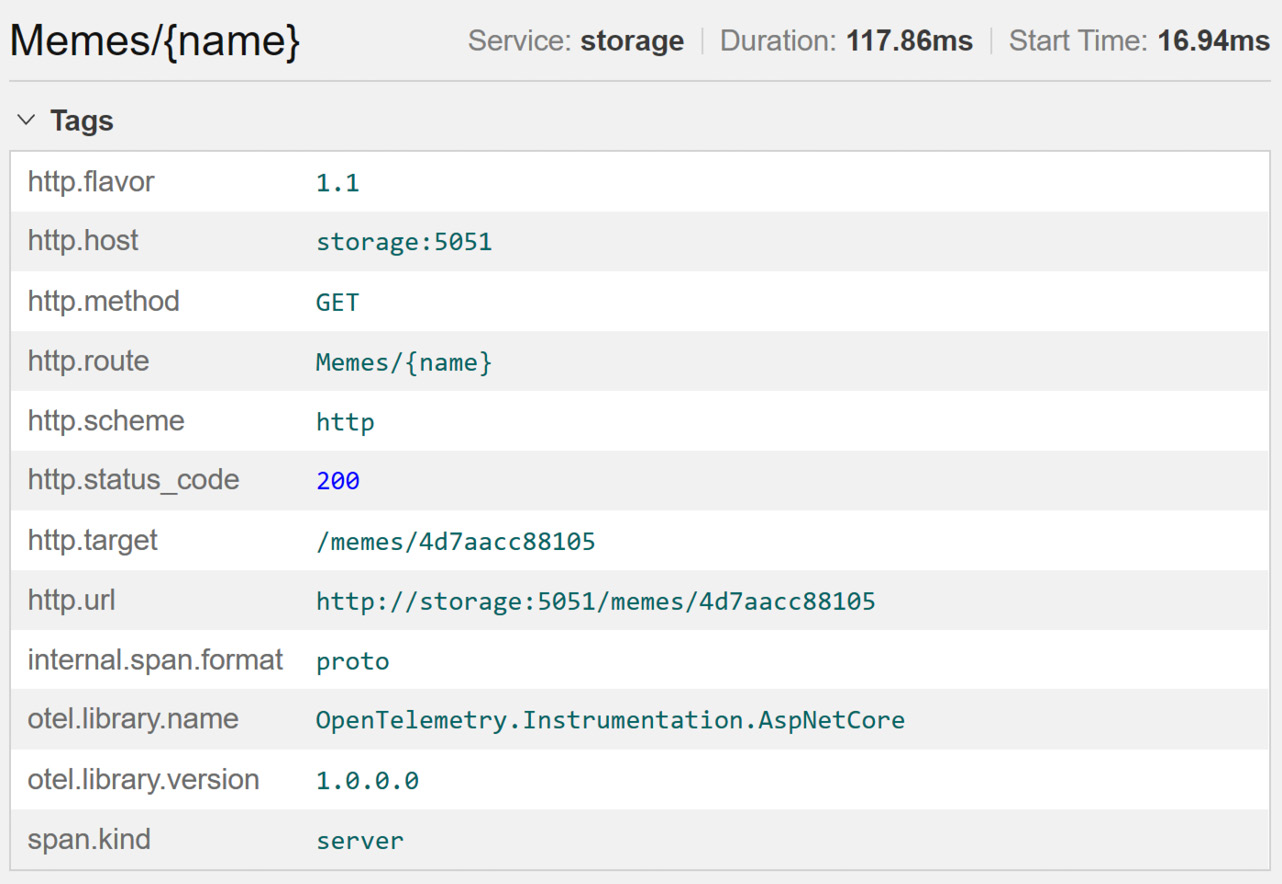
Figure 1.4 – The HTTP server span attributes
Instrumentation points
So, we have defined a span and its properties, but when should we create spans? Which attributes should we put on them? While there is no strict standard to follow, here’s the rule of thumb:
Create a new span for every incoming and outgoing network call and use standard attributes for the protocol or technology whenever available.
This is what we’ve done previously with the memes example, and it allows us to see what happened on the service boundaries and detect common problems: dependency issues, status, latency, and errors on each service. This also allows us to correlate logs, events, and anything else we collect. Plus, observability backends are aware of HTTP semantics and will know how to interpret and visualize your spans.
There are exceptions to this rule, such as socket calls, where requests could be too small to be instrumented. In other cases, you might still be rightfully concerned with verbosity and the volume of generated data – we’ll see how to control it with sampling in Chapter 5, Configuration and Control Plane.
Tracing – building blocks
Now that you are familiar with the core concepts of tracing and its methodology, let’s talk about implementation. We need a set of convenient APIs to create and enrich spans and pass context around. Historically, every Application Performance Monitoring (APM) tool had its own SDKs to collect telemetry with their own APIs. Changing the APM vendor meant rewriting all your instrumentation code.
OpenTelemetry solves this problem – it’s a cross-language telemetry platform for tracing, metrics, events, and logs that unifies telemetry collection. Most of the APM tools, log management, and observability backends support OpenTelemetry, so you can change vendors without rewriting any instrumentation code.
.NET tracing implementation conforms to the OpenTelemetry API specification, and in this book, .NET tracing APIs and OpenTelemetry APIs are used interchangeably. We’ll talk about the difference between them in Chapter 6, Tracing Your Code.
Even though OpenTelemetry primitives are baked into .NET and the instrumentation code does not depend on them, to collect telemetry from the application, we still need to add the OpenTelemetry SDK, which has everything we need to configure a collection and an exporter. You might as well write your own solution compatible with .NET tracing APIs.
OpenTelemetry became an industry standard for tracing and beyond; it’s available in multiple languages, and in addition to a unified collection of APIs it provides configurable SDKs and a standard wire format for the telemetry – OpenTelemetry protocol (OTLP). You can send telemetry to any compatible vendor, either by adding a specific exporter or, if the backend supports OTLP, by configuring the vendor’s endpoint.
As shown in Figure 1.5, the application configures the OpenTelemetry SDK to export telemetry to the observability backend. Application code, .NET libraries, and various instrumentations use .NET tracing APIs to create spans, which the OpenTelemetry SDK listens to, processes, and forwards to an exporter.
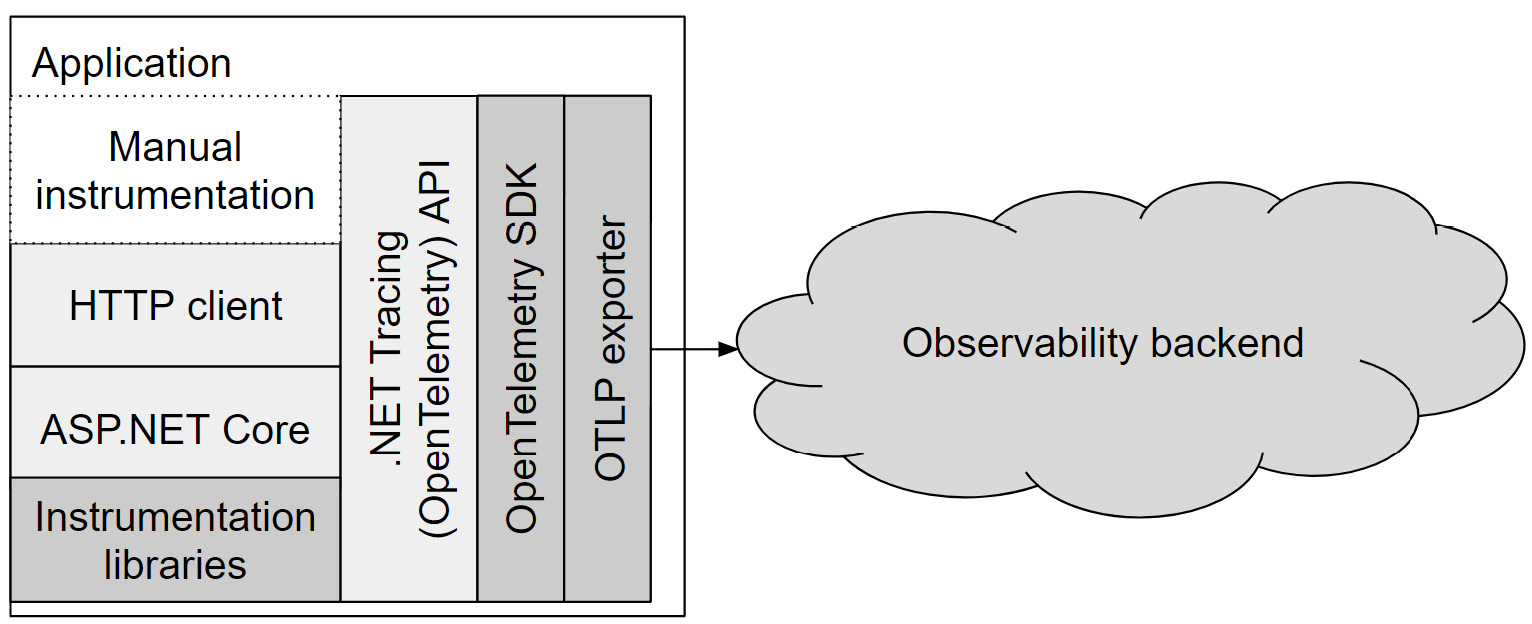
Figure 1.5 – Tracing building blocks
So, OpenTelemetry decouples instrumentation code from the observability vendor, but it does much more than that. Now, different applications can share instrumentation libraries and observability vendors have unified and structured telemetry on top of which they can build rich experiences.
Instrumentation
Historically, all APM vendors had to instrument popular libraries: HTTP clients, web frameworks, Entity Framework, SQL clients, Redis client libraries, RabbitMQ, cloud providers’ SDKs, and so on. That did not scale well. But with .NET tracing APIs and OpenTelemetry semantics, instrumentation became common for all vendors. You can find a growing list of shared community instrumentations in the OpenTelemetry Contrib repo: https://github.com/open-telemetry/opentelemetry-dotnet-contrib.
Moreover, since OpenTelemetry is a vendor-neutral standard and baked into .NET, it’s now possible for libraries to implement native instrumentation – HTTP and gRPC clients, ASP.NET Core, and several other libraries support it.
Even with native tracing support, it’s off by default – you need to install and register specific instrumentation (which we’ll cover in Chapter 2, Native Monitoring in .NET). Otherwise, tracing code does nothing and, thus, does not add any performance overhead.
Backends
The observability backend (aka monitoring, APM tool, and log management system) is a set of tools responsible for ingestion, storage, indexing, visualization, querying, and probably other things that help you monitor your system, investigate issues, and analyze performance.
Observability vendors build these tools and provide rich user experiences to help you use traces along with other signals.
Collecting traces for common libraries became easy with the OpenTelemetry ecosystem. As you’ll see in Chapter 2, Native Monitoring in .NET, most of it can be done automatically with just a few lines of code at startup. But how do we use them?
While you can send spans to stdout and store them on the filesystem, this would not leverage all tracing benefits. Traces can be huge, but even when they are small, grepping them is not convenient.
Tracing visualizations (such as a Gantt chart, trace viewer, or trace timeline) is one of the common features tracing providers have. Figure 1.6 shows a trace timeline in Jaeger – an open source distributed tracing platform:
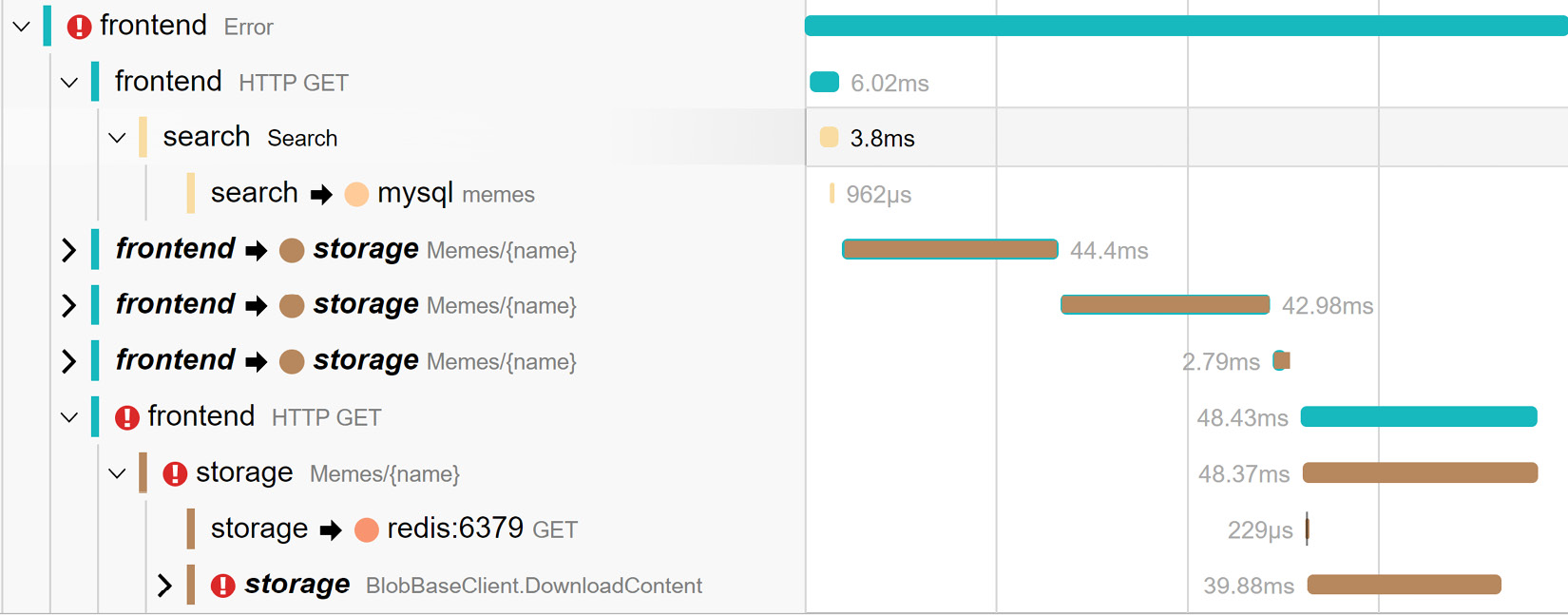
Figure 1.6 – Trace visualization in Jaeger with errors marked with exclamation point
While it may take a while to find an error log, the visualization shows what’s important – where failures are, latency, and a sequence of steps. As we can see in Figure 1.6, the frontend call failed because of failure on the storage side, which we can further drill into.
However, we can also see that the frontend made four consecutive calls into storage, which potentially could be done in parallel to speed things up.
Another common feature is filtering or querying by any of the span properties such as name, trace-id, span-id, parent-id, name, attribute name, status, timestamp, duration, or anything else. An example of such a query is shown in Figure 1.7:
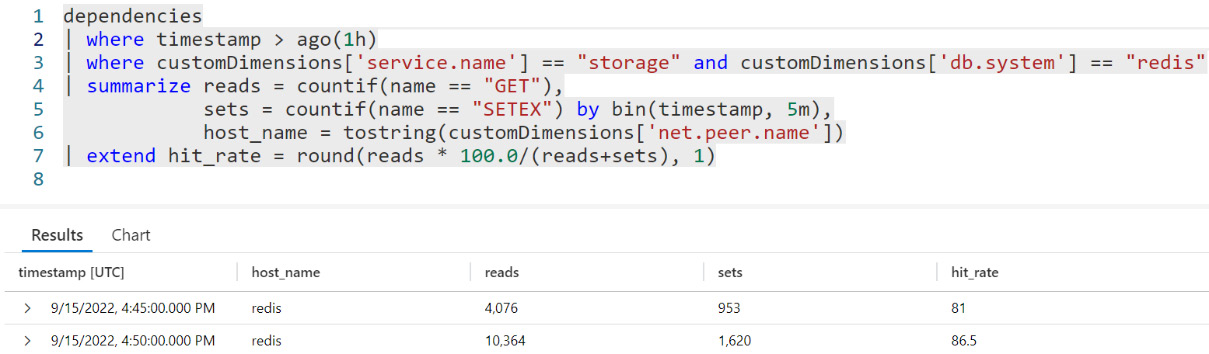
Figure 1.7 – A custom Azure Monitor query that calculates the Redis hit rate
For example, we don’t report a metric for the cache hit rate, but we can estimate it from traces. While they’re not precise because of sampling and might be more expensive to query than metrics, we can still do it ad hoc, especially when we investigate specific failures.
Since traces, metrics, and logs are correlated, you will fully leverage observability capabilities if your vendor supports multiple signals or integrates well with other tools.


